很多人使用Kubernetes已经很久了,但一旦被问到“究竟谁在控制Pod副本数?Deployment还是ReplicaSet?”时,往往仍会感到困惑。
表面上看似乎是Deployment在掌控一切,但实际的关系远比想象中要复杂,理解这一点对于处理扩缩容、滚动升级和故障排查至关重要。本文旨在彻底厘清这两者的核心职责与协作关系。
01 核心结论:Deployment不直接管理Pod
首先要明确的结论是:
- 真正控制Pod副本数量的,是ReplicaSet。
- Deployment本身并不直接创建或管理Pod。
那么Deployment负责什么?Deployment是 “管理ReplicaSet的控制器” ,而ReplicaSet才是 “管理Pod的控制器”。这是一种典型的Kubernetes分层设计思想。
02 命令执行时,底层发生了什么?
假设你通过kubectl apply创建了如下一个Deployment:
apiVersion: apps/v1
kind: Deployment
spec:
replicas: 3
template:
spec:
containers:
- name: app
image: nginx:1.25
你以为的流程是:Kubernetes直接创建了3个Pod。
实际发生的流程是这样的:
- Deployment Controller 监听到新的Deployment资源。
- Controller根据Deployment中定义的Pod模板,创建一个对应的ReplicaSet资源。
- ReplicaSet Controller 监听到这个新的ReplicaSet,并读取其
spec.replicas: 3字段。
- ReplicaSet负责创建并维持3个Pod运行。
- 此后,只要Pod数量少于3个,ReplicaSet就会自动创建新的Pod进行补充。
在整个过程中,Deployment并不直接监控Pod的数量。
03 ReplicaSet:功能单一的基础控制器
ReplicaSet的职责极其专一,它只关心一件事:确保由其管理的Pod数量,精确等于spec.replicas中定义的数值。
它不关心:
- Pod运行的是否是新版本。
- 系统是否正处于升级状态。
- Pod内部具体的业务逻辑。
它只做三件事:
- 如果Pod数量少了,就创建新的补上。
- 如果Pod数量多了,就删除多余的。
- 通过标签选择器(selector)来识别和管理哪些Pod归自己控制。
ReplicaSet本身没有版本概念,也没有任何升级策略。
04 Deployment:高级策略与版本的管理者
Deployment存在的核心价值,正是为了解决ReplicaSet的局限性:
① ReplicaSet无法实现版本切换
一个ReplicaSet只认一个Pod模板。一旦镜像版本(或模板其他部分)需要更新,就必须创建一个全新的ReplicaSet。
② ReplicaSet不支持滚动升级
ReplicaSet的副本控制是“一刀切”的,它不考虑更新顺序、服务可用性等风险。
而Deployment则负责以下高级管理功能:
- 为每一个应用版本创建一个独立的ReplicaSet。
- 决定在升级过程中:
- 哪个ReplicaSet(新版本)应该扩容。
- 哪个ReplicaSet(旧版本)应该缩容。
- 通过策略(如
maxSurge和maxUnavailable)控制滚动升级的节奏和风险。
- 记录版本历史,支持一键回滚。
简而言之,Deployment负责管理ReplicaSet的生命周期和更新策略。这种基于基础控制器构建高级控制器的模式,是云原生架构中常见的解耦设计。
05 透过一次升级,看清协作流程
当你将Deployment中的镜像从nginx:1.25更新到nginx:1.26时,Deployment会执行以下操作:
- 保留现有的、管理着v1版本Pod的旧ReplicaSet。
- 根据新模板,创建一个管理v2版本Pod的新ReplicaSet。
- 开始调整两个ReplicaSet的副本数,实现渐进式替换:
- 新ReplicaSet(v2):副本数从 0 → 1 → 2 → 3
- 旧ReplicaSet(v1):副本数从 3 → 2 → 1 → 0
需要特别注意:每一次Pod的创建或删除动作,都是由具体的ReplicaSet控制器执行的。 Deployment扮演的是“指挥官”的角色,只向ReplicaSet下达扩缩容的指令。
06 扩缩容时,指令如何传递?
当你执行命令kubectl scale deployment my-app --replicas=5进行扩容时,流程如下:
- Deployment对象自身的
spec.replicas字段被更新为5。
- Deployment Controller在协调循环中,识别出当前哪个ReplicaSet是“活跃的”(通常是最新版本对应的那个)。
- Controller将该活跃ReplicaSet的
spec.replicas修改为5。
- ReplicaSet Controller检测到副本数变化,随即开始行动,创建新的Pod直至总数达到5个。
因此,流程是:Deployment做出决策并确定目标,ReplicaSet负责具体执行。这种机制确保了无论应用处于哪个版本,扩缩容的对象始终是正确的Pod集合,这也是理解云原生应用编排的关键之一。
07 为何我们几乎不直接操作ReplicaSet?
虽然你可以通过kubectl scale rs my-app-xxxxx --replicas=10直接操作某个ReplicaSet,但这是一种不被推荐的做法。
主要原因在于:Deployment会持续监控并纠正其下ReplicaSet的状态。 在下一个协调周期,Deployment Controller会发现ReplicaSet的副本数偏离了其自身spec.replicas定义的期望值,并立即将其“拉回”到Deployment所定义的正确状态。
只要Deployment存在,其下的ReplicaSet就始终是一个被管理的、从属的资源。
08 Kubernetes为何保留ReplicaSet资源?
这体现了Kubernetes核心的设计哲学:能力拆分与组合复用。
- ReplicaSet:提供单一、稳定、可靠的副本控制能力,职责清晰,可被复用。
- Deployment:在此基础之上,构建高级的、面向应用的管理能力,如版本控制和更新策略。
这种设计使得Kubernetes能够灵活地扩展出更多的工作负载控制器,如StatefulSet、DaemonSet以及各种Operator,而无需重复实现最底层的副本维护逻辑,充分展现了云原生生态的模块化优势。
09 一张图总结核心区别
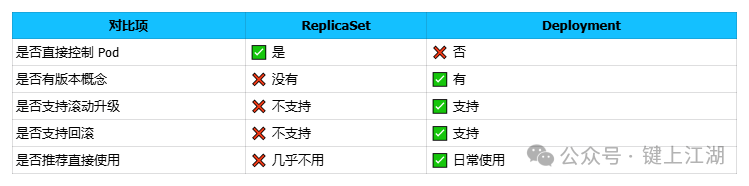
10 一句话总结
ReplicaSet是坚定的执行者,负责维护Pod副本数量;Deployment是智慧的指挥官,负责制定版本更新与发布策略。 你在集群中看到的每一个由Deployment管理的Pod,其直接的创建者都是一个ReplicaSet;而你所能使用的所有高级部署策略,其来源都是Deployment。
 发表于 2025-12-8 01:52:04
|
查看: 178|
回复: 0
发表于 2025-12-8 01:52:04
|
查看: 178|
回复: 0
