
Trainium3是亚马逊AWS于2025年12月re:Invent大会发布的第四代自研AI芯片,也是其首款采用3nm制程的产品。它的核心目标很明确:在英伟达GPU主导的市场中,为大模型训练与推理提供高性价比、高能效的定制化算力方案。
不同于通用GPU,这款芯片专为生成式AI、多模态模型、强化学习等场景设计,聚焦于优化“训练+推理”的全生命周期。它已成为Anthropic “Project Rainier”等超级项目的核心算力支撑,全球部署总量正在快速逼近百万级规模。
借助台积电3nm先进制程,单芯片FP8算力达到了2.52 PFLOPs,相较上一代Trainium2实现了4.4倍的原始性能跃升。同时,其性能功耗比提升了4倍,能源效率优化了40%。
基于新一代的Neuron Fabric互联技术,单台Trn3 UltraServer能够集成多达144颗芯片,聚合算力高达362 FP8 PFLOPs,这相当于144台传统服务器的算力总和。
通过EC2 UltraClusters 3.0架构,支持从单台服务器无缝扩展至拥有100万颗芯片的超级集群,规模较上一代提升了整整10倍,旨在为超大规模AI项目提供无瓶颈的算力支撑。许多同行在云栈社区的智能 & 数据 & 云板块讨论类似大规模集群的构建经验时,也特别关注这类弹性扩展能力。
1. Scorpio X 赋能,基于 PCIe6+AEC 完成 Scale-up 扩展
*基础构建单元:Trainium3 NL722**
-
计算托盘 *36个:
- Trainium3 XPU 144颗(72颗/机架 2)
- Graviton CPU(1颗 / 计算托盘)
- Scorpio X 32/64/128 通道 PCIe 6.0交换芯片,用于同一板上4颗Tr3互联,按通道数分别需要配置8/4/2颗。
-
交换托盘 *20个:
- Scorpio X 320通道 PCIe 6.0交换芯片 * 40颗。
Scale-up组网逻辑与AEC线缆需求规模
- 端口资源:单颗Trainium3芯片配置160个NeuronLink4端口连接PCIe 6.0通道,其中包括144个活跃端口,以及16个冗余端口。
- 组网划分:
- PCB:每颗Tr3分配64个NeuronLink4端口,通过板上Scorpio X交换芯片与同托盘的另外3颗Tr3直接互联,无需外部线缆。
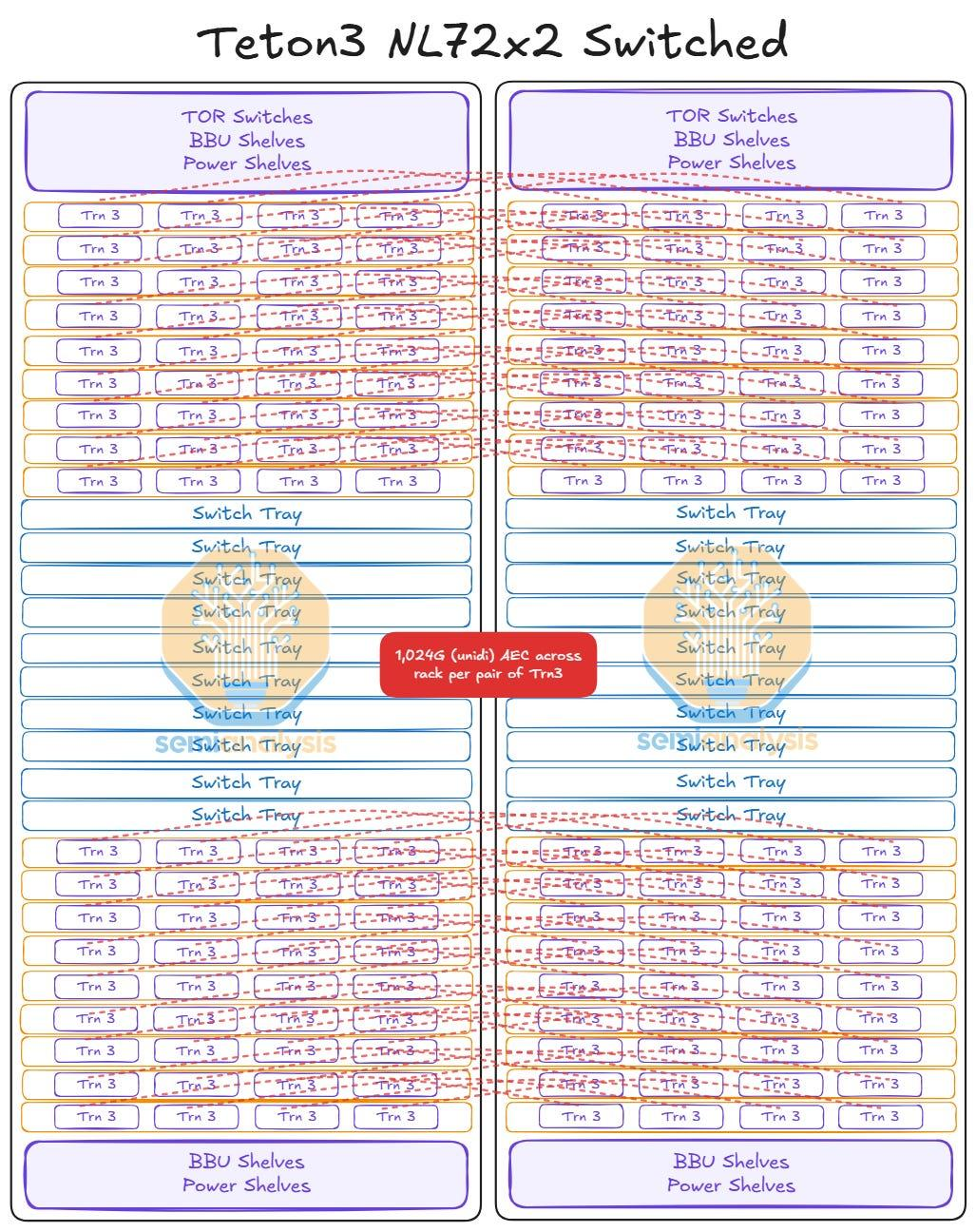
- 背板:每颗Tr3分配80个端口,经由背板连接器及AEC铜缆接入交换托盘。整机柜144颗Tr3 * 80通道 = 11520个PCIe6通道,对应180根64端口PCIe AEC铜缆。
- 跨机架:每颗Tr3分配16个端口,经由板上配置的OSFP-XD端口及AEC铜缆接入邻机架的交换托盘。整机柜144颗Tr3 * 16通道 = 2304个PCIe6通道,对应36根64端口PCIe AEC铜缆。
2. ENA/EFA双网分工,高基数低速率交换机支撑Scale-out
AWS Scale-out组网核心特点
硬件配置与层级互联
-
Nitro-v6网卡配置
- 东西向EFA后端网络:每2颗Trainium3共享1个400G Nitro-v6网卡。
- 南北向ENA前端网络:每1颗Graviton CPU对应1个400G Nitro-v6网卡。
-
Tr3及Graviton与ToR的互联
- Trainium3:通过带Gearbox的400G Y型AEC铜缆(56G SerDes转为112G),单网卡以2条200G链路连接至NL72*2配置的双ToR交换机,以实现冗余。
- CPU:通过直连AEC/DAC线缆,连接至NL72*2配置的双ToR交换机。
-
Leaf/Spine组网
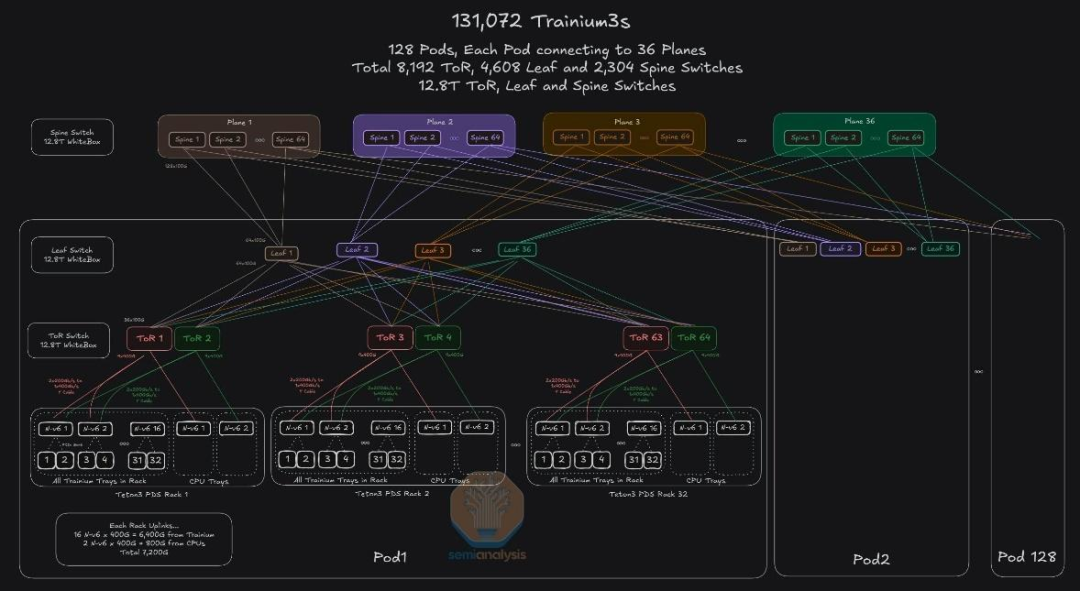
- 采用标准的Clos拓扑结构:8192台ToR交换机(12.8T)上行连接4608台Leaf交换机(12.8T),后者进一步上行连接至2304台Spine交换机(12.8T)。层级间按无阻塞规则进行互联,并通过划分36个平面来优化数据传输路径。这种复杂的网络拓扑设计是支撑超大规模AI训练集群稳定运行的关键。
AWS已经披露了下一代Trainium4芯片的开发进展,其核心亮点之一是支持英伟达的NVLink Fusion高速互连技术。这意味着Trainium4未来能够与英伟达GPU实现无缝协同工作。这一设计允许客户在MGX机架中混合部署Trainium4服务器与英伟达GPU,在保留Trainium系列成本优势的同时,还能兼容基于CUDA生态构建的现有应用程序,从而形成“高性价比算力+成熟生态”的混合架构。这对于破解客户因生态迁移难度而产生的顾虑,可能是一个有效的策略,也体现了在人工智能基础设施领域,多元化技术路线的探索正在加速。 |  发表于 2026-3-2 06:40:50
|
查看: 230|
回复: 0
发表于 2026-3-2 06:40:50
|
查看: 230|
回复: 0
