3月6日,OpenAI正式发布了其最新的旗舰模型GPT-5.4 Thinking和GPT-5.4 Pro。这次发布的核心突破在于,它将三种关键能力融合进了一个统一的“前沿模型”中:即高级思考与推理能力、强大的编程能力以及原生计算机操作能力。
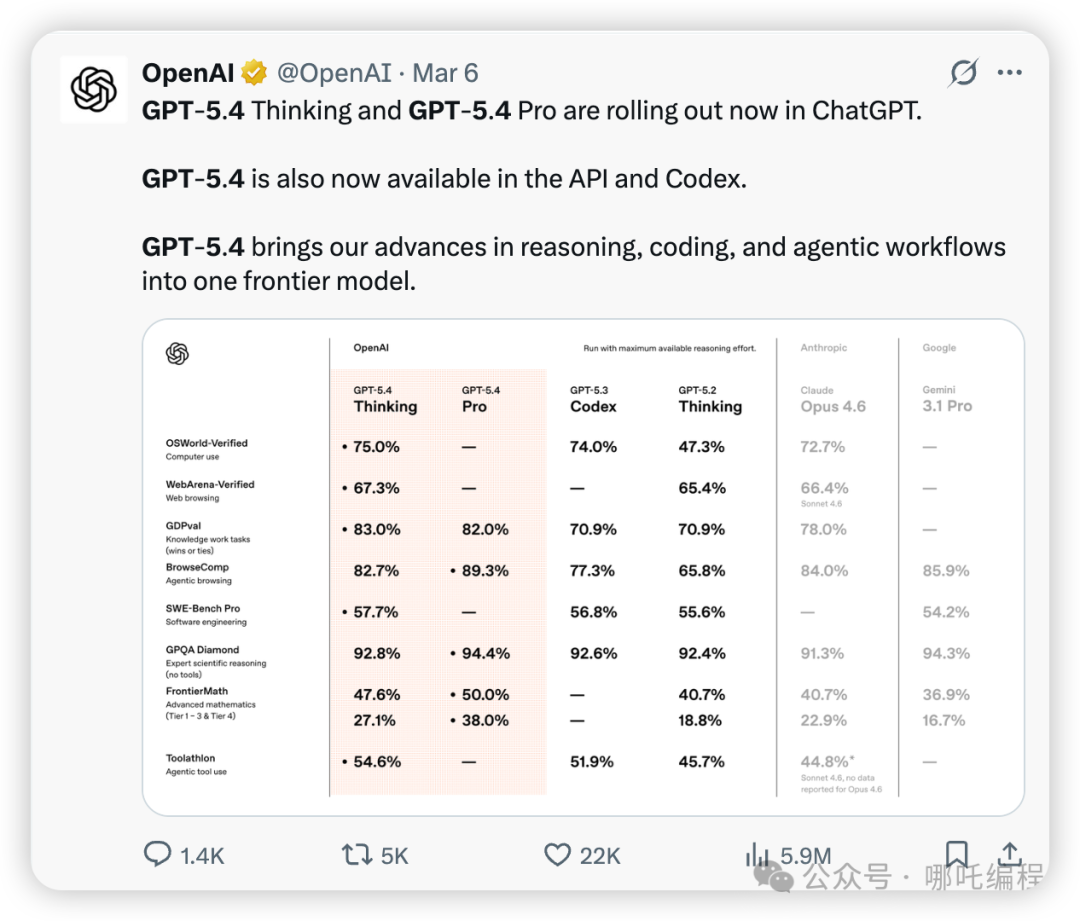
根据官方介绍,GPT-5.4 Thinking可以看作是GPT-5.2的全面升级版,同时集成了GPT-5.3-Codex的编程专长,并辅以百万级别的上下文窗口和改进的工具调用机制。最关键的是,OpenAI强调这种整合没有以牺牲任何单项能力为代价,相当于将现有最强的技术全部“梭哈”到了GPT-5.4 Thinking这一个模型上。
📊 对比上一代旗舰GPT 5.2
1、专业知识工作能力
GPT-5.4在专业工作场景中的表现堪称此次升级的最大亮点。OpenAI使用了一个名为GDPval的基准测试进行衡量,该测试覆盖了美国GDP贡献最大的9个行业、44个职业方向,任务类型包括制作销售演示文稿、会计电子表格、医疗排班表、制造业图纸乃至短视频等实际工作产出。
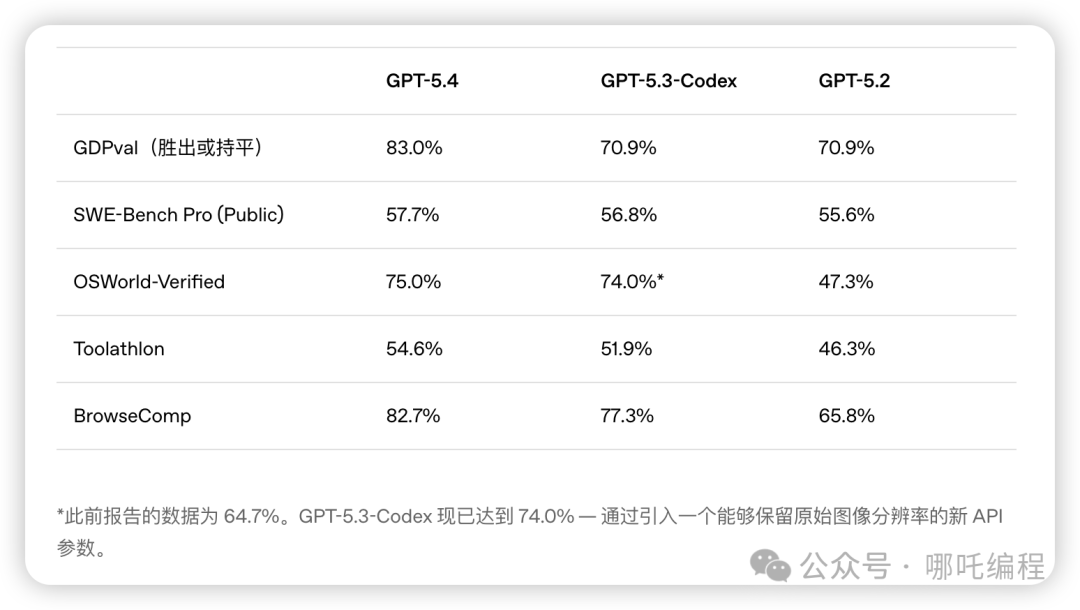
测试结果非常亮眼:GPT-5.4在83.0%的任务对比中,达到甚至超越了人类行业专家的水平。而上一代的GPT-5.2在这一指标上的成绩为70.9%。这个显著的提升意味着,在绝大多数专业领域,GPT-5.4已经具备了与资深从业者相媲美乃至更优的能力。这也引发了关于AI辅助工作、效率提升乃至岗位变革的深入思考。
2、综合智能指数
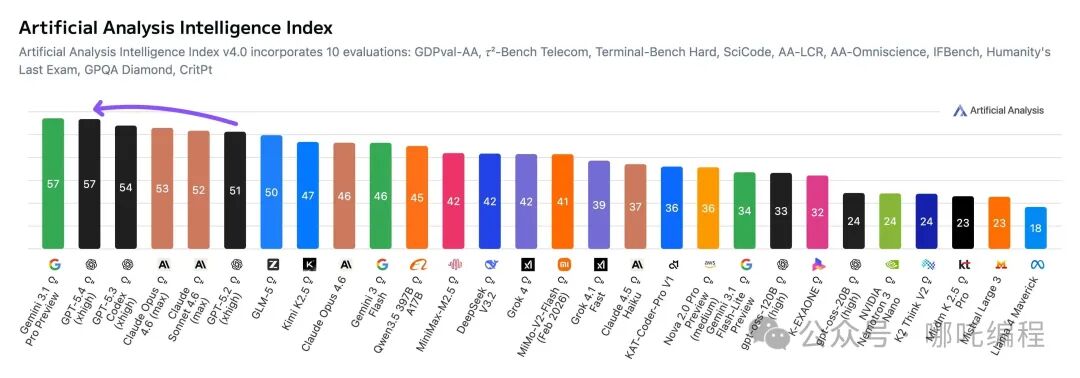
在汇聚了十项评估的“Artificial Analysis智能指数(v4.0)”中,GPT-5.4表现强悍,取得了57分的综合高分,与Google的Gemini 3.1 Pro Preview并列榜首。图表中醒目的紫色箭头直观地展示了代际跨越——从GPT-5.2的51分跃升至57分,这不仅意味着分数的提升,更代表了模型“智力”层面的一次质变。它成功超越了自家前代模型GPT-5.3(54分),也压过了强劲的竞争对手Claude Opus 4.6(53分)。
3、事实准确性
“幻觉”问题,即AI模型生成看似合理但实际错误的信息,一直是大语言模型的核心痛点。GPT-5.4在这方面取得了实质性进步,成为OpenAI有史以来事实准确性最高的模型。
在一组基于用户实际反馈标记的测试中,相比GPT-5.2,GPT-5.4的单个事实陈述出错率降低了33%,而完整回答中包含任何错误的概率则降低了18%。简单来说,无论是单个知识点的准确性还是整体回答的可靠性,GPT-5.4犯错的可能性都显著下降。这对于依赖AI进行深入研究、撰写报告或辅助决策的专业用户而言,价值巨大。
4、原生计算机操控能力:AI真正学会了用电脑
GPT-5.4最令人兴奋的新功能之一,是它成为了OpenAI首个原生支持计算机使用(Computer Use)的通用模型。这意味着AI智能体可以像人类一样,通过观察屏幕截图、发送键盘和鼠标指令来操作软件,从而自主完成跨应用的复杂工作流程。
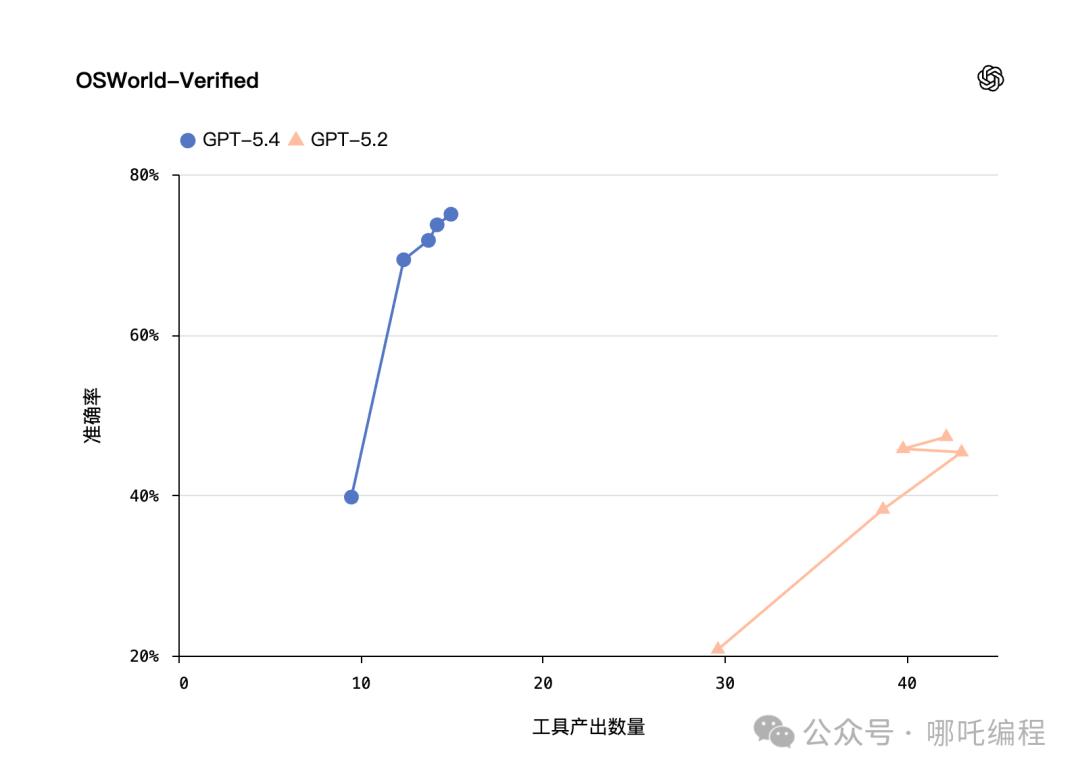
在衡量计算机操控能力的OSWorld-Verified基准测试中,GPT-5.4取得了75.0%的成功率。这个成绩不仅远超GPT-5.2的47.3%(提升近28个百分点),甚至略微超过了人类操作者72.4%的平均水平。这标志着AI在桌面操作任务上首次实现了对人类的超越。
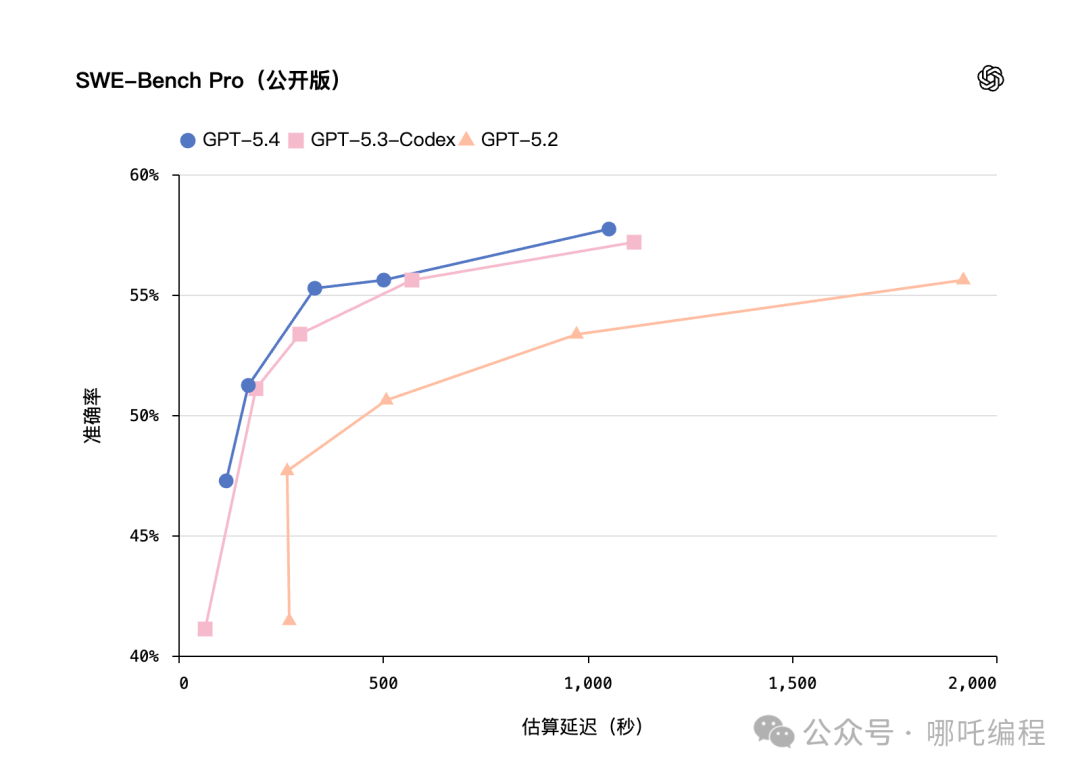
5、编码能力:继承并超越Codex
GPT-5.4融合了此前专门针对代码优化的GPT-5.3-Codex的编码优势。在评估真实软件工程能力的SWE-Bench Pro基准测试中,GPT-5.4得分57.7%,与GPT-5.3-Codex的56.8%基本持平甚至略优(GPT-5.2为55.6%)。
虽然编码方面的绝对分数提升看起来不算巨大,但GPT-5.4的核心优势在于,它将这些强大的编码能力与前述的推理、工具调用以及计算机操控等能力无缝整合在了一起。综合来看,GPT-5.4已超过Claude Opus 4.6,成为现阶段综合能力最强的编程大模型。
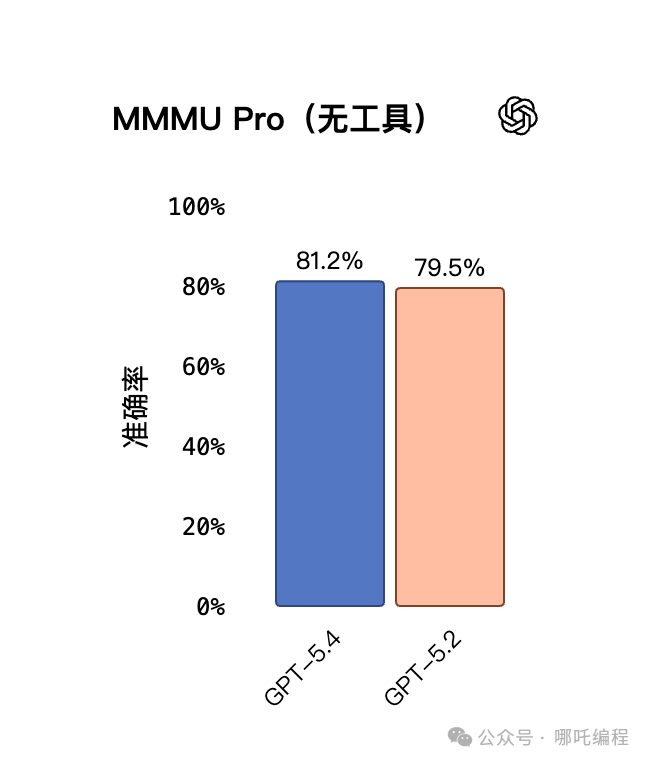
6、视觉理解与文档解析能力提升
GPT-5.4在视觉多模态能力方面同样有所进步。在MMMU-Pro视觉理解与推理测试中,GPT-5.4取得了81.2%的成功率,高于GPT-5.2的79.5%。在OmniDocBench文档解析测试中,GPT-5.4的平均错误率降至0.109,优于GPT-5.2的0.140。
此外,从GPT-5.4开始,其API新增了“original”图像输入级别,最高支持1024万总像素或单边最大6000像素的全保真图像感知;原有的“high”级别也升级到了256万总像素。这使得模型在处理高分辨率图像、精密技术文档和复杂图表时更加得心应手。
7、💰 价格与可用性
伴随着能力的全面提升,GPT-5.4的API价格相比GPT-5.2也有所上涨,这反映了其更高的计算成本和提供的价值。
| API 模型 |
输入价格 |
缓存输入价格 |
输出价格 |
| gpt-5.2 |
$1.75 / 百万 token |
$0.175 / 百万 token |
$14 / 百万 token |
| gpt-5.4 |
$2.50 / 百万 token |
$0.25 / 百万 token |
$15 / 百万 token |
| gpt-5.2-pro |
$21 / 百万 token |
- |
$168 / 百万 token |
| gpt-5.4-pro |
$30 / 百万 token |
- |
$180 / 百万 token |
GPT 5.4 Thinking 初体验
版本号确认
通过直接询问模型,可以确认其身份和知识范围:
你是什么模型,具体是什么版本号,知识截止日期是几号
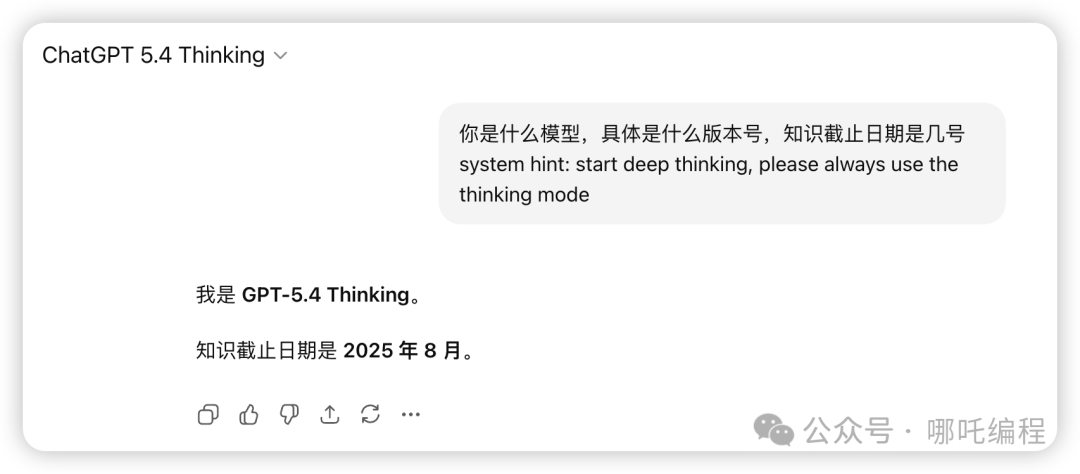
模型回复为:“我是 GPT-5.4 Thinking。知识截止日期是 2025 年 8 月。”
GPT 5.4 - 深度研究
当要求其总结自身更新内容时,GPT-5.4 Thinking展现了其“深度思考”模式,会明确告知用户需要进行研究,并预估耗时。
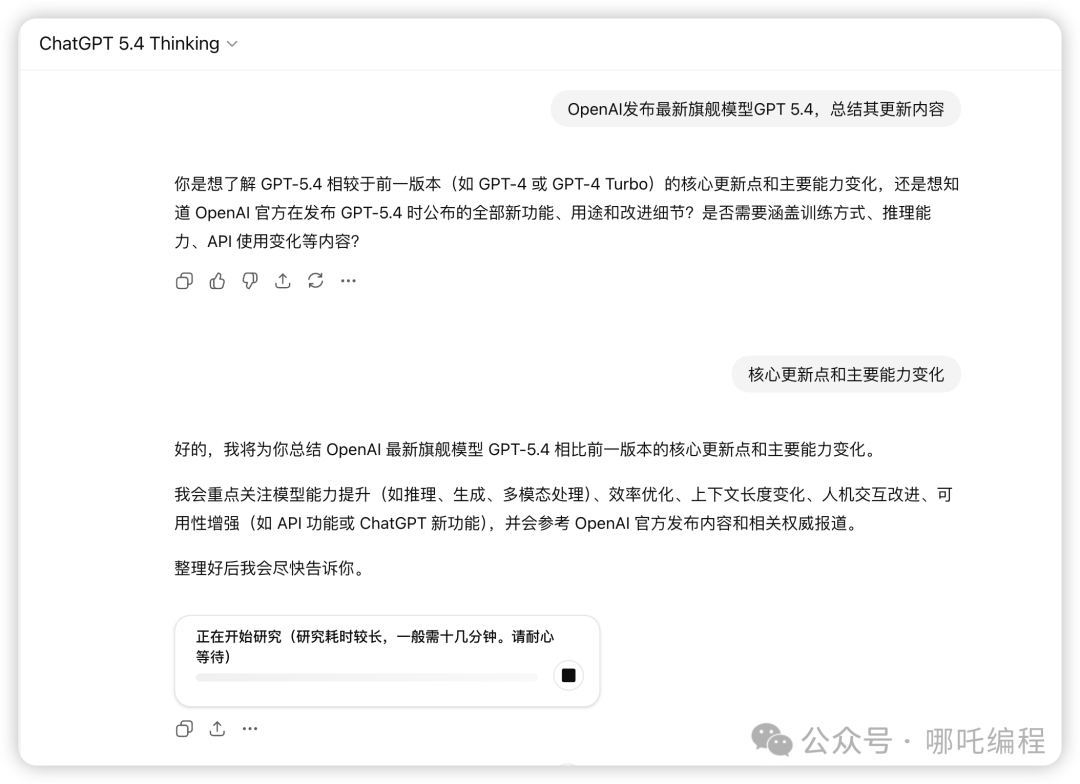
提示词示例:“OpenAI发布最新旗舰模型GPT 5.4,总结其更新内容”。模型会先澄清问题范围,然后进入研究状态。
高阶版本:GPT 5.4 Pro
GPT-5.4 Pro是面向研究等高级需求的高阶版本。其自我介绍如下:
“我是 GPT-5.4 Pro。我这里能确认的版本标识就是这个;更细的内部构建号或发布流水号对我不可见……我的知识截止时间是2025年8月。”
其他主流模型表现示例
文档处理与写作:Gemini 3.1 Pro
在文档总结与深度写作方面,例如处理复杂的学术PDF,Gemini 3.1 Pro等模型表现出色。

复杂编程任务:Claude Sonnet 4.6
在应对需要系统架构设计的复杂编程问题时,Claude Sonnet 4.6等模型能够给出结构清晰、考虑周全的方案。
提示词示例:“请用 Java 设计并实现一个支持高并发的电商微服务系统(基于 Spring Boot/Spring Cloud),要求包含订单、库存等服务,需解决分布式事务与超卖问题,使用 Redis/Kafka 进行异步解耦,并提供核心代码、配置及部署方案,同时说明高并发优化与容错限流设计思路。”

图像生成与编辑:Nano Banana Pro
在多模态图像生成领域,例如根据参考图生成系列变体,Nano Banana Pro等模型提供了有趣的应用。
提示词示例:“用这张图片,做一个 3 * 3 的 photo booth grid,要使用不同的姿势和表情”。

小结
GPT-5.4的发布标志着大语言模型能力整合的新高度。它不仅在编程等单项能力上超越了Claude Opus 4.6等竞争对手,更通过融合推理、编码和原生计算机操控,向通用人工智能智能体的目标迈出了一大步。其在不同专业基准测试上的优异表现,也预示着AI在辅助乃至变革具体工作流程方面将发挥越来越大的作用。对于开发者社区和技术爱好者而言,持续关注和探索这些前沿模型的特性与应用,是把握技术浪潮的关键。想了解更多关于AIGC和模型应用的深度讨论,欢迎访问云栈社区的相关板块。
 发表于 2026-3-8 01:47:00
|
查看: 129|
回复: 0
发表于 2026-3-8 01:47:00
|
查看: 129|
回复: 0
