日常工作中,Pod出现异常情况可以说是家常便饭,尤其是在系统项目中首次部署某个服务时经常遇到。一旦稳定运行之后,Pod状态通常就不会有太大问题。
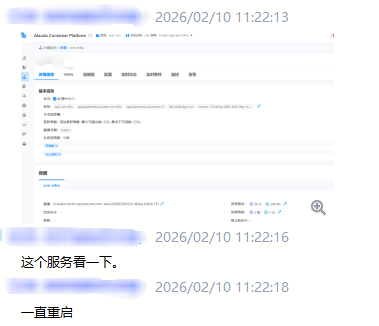
Pod稳定运行后,如果不做任何运维变更操作,最常见的异常之一就是OOM(内存不足)。
基于以上背景,我们今天就来深入聊聊“Pod出现异常了,如何排查和定位?”,希望能帮助你在项目首次部署时更加游刃有余。
在开始介绍之前,可以阅读一篇网上看到的文章《解读 K8s Pod 的13种典型异常》,里面针对Pod的异常解读得非常详细。文章链接:https://segmentfault.com/a/1190000043165703
文章中列举的13种异常比较多,不需要现在就逐字逐句理解。当我们实际遇到某个异常时,再去针对性查阅即可。
3个指令搞定Pod异常定位
Pod出现异常时,我们的定位方法其实并不复杂。直接使用 kubectl 提供的故障排查子命令,基本就能定位到Pod的所有故障问题。下图红色框出的命令就是我们接下来要重点介绍的。
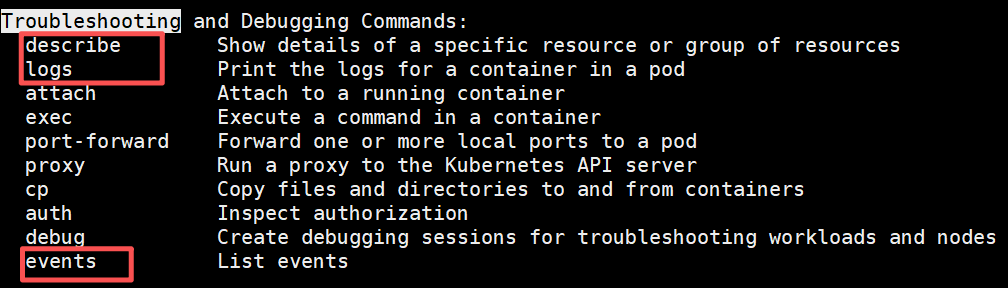
kubectl describe:查看资源详细状态和异常原因。kubectl logs:查看应用日志,定位运行错误。kubectl events:查看集群事件,定位调度或运行异常。
1)kubectl describe 命令
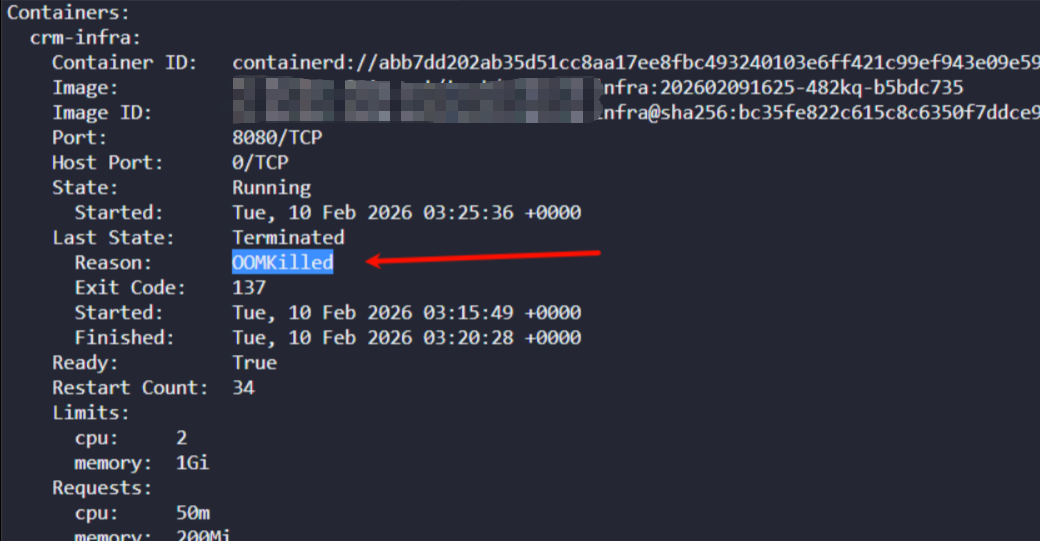
这里重点介绍一下 kubectl describe 命令,因为它能获取Pod的完整生命周期状态,包括异常状态。非常关键的是,该命令会记录当前和上一次的状态,如果是异常状态还会记录对应的原因。掌握这一点,我们就能很好地判断Pod的异常了。
举个例子:
我给一个Nginx服务的Deployment添加了一个存活探针(Liveness Probe),并故意将其配置为检查81端口,以此来模拟一个故障。该Pod经过一段时间反复重启后,就会出现问题。
root@k8s-master01-192-168-1-28:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-test-645d57fd4c-tjjq9 0/1 CrashLoopBackOff 13 (96s ago) 30m
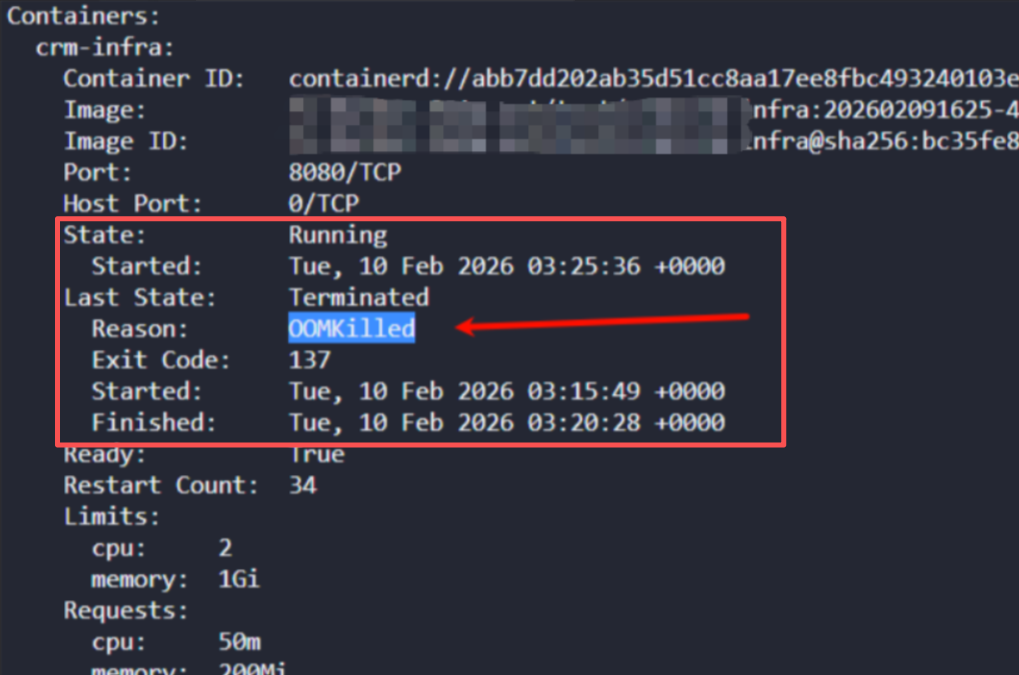
通过 kubectl describe pod 命令我们可以查看Pod的详情。首先关注State字段,可以看到当前容器的等待原因为 CrashLoopBackOff。
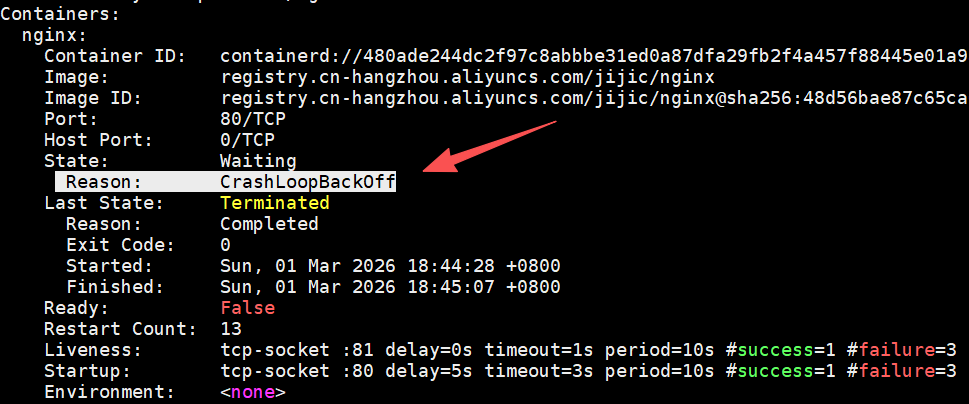
仅凭上述的Reason,我们还无法准确判断问题根源。这时需要查看 describe 输出中更具体的Message信息。在事件(Events)部分,可以看到明确提示是Liveness存活探针检查失败。
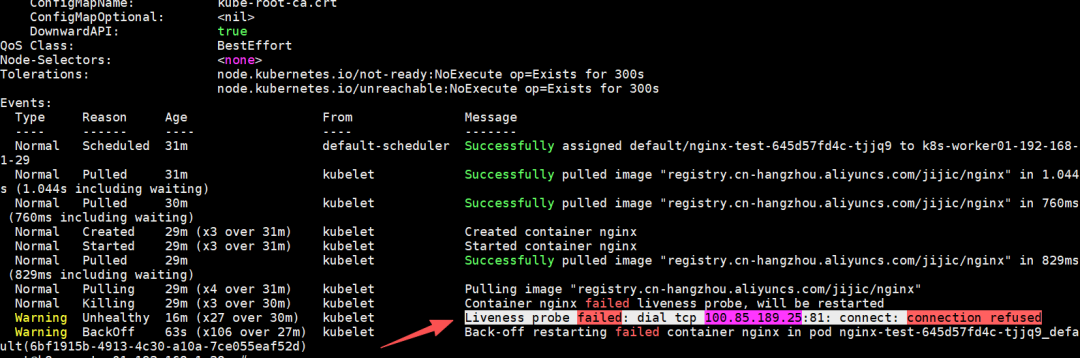
2)kubectl events 命令
kubectl events 命令可以追踪Pod的创建过程、异常发生过程,并记录异常信息。因此,它通常与 kubectl describe 结合使用,相互印证,提供更全面的诊断视角。
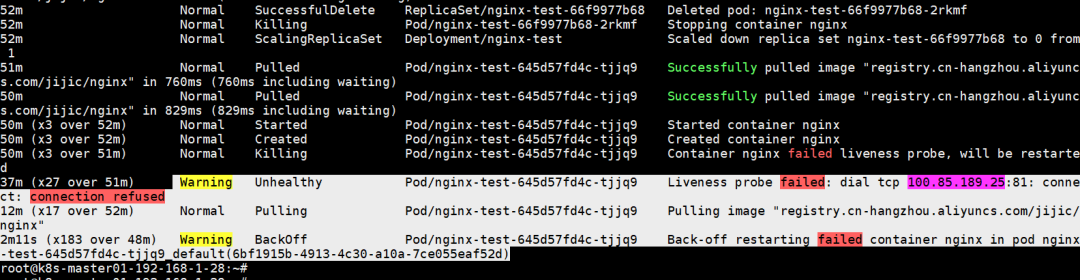
3)kubectl logs 命令
kubectl logs 命令主要用于定位业务服务本身的问题,而非Pod资源的问题。这一点一定要区分清楚。
例如,即使Pod每次重启后的状态都是Running,但通过 kubectl logs 查看日志时,发现业务应用内部有报错信息。这时问题的根源就是业务代码或配置本身,而不再是Kubernetes Pod层面的资源问题了。
掌握以上三个命令,足以应对大多数 Pod 的异常定位场景。对于刚开始接触Kubernetes的朋友来说,这套方法非常实用,是日常 运维 工作的基础。希望这些分享能对你有所帮助。如果你对云原生技术有更多兴趣,欢迎到 云栈社区 与大家一起交流学习。 |  发表于 2026-3-3 08:35:26
|
查看: 200|
回复: 0
发表于 2026-3-3 08:35:26
|
查看: 200|
回复: 0
