
北京时间 3 月 6 日凌晨,OpenAI 正式发布了下一代旗舰模型——GPT-5.4。面对谷歌 Gemini 3.1 Pro 和 Anthropic Claude Opus 4.6 的竞争,OpenAI 带来了一款集推理、编程、原生电脑操控于一体的全能模型。
不止是更聪明,更是“动手干”
如果说以前的 AI 只是一个能说会道的超级大脑,那么 GPT-5.4 第一次长出了“手”。
此次更新最核心的突破性功能,是原生计算机使用能力(Computer-Use)。这是 OpenAI 首个具备该能力的通用模型。它不再仅仅依赖 API 接口,而是能像人类一样,看懂屏幕截图,移动鼠标,敲击键盘,在各类软件和网页间穿梭自如。
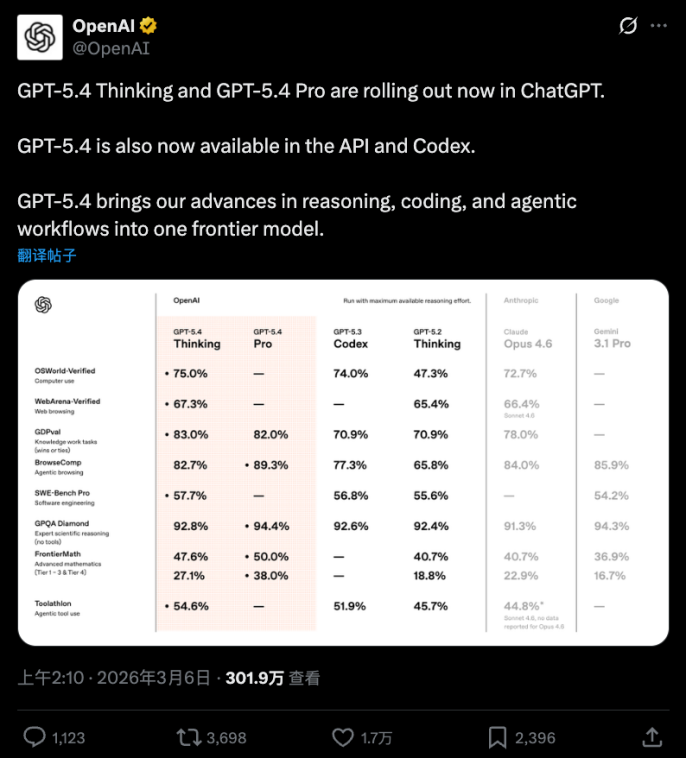
在 OSWorld-Verified 基准测试中,GPT-5.4 操作电脑的成功率达到了惊人的 75.0%。这个数据不仅远超上一代 GPT-5.2 的 47.3%,甚至超过了人类 72.4% 的基准线,也略高于刚刚登顶不久的 Claude Opus 4.6(72.7%)。
这意味着从今天起,AI 不仅能帮你写邮件,还能帮你发邮件、排日程、填表格、跑流程。那些每天消耗大量精力的、繁琐的点击操作,现在 AI 具备了完成的潜力。
跑分表现:综合能力显著提升
过去,模型往往各有短板:有的能推理但不会写代码,有的能写代码但世界知识匮乏。GPT-5.4 试图整合这些能力,其综合成绩单表现突出。
知识工作(GDVal):在横跨 44 种职业的真实工作产出测试中,GPT-5.4 以 83.0% 的得分达到或超过了人类专家水平,相比上一代的 70.9% 提升了 12 个百分点。尤其是在模拟初级投行分析师的电子表格建模中,得分高达 87.3%。
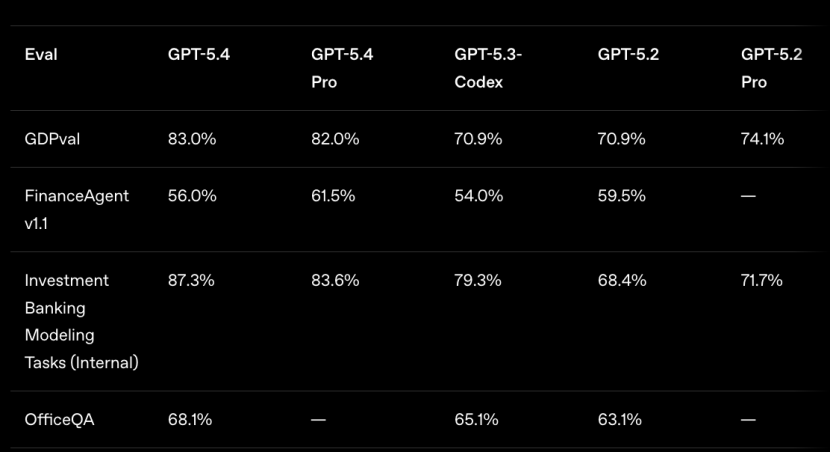
编程能力(SWE-Bench Pro):它继承了 GPT-5.3-Codex 的编程基因,得分 57.7%,略高于 Codex 版本的 56.8%。这意味着在处理软件工程问题时,你可能不再需要在不同特长的模型间频繁切换。
数学与推理(FrontierMath):在研究级别的数学难题中,GPT-5.4 Pro 拿下了 38.0% 的得分。对比一年前同类型测试的最佳成绩(约 2%),进步显著。
不仅仅是长,而是“不打断”的记忆
GPT-5.4 支持高达 100 万 Token 的上下文窗口。
100 万 Token 是什么概念?这意味着你可以直接把《三体》三部曲的全部内容,或者一个完整项目的代码库一次性扔给它,它能处理并关联上下文中的每一个细节。
更关键的是,GPT-5.4 Thinking 在 ChatGPT 中新增了“思考过程预览”和“中途介入”功能。在处理长任务时,模型会先展示它的工作计划,如果你发现方向不对,可以随时打断并调整,不需要等到它犯错返工。这种可干预的交互体验,让 AI 协作变得更可控。
效率优化:按需检索与加速生成
强大的同时,OpenAI 也在试图优化模型的使用成本。
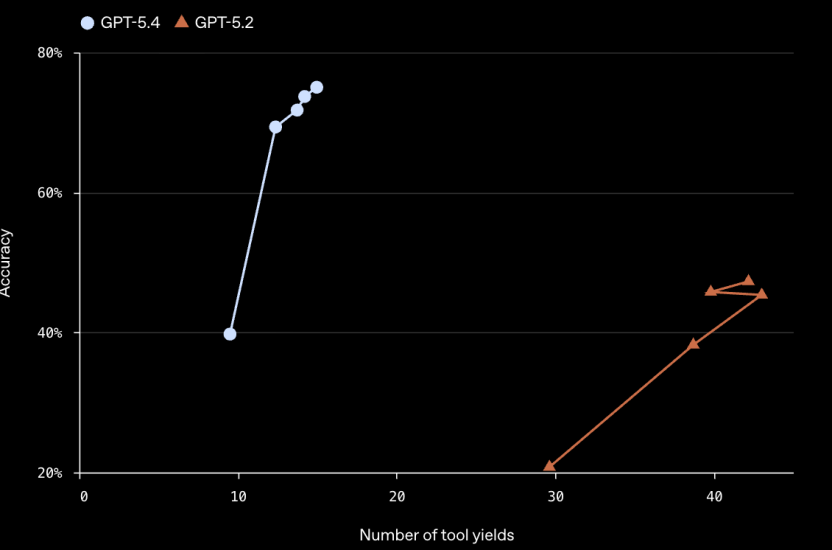
GPT-5.4 引入了全新的“工具搜索”机制。在处理拥有大量工具(如 MCP 服务器)的复杂任务时,它不再一股脑把所有工具定义塞进上下文,而是按需检索。在 Scale 的 MCP Atlas 基准测试中,这一功能在保持准确率不变的同时,将 Token 消耗量降低了 47%。
对于 开发者 来说,Codex 中的“/fast”模式能提升 Token 生成速度,使任务执行更快。
如何获取与定价
据了解,即日起,GPT-5.4 Thinking 已面向 ChatGPT Plus、Team 和 Pro 用户开放,它将取代 GPT-5.2 Thinking 成为默认的思考模型。而性能更强的 GPT-5.4 Pro 则主要面向 Pro 和企业用户。
价格方面,GPT-5.4 的 API 调用费用为输入 2.5 美元/百万 Token,输出 15 美元/百万 Token。而 Pro 版价格为输入 30 美元/百万 Token,输出 180 美元/百万 Token。
虽然价格有所上涨,但考虑到其优秀的工具使用效率,以及相比 Claude Opus 4.6 更具竞争力的 API 价格,对于需要强大代理能力的企业级应用而言,可能仍是一个值得考虑的选择。
小结
GPT-5.4 的发布,标志着一个明确的转向:大模型的竞争,已经从单纯的“参数竞赛”和“跑分刷榜”,进入了“全能执行”的新阶段。
OpenAI 这次整合了推理、编程、长上下文和电脑操控,目标直指一个更实用的形态——能够理解、思考并执行操作的智能代理。这无疑将加速 AI 在工作流自动化中的应用探索。想了解更多前沿技术动态与深度解析,欢迎关注 云栈社区。
 发表于 2026-3-7 08:02:49
|
查看: 254|
回复: 0
发表于 2026-3-7 08:02:49
|
查看: 254|
回复: 0
