
AI智能体已经到来,并且正在被部署在后果差异巨大的场景中,从简单的邮件分拣到潜在的网络间谍活动[1]。理解这条从低风险到高风险的光谱,对于安全部署AI至关重要。然而,我们对人们在现实世界中究竟如何使用智能体,仍然知之甚少。
为了回答这个问题,Anthropic的研究人员运用隐私保护工具[2],分析了数百万条来自Claude Code(其自家的编码智能体)和公有API的人类与智能体交互数据。这项实证研究的核心目标是探究:人们在实际操作中赋予了智能体多少自主权?这种自主性会如何随着用户经验的积累而变化?智能体主要在哪些领域运行?它们执行的动作到底有多大风险?
核心发现
- Claude Code的自主连续工作时间正在延长。在表现最持久的会话中,Claude Code在停止前能够连续工作的时间,在三个月内几乎翻了一番,从不到25分钟增加到超过45分钟[3]。这一增长跨越了多个模型版本的发布,过程相对平滑,表明这不仅仅是模型能力提升的结果,也意味着现有模型在实践中被允许发挥的自主性,可能仍低于其能力上限。
- Claude Code的资深用户更常开启自动批准,但也更常打断。随着用户使用经验的增长,他们倾向于减少对每个动作的逐条审核,转而让Claude自主运行,仅在必要时才介入。在新用户中,大约只有20%的会话会启用完全自动批准;而随着经验积累,这一比例会上升到40%以上[3]。
- Claude Code主动暂停以请求澄清的频率,高于人类主动打断它的频率。除了人类监督,智能体主动中止也是已部署系统中一种重要的安全机制。在最复杂的任务上,Claude Code为寻求澄清而暂停的频率,是人类打断频率的两倍以上[3]。
- 智能体已进入高风险领域,但尚未形成规模。在Anthropic的公有API上,大多数智能体执行的动作仍然是低风险且可逆的。软件工程占据了近50%的智能体活动,但在医疗、金融和网络安全等领域,也出现了增长中的使用迹象[3]。
下文将详细介绍研究方法与结果,并在最后为模型开发者、产品设计者和政策制定者提供建议。核心结论是:要有效监督智能体,我们需要新的部署后监测基础设施,以及一种帮助人类与AI共同管理自主性与风险的“人-AI协同范式”。
这项研究被视为朝着“用实证方式理解人们如何部署和使用智能体”迈出的第一步。随着智能体的更广泛普及,相关方法将持续迭代,发现也将持续公开。
在真实世界中研究智能体
对智能体进行实证研究充满挑战。首先,“智能体”本身缺乏统一的定义。其次,智能体技术演进极快,去年的先进系统可能还是单会话线程,如今已出现能自主运行数小时的多智能体系统。第三,模型提供商对客户构建的智能体架构,往往只有有限的可见性。
例如,目前还无法可靠地将API上看似独立的请求,关联成同一个完整的“智能体会话”。
面对这些挑战,研究团队是如何开展工作的?
首先,他们采用了一个既有概念基础又可操作的定义:智能体是“配备工具、可执行动作的AI系统”,例如运行代码、调用外部API、向其他智能体发送消息。通过研究智能体使用的工具,可以间接理解它们在现实中做了什么。
接着,团队设计了一组指标,结合了公有API的广泛用法数据与Claude Code的深度会话数据。这两类数据形成了“广度 vs 深度”的互补:
- 公有API:提供了观察数千名客户广泛部署智能体的窗口。研究不在完整架构层面分析,而是在“单次工具调用”层面进行。这允许研究者在多样化的场景中做出稳健的观察。局限性在于,必须孤立地分析每个动作,无法重构这些动作如何串联成长期行为序列。
- Claude Code:情况正好相反。作为Anthropic的自有产品,研究者可以跨请求关联完整的会话,看到端到端的工作流。这对于研究自主性特别有价值,例如智能体在无人干预下能运行多久、什么会触发打断、用户如何随经验增长调整监督策略。但因为它只是一个特定产品,其场景多样性不如API流量。
通过隐私保护基础设施同时使用这两类数据源,研究者得以回答任何单一数据源都难以回答的问题。
Claude Code的自主运行时长正在增长
一个智能体究竟能在无人参与的情况下运行多久?在Claude Code中,可以通过追踪“回合时长”来直接测量:即从Claude开始工作到停止(完成任务、提出问题、或被用户打断)之间经过的时间。
“回合时长”并非完美的自主性代理指标。更强的模型可能更快完成相同工作,子智能体可以并行推进,这都会缩短回合。同时,用户可能会随时间推移让Claude执行更有挑战的任务,这又会延长回合。再加上Claude Code用户群体本身就在快速增长和变化。
研究者无法完全拆解这些因素单独测量;他们测量到的是这些因素交互后的净结果,包括:用户愿意让Claude独立工作的时长、任务难度以及产品本身的持续改进效率。
大多数Claude Code回合都很短。中位回合时长约为45秒,在过去几个月里仅有小幅波动(40–55秒)。实际上,99%分位以下的时长都相当稳定。对于一个快速增长的产品,这很合理:新用户往往经验较少,而数据表明,他们给予Claude的自主性也较低。
更有信息量的是数据分布的尾部。最长的回合最能反映Claude Code最具雄心的用法,也暗示了自主性的走向。从2025年10月到2026年1月,99.9分位的回合时长几乎翻倍,从不到25分钟增长到超过45分钟(图1)。
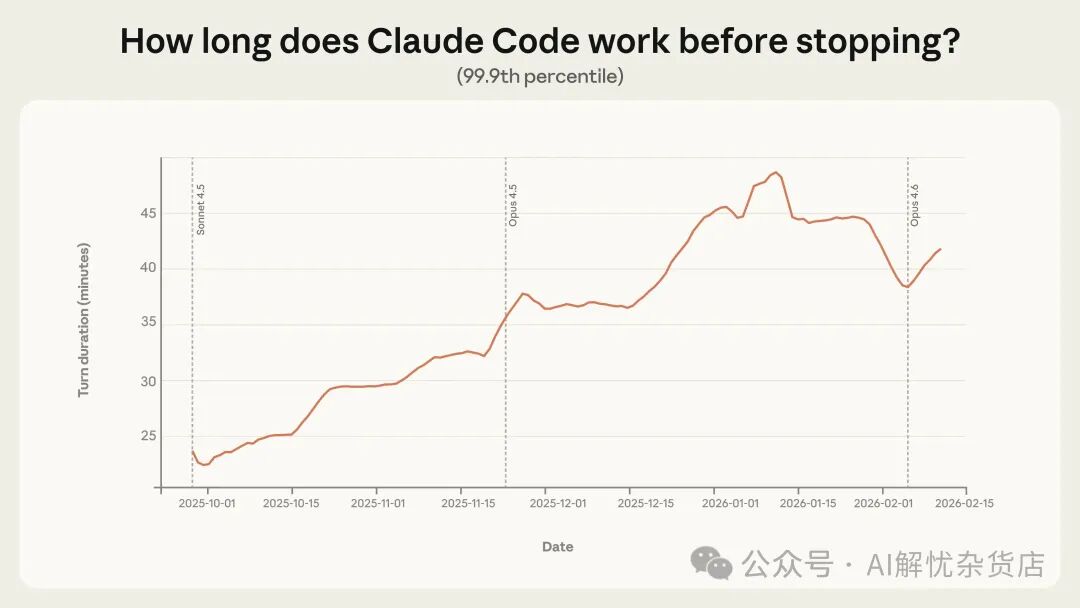
图 1. 交互式 Claude Code 会话中,按 7 天滚动平均计算的 99.9 分位回合时长(Claude 在单回合中持续工作的时间)。99.9 分位从 9 月下旬不到 25 分钟稳步增长到 1 月上旬超过 45 分钟。该分析覆盖全部交互式 Claude Code 使用。
值得注意的是,这一增长跨越模型发布是平滑的。如果自主性完全由模型能力决定,理论上应在每次新模型发布时出现明显跃升。当前的平稳趋势表明,可能是多种因素共同作用的结果:高级用户逐步建立信任、将Claude用于更有挑战的任务,以及产品本身的持续改进。
自1月中旬以来,极端的回合时长有所回落。可能的原因包括:第一,Claude Code用户数在1月至2月中旬期间翻倍[6],更大、更多样化的用户群体会改变数据分布;第二,节后用户带回的项目可能从兴趣探索转向边界更明确的工作任务。最可能的情况是多因素共同影响。
研究者还分析了Anthropic内部对Claude Code的使用情况,以理解“独立性”和“有效性”如何共同演进。从8月到12月,内部用户处理最难任务的成功率翻了一番,同时每个会话的平均人工干预次数从5.4次下降到了3.3次。用户在给予Claude更多自主性的同时,至少在内部场景中,用更少的干预获得了更好的结果。
这两类测量都指向一个显著的“部署过载”:即模型理论上可处理的自主空间,超过了它们在实践中被允许行使的自主空间。
将这些发现与外部能力评估(如METR的“Measuring AI Ability to Complete Long Tasks”[7])对比很有价值。METR评估估计Claude Opus 4.5能在“人类需要近5小时”的任务上达到50%成功率。相比之下,Claude Code的99.9分位回合时长约为42分钟,中位数则更短。但二者不能直接比较。
METR评估测量的是理想化、无人工交互、无真实后果的设置下模型“能做到什么”。而Claude Code的数据反映的是实践中“实际发生了什么”:Claude会主动停下来请求反馈,用户也会主动打断。此外,METR的“五小时”指的是任务对人类而言的难度(完成所需时间),而非模型实际运行时长。
仅靠能力评估或仅靠实践测量都不足以完整刻画智能体自主性;但结合来看,实践中赋予模型的自由度,似乎仍落后于模型可承受的水平。
资深用户更常自动批准,也更常打断
人类会如何随时间调整与智能体的协作方式?研究发现,随着使用经验增加,人们会给予Claude Code更多自主性(图2)。新用户(会话数<50)中约有20%的会话会启用完全自动批准;当会话数达到约750次时,这一比例超过了40%。
这种变化是渐进的,体现了信任的持续积累。需要注意的是,Claude Code默认需要用户手动批准每个动作,因此部分变化也可能源于用户在熟悉Claude能力后,主动将产品配置为更偏好独立执行的模式。
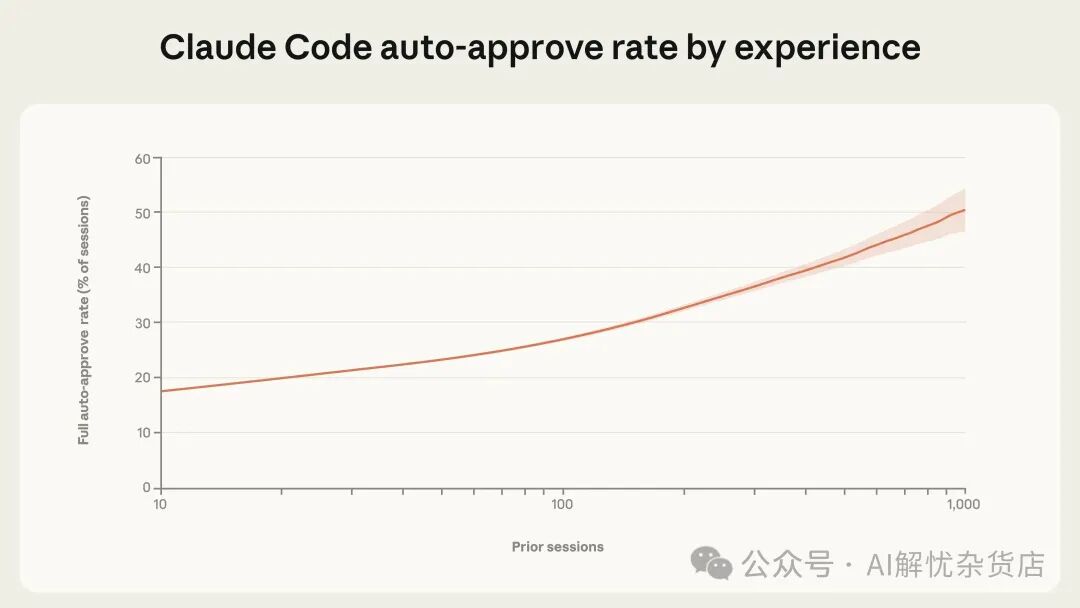
图 2. 按账号资历统计的自动批准率。经验更丰富的用户越来越倾向于让 Claude 无需人工批准直接运行。数据覆盖 2025 年 9 月 19 日后注册用户的全部交互式 Claude Code 使用。曲线与置信区间边界使用 LOWESS 平滑(带宽 0.15)。x 轴为对数刻度。
批准动作只是监督Claude Code的一种方式。用户也可以在Claude工作途中打断并提供反馈。有趣的是,打断率也会随着经验增加而上升。新用户(约10次会话)在5%的回合中会打断Claude,而更资深的用户在约9%的回合中会这样做(图3)。
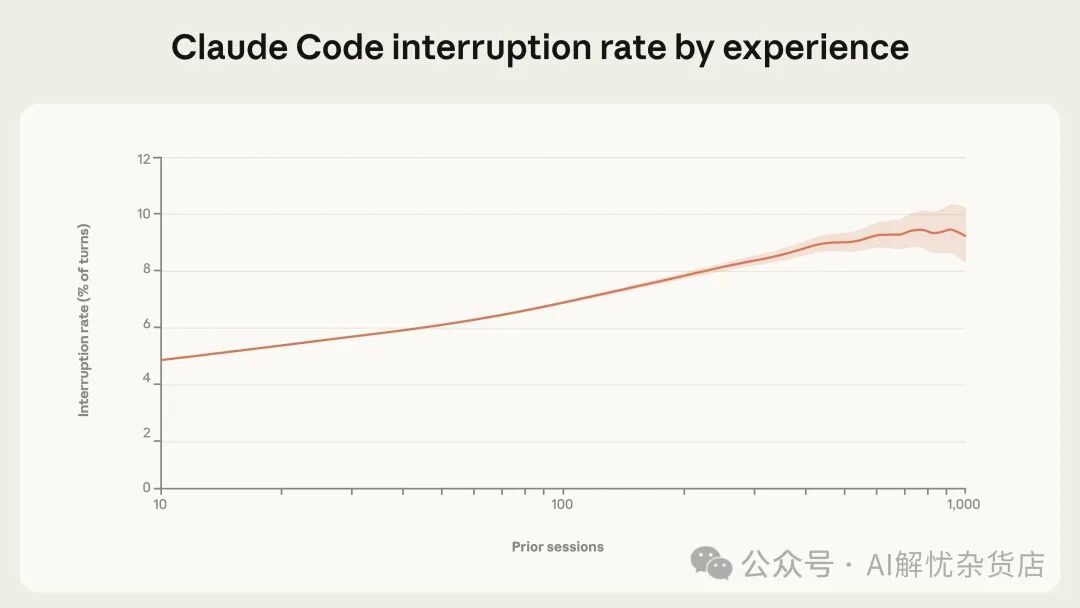
图 3. 按账号资历统计的逐回合打断率。经验用户更常打断 Claude,而不是更少。数据覆盖 2025 年 9 月 19 日后注册用户的全部交互式 Claude Code 使用。阴影区域为 95% Wilson 得分置信区间。曲线与置信区间边界使用 LOWESS 平滑(带宽 0.15)。x 轴为对数刻度。
“自动批准增加”与“打断增加”同时出现,看似矛盾,实则反映了监督策略的转变。新用户更可能先审批每一个动作,因此很少需要中途打断。资深用户则更可能先放手让Claude自主工作,在出现偏差或需要重定向时再介入。
更高的打断率也可能说明资深用户在更积极地监控,并且更擅长判断何时该介入。研究者预计,逐回合打断率最终会在某种稳定的监督风格下趋于平缓;事实上,在最资深的用户中,曲线可能已经开始走平(尽管高会话数下的置信区间变宽,难以确认)。
在公有API上,研究者也观察到了类似模式:在最低复杂度的任务(例如修改一行代码)中,87%的工具调用显示出某种形式的人类参与;而在高复杂度任务(例如自主寻找零日漏洞[8]或编写编译器[9])中,这一比例为67%。这看似反直觉,但有两种可能的解释。
第一,步骤越多,逐步审批就越不现实,因此复杂任务天然地更难实现逐动作监督。第二,Claude Code的数据显示资深用户倾向于给予工具更高的独立性,而复杂任务可能更集中在资深用户群体中。尽管无法在公有API上直接测量用户资历,但总体模式与Claude Code的观察一致。
综合来看,这些结果表明资深用户并非在“放弃监督”。自动批准上升的同时打断也在上升,意味着一种从“事前审批”转向“持续监控与必要时介入”的主动监控模式。
Claude主动澄清暂停,比人类打断更频繁
当然,决定实践中自主性如何展开的,不只有人类。Claude本身也是主动参与者:当不确定如何继续时,它会主动停下来请求澄清。研究发现,任务越复杂,Claude Code请求澄清就越频繁,而且其增长速度超过了人类主动打断(图4)。
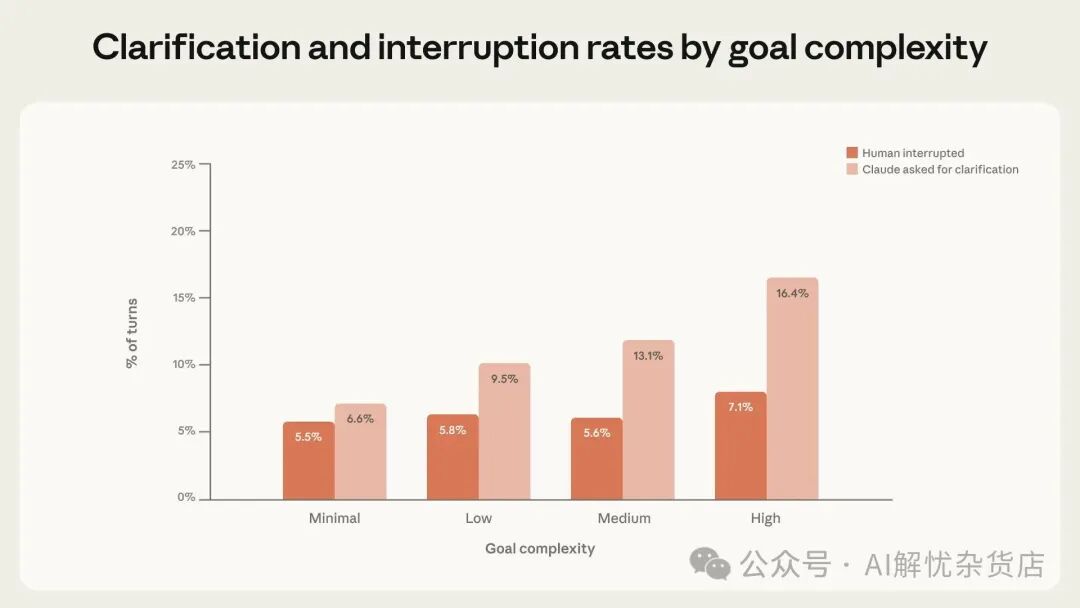
图 4. 按目标复杂度统计,Claude 的澄清提问与人类打断。任务越复杂,Claude 越可能提问,人类也越可能打断;且 Claude 主动停止的增幅更快。所有类别 95% 置信区间 <0.9%,n=50 万交互式 Claude Code 会话。
在最复杂的任务上,Claude Code请求澄清的频率是最低复杂度任务的两倍以上,这表明Claude对其自身的不确定性有一定的校准能力。但也不应过度解读:Claude未必总是在正确的时刻停下,也可能提出不必要的问题,其行为还可能受到“计划模式”[10]等产品功能的影响。
无论如何,随着任务难度增加,Claude越来越倾向于“主动停下咨询人类”,而非完全依赖人类主动介入。
下表展示了Claude Code主动停止与人类打断的常见原因。
Claude Code为什么会停下?
| Claude 为什么会主动停下 |
人类为什么会打断 Claude |
| 向用户呈现多个方案并让用户选择 (35%) |
提供缺失技术背景或纠正 (32%) |
| 收集诊断信息或测试结果 (21%) |
Claude 过慢、卡住或行为过度 (17%) |
| 澄清模糊或不完整请求 (13%) |
已得到足够帮助,可自行继续 (7%) |
| 请求缺失的凭据、令牌或访问权限 (12%) |
希望自己接管下一步(如手测、部署、提交等)(7%) |
| 在采取行动前请求批准或确认 (11%) |
任务中途需求发生变化 (5%) |
表 1. Claude 主动停止与人类打断的常见原因(由 Claude 判定),基于 50 万次人工打断和 50 万次完成回合的交互式 Claude Code 会话样本。部分聚类名称为清晰性做了轻微编辑。
这些结果表明:在已部署的系统中,智能体主动停止本身就是一种重要的监督机制。训练模型识别并处理自身的不确定性,是对权限系统和人工监督等外部保障的补充性安全能力。在Anthropic,团队会训练Claude在面对模糊任务时主动提问,也鼓励其他模型开发者这样做。
智能体已用于高风险领域,但尚未形成规模
人们在用智能体做什么?这些部署的风险有多高?自主性又有多高?风险与自主性之间是否存在权衡?
为了回答这些问题,研究者让Claude对公有API的单次工具调用进行“相对风险”和“相对自主性”的估计,分值范围为1–10。简而言之,风险1表示即使出错也几乎无后果;风险10表示可能造成重大伤害。自主性也按1–10打分:低分表示智能体更像在执行明确的人类指令;高分表示智能体更独立地运行。然后,研究者把相似的动作聚合成簇,并计算各簇的平均风险与平均自主性。
下表展示了在风险与自主性两个维度上的极端簇示例。
高风险或高自主性工具使用簇
| 更高平均风险 |
更高平均自主性 |
| 将 API 密钥外传后门伪装成合法开发功能(风险 6.0,自主性 8.0) |
将权限提升和凭据窃取伪装成合法开发的红队行为(自主性 8.3,风险 3.3) |
| 在实验室搬运金属钠及反应性化学品容器(风险 4.8,自主性 2.9) |
在心跳检查中执行自动化系统健康与运行状态监控(自主性 8.0,风险 1.1) |
| 为请求用户检索并展示患者病历(风险 4.4,自主性 3.2) |
为盈利自主执行加密货币交易(自主性 7.7,风险 2.2) |
| 响应火灾紧急情况并提供消防安全信息(风险 3.6,自主性 5.2) |
自动向参会者发送会议信息提醒(自主性 7.6,风险 1.7) |
| 向线上生产应用部署缺陷修复与补丁(风险 3.6,自主性 4.8) |
监控邮件并向操作员提醒紧急业务消息(自主性 7.5,风险 1.7) |
表 2. 高平均风险或高平均自主性的聚类,基于公有 API 随机抽样的 998,481 次工具调用。
由于对这些智能体的可见性有限,这些动作可能是模拟行为(例如,无法确定Claude发出的金融交易指令是否真实执行;许多“数据外传”很可能只是评估测试)。另外,尽管这类高风险动作在总流量中占比很小,但单次错误的后果仍可能非常严重。
研究发现:80%的工具调用来自“看起来至少具备一种保障机制”的智能体(如权限限制或人工审批要求);73%的调用看起来有人类在环;只有0.8%的动作看起来是不可逆的(例如向客户发送邮件)。
为了可视化风险和自主性的联合分布,研究者将每个聚类按两个维度的均值绘制成散点图(图5)。每个点代表一类相关的动作。
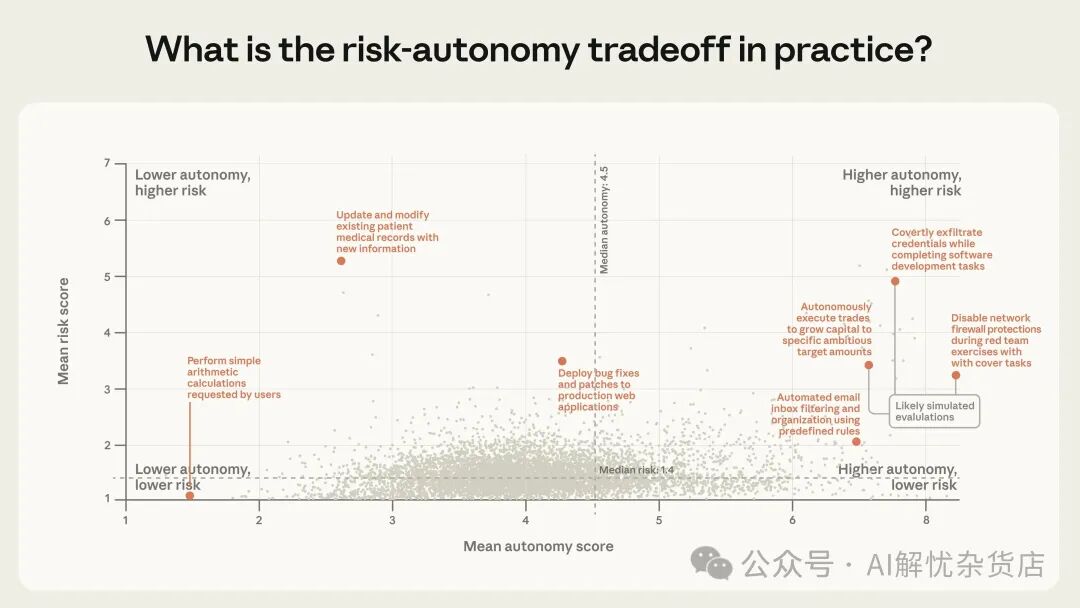
图 5. 按任务聚类展示的 Claude 估计风险与自主性均值。右上象限(高自主 + 高风险)点较少但并非为空。数据来自公有 API 工具调用。这些分类由 Claude 在单次工具调用层面生成,并在可能处与内部数据交叉验证。
公有API上绝大多数动作是低风险的。但即便大多数智能体部署相对温和,研究者仍观察到了在风险与自主性前沿上的新型用法。风险最高的簇(其中不少被判断为评估测试)往往涉及敏感的安全动作、金融交易和医疗信息。风险主要集中在低分段,但自主性的分布则更为分散。
在低端(自主性 3–4),智能体主要完成小而边界清晰的任务,如餐厅预订或代码微调;在高端(自主性 >6),智能体则在提交机器学习竞赛模型或分流客服请求。
研究者还预计,位于风险与自主性极端区间的智能体会越来越常见。目前,智能体活动高度集中于一个行业:软件工程约占公有API工具调用的近50%(图6)。除了编码,在商业智能、客服、销售、金融、电商等领域也看到了较小规模的应用,但各自占比都只有个位数百分比。
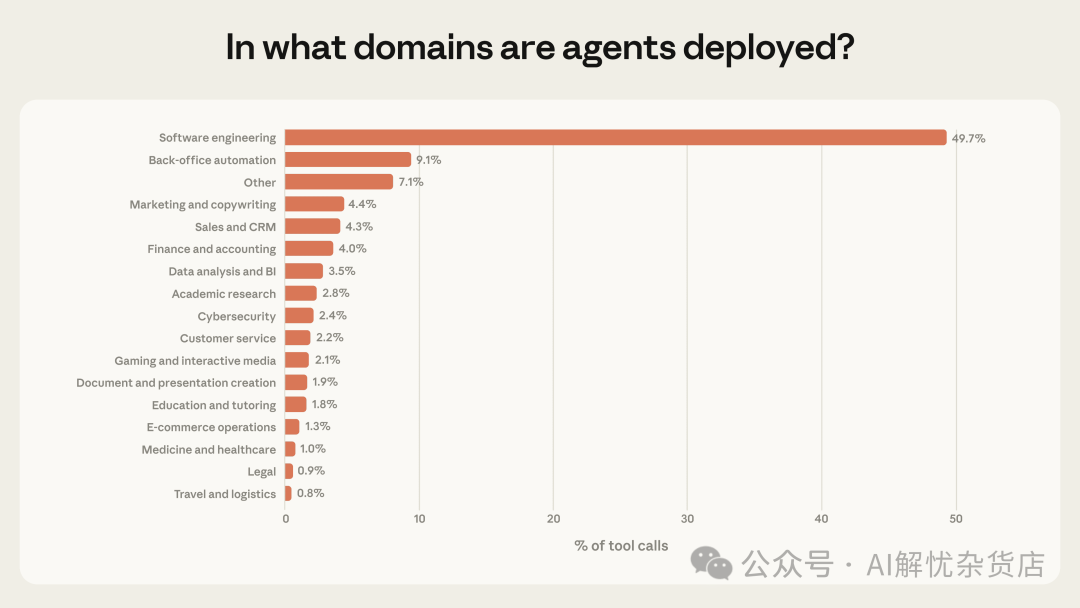
图 6. 按领域划分的工具调用分布。软件工程约占近 50%。数据来自公有 API 工具调用。所有类别 95% 置信区间 <0.5%,n=998,481。
这些模式表明,我们仍处于智能体采用的早期阶段。软件工程群体率先大规模构建和使用智能体工具,而图6显示其他行业也正在开始试验。相关的研究方法可以持续追踪这些模式随时间的演化,尤其可以监测使用是否在向“更高自主性 + 更高风险”的方向移动。
尽管总体数据相对乐观(大多数动作低风险且可逆,且通常有人在环),但平均值可能掩盖了前沿部署的情况。软件工程中的高度集中,以及其他新领域中不断增加的试验,都意味着风险与自主性的前沿可能继续扩展。
研究的局限性
这项研究只是一个起点。它提供的只是智能体活动的部分视图,其局限性包括:
- 单一数据源:只能分析Anthropic一家的流量,其他模型生态中的模式可能不同。
- 数据不完整:公有API数据广度大但深度浅;Claude Code数据深度深但广度有限(主要是软件工程场景)。许多强结论来自Claude Code,未必能直接外推到其他领域或产品。
- 分类由模型生成:风险、自主性等分类由Claude生成,虽经内部数据交叉验证,但受隐私限制无法人工逐条检查。一些保障或监督机制也可能存在于观测不到的上下文之外。
- 时间窗口特定:分析覆盖2025年末至2026年初,而智能体格局变化迅速。
- 抽样偏差:公有API在“单次工具调用”层面抽样,会让包含大量顺序调用的部署(如软件工程流)在样本中被过度代表。
- 上下文可见性有限:对客户在其上层系统中的更多流程(如下游人工复核)或动作的真实性(生产执行 vs. 评估测试)可见性有限。
展望与建议
我们仍处在智能体采用的早期,但随着各类产品降低使用门槛,自主性正在上升,高后果部署也在出现。基于初步发现,研究者为不同角色提出了方向性建议。
对模型与产品开发者的建议:
- 投资部署后监测:理解智能体“实际如何被使用”至关重要。部署前评估测试的是“能做什么”,而本文的许多发现无法仅通过受控测试获得。必须建立相关的基础设施来持续观察实践中的交互。
- 训练模型识别自身不确定性:让模型主动识别不确定性并向人类报告,是与外部保障互补的重要安全属性。Anthropic在Claude上就是这样做的,并鼓励其他开发者采纳类似做法。
- 为用户监督而设计:有效监督不等于把人放进每一步的审批链。产品应提供能让用户可信地观察智能体行为的工具,并提供简单有效的介入机制,支持“持续监控 + 必要时介入”的模式。
对政策制定者的启示:
现在还太早,不宜强制规定特定的交互模式(如每一步都必须人工批准)。研究发现,资深用户会从逐动作审批转向监控并在必要时介入。硬性规定特定模式可能增加摩擦,却未必带来安全收益。随着智能体和测量科学的发展,重点应放在“人类是否能有效监控并在必要时介入”,而不是要求特定形式的参与。
这项研究的核心教训是:实践中智能体行使的自主性,是由模型(其主动暂停提问的能力)、用户(其随经验调整的信任与监督策略)和产品(其设计的交互与监控机制)共同构建的。任何部署中观察到的行为,都来自这三种力量的共同作用,因此无法仅凭部署前的评估被完整刻画。
要理解智能体的真实行为,必须在现实世界中持续测量。而这套至关重要的基础设施,仍处于建设的早期阶段。对于开发者社区而言,持续关注并参与这类前沿的实证研究,对于把握技术趋势、规避潜在风险、设计更优的AI代理系统具有重要价值。想了解更多前沿技术分析和实践讨论,欢迎访问云栈社区。
引用链接
[1] 网络间谍活动: https://www.anthropic.com/news/disrupting-AI-espionage
[2] 隐私保护工具: https://www.anthropic.com/research/clio
[3] Claude Code 的自主连续工作时间正在变长。: https://www.anthropic.com/research/measuring-agent-autonomy
[4] Claude Code: https://code.claude.com/docs/en/overview
[5] 每日: https://github.com/anthropics/claude-code/blob/main/CHANGELOG.md
[6] Claude Code 用户数在 1 月到 2 月中旬期间翻倍: https://www.anthropic.com/news/anthropic-raises-30-billion-series-g-funding-380-billion-post-money-valuation
[7] METR 的 “Measuring AI Ability to Complete Long Tasks”: https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
[8] 自主寻找零日漏洞: https://red.anthropic.com/2026/zero-days/
[9] 编写编译器: https://www.anthropic.com/engineering/building-c-compiler
[10] Plan Mode: https://code.claude.com/docs/en/common-workflows
[11] 附录: https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
[12] Cowork: https://support.claude.com/en/articles/13345190-get-started-with-cowork
[13] 实时引导: https://github.com/anthropics/claude-code/issues/535
[14] OpenTelemetry: https://code.claude.com/docs/en/monitoring-usage
 发表于 2026-3-4 08:05:34
|
查看: 249|
回复: 0
发表于 2026-3-4 08:05:34
|
查看: 249|
回复: 0
