周末逛技术论坛时看到一个求助帖,发帖人很困惑,为什么自己的数据导出接口跑得这么慢。
他的代码大致是这样的:
public String buildUserReport(List<User> users) {
String result = "";
for (User user : users) {
result += user.getName() + "," + user.getEmail() + "\n";
}
return result;
}
在本地用几百条数据测试时一切正常,但一到生产环境,处理 5000 个用户时,接口耗时竟达到了 0.9 秒。
有经验的朋友在下面回复,建议他把 String 拼接换成 StringBuilder。改动后,同样的任务仅用 4 毫秒 就跑完了。
性能提升了整整 225 倍。
这个问题看似基础,但许多开发者——包括一些工作数年的——可能都没意识到:在循环中使用 String 的 += 进行拼接,性能损耗会如此巨大。今天,我们就来聊聊 Java 中三个关于 String 的经典陷阱,它们都披着“看似正确”的外衣,实则暗藏隐患。
一、循环中使用 += 拼接字符串
为什么慢?
核心原因在于 String 对象的 不可变性。
每次执行 result += “xxx” 时,Java 虚拟机在背后默默做了以下几件事:
- 创建一个全新的
String 对象。
- 将
result 中已有的内容复制到新对象中。
- 将 “xxx” 这部分新内容追加进去。
- 将这个新对象的引用赋值给变量
result。
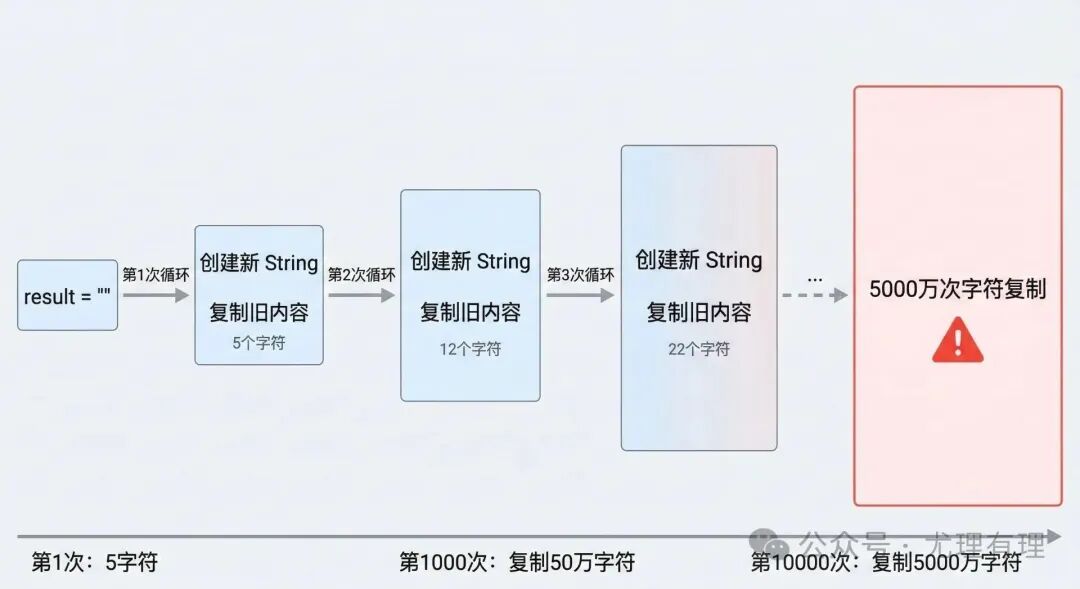
循环一万次,就意味着创建一万个中间 String 对象,并且 每一次都要复制之前积累的全部旧内容。
复杂度爆炸
我们可以用伪代码来直观理解这个过程:
// 伪代码表示
for (int i = 0; i < n; i++) {
result = result + data; // 每次复制 i 个字符
}
- 第 1 次循环:复制 1 个字符
- 第 2 次循环:复制 2 个字符
- 第 3 次循环:复制 3 个字符
- …
- 第 n 次循环:复制 n 个字符
这形成了一个等差数列求和,总的时间复杂度是 O(n²)。
如果最终要拼接一个长度为 10,000 的字符串,总共需要执行的字符复制次数是 1 + 2 + 3 + … + 10000 = 5000 万次。
正确写法
解决方案是使用可变的 StringBuilder(或在单线程环境下使用更快的 StringBuffer)。
// ✅ 用 StringBuilder
public String buildUserReport(List<User> users) {
StringBuilder sb = new StringBuilder();
for (User user : users) {
sb.append(user.getName())
.append(",")
.append(user.getEmail())
.append("\n");
}
return sb.toString();
}
StringBuilder 直接在底层的 char[] 数组上进行操作,无需在每次追加时都复制旧内容,其时间复杂度是 O(n)。
性能对比(实测)
以下是一组简单的性能测试数据,可以清晰看出差距:
| 数据量 |
+= 拼接 |
StringBuilder |
提升倍数 |
| 1000 |
35ms |
1ms |
35x |
| 5000 |
900ms |
4ms |
225x |
| 10000 |
3600ms |
8ms |
450x |
数据量越大,性能差距越呈指数级扩大。
说明:以上数据为个人测试结果。实际性能会受 JVM 版本、GC 策略、系统负载等因素影响,但总体趋势一致:数据量越大,StringBuilder 的优势越明显。
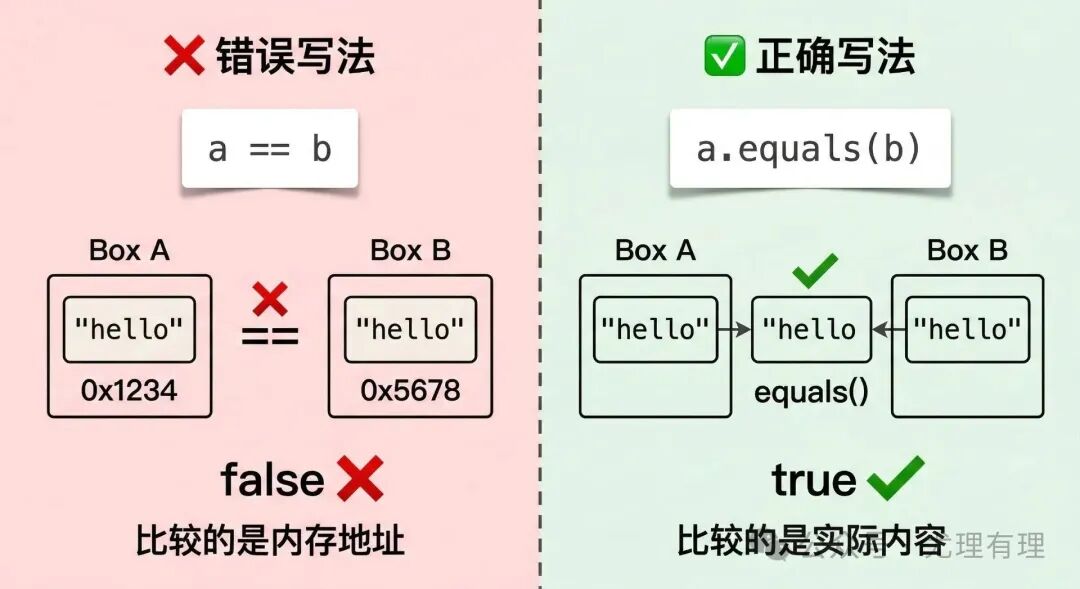
二、用 == 比较 String 内容
经典错误
String a = “hello”;
String b = new String(“hello”);
System.out.println(a == b); // false ❌
为什么会错?
关键在于,== 运算符在比较对象时,比较的是两个对象在内存中的地址(引用是否相同),而不是它们的内容是否相等。
这就涉及到一个重要的 计算机基础 概念——字符串常量池。为了节省内存,JVM 会将字符串字面量存储在这个池中并尝试复用。
String a = “hello”; // 首次创建,放入常量池
String b = “hello”; // 再次使用字面量,直接从常量池拿到同一个对象的引用
String c = new String(“hello”); // 使用 new 关键字,强制在堆内存中创建一个全新的 String 对象
System.out.println(a == b); // true(是同一对象)
System.out.println(a == c); // false(是不同对象)
为什么会“偶然正确”?
有时你会发现用 == 比较字符串,结果是对的,这让你误以为这种写法可行。
public boolean isAdmin(String role) {
return role == “admin”; // 偶尔能对,但千万别这么写!
}
这通常是因为你比较的两个字符串都是字面量,JVM 的优化让它们指向了常量池中的同一个对象。但这依赖于 JVM 的具体实现,并非 Java 语言规范所保证的行为。一旦字符串是通过 new String()、substring()、+ 运算或其他任何动态方式生成的,== 比较就会失灵,导致难以排查的 Bug。
正确写法
永远使用 equals() 方法来比较字符串的内容。
// ✅ 用 equals()
String a = “hello”;
String b = new String(“hello”);
System.out.println(a.equals(b)); // true ✅
如果担心可能出现的空指针异常,可以使用 java.util.Objects.equals() 工具方法,它对 null 值友好:
Objects.equals(str1, str2); // 即使 str1 或 str2 是 null 也不会抛出 NPE
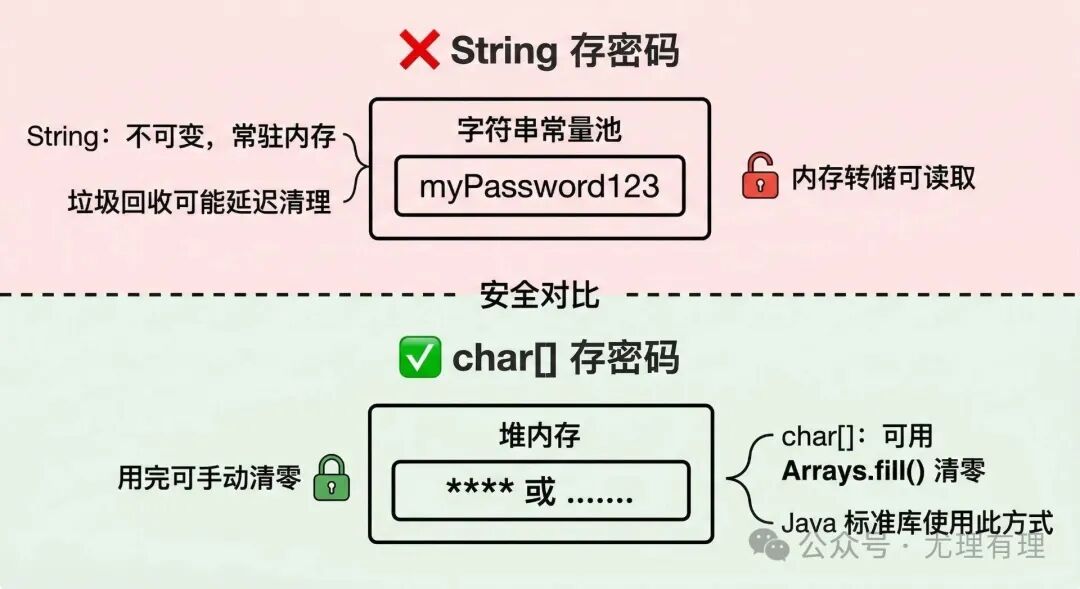
三、用 String 存储密码等敏感信息
安全隐患
// ❌ 别这么干!
public void login(String username, String password) {
// password 这个 String 对象可能被驻留在常量池
// 在内存中存留时间不确定,存在被窃取的风险
}
String 有两个特性让它极不适合存储密码这类敏感信息:
- 常量池驻留风险:字符串字面量有可能会被 JVM 驻留在字符串常量池中,其生命周期可能超出预期,垃圾回收可能不会立即清理。
- 不可变性:一旦创建,你就无法手动清除
String 中的内容。密码会以明文形式在内存中留存,直到被 GC 回收。
攻击场景
如果你的应用程序因核心转储、内存泄漏分析或被恶意工具扫描而导致内存被 dump(内存转储):
String 存储的密码 → 在内存转储文件中清晰可见。char[] 存储的密码 → 可以在使用后立即手动覆盖清零,极大减少了敏感信息在内存中的暴露时间。
正确写法
应使用 char[] 来接收和存储密码。
// ✅ 用 char[]
public void login(String username, char[] password) {
try {
// 验证密码的逻辑
authenticate(username, password);
} finally {
// 无论验证成功与否,都在 finally 块中手动清零密码数组
Arrays.fill(password, ‘\0’);
}
}
使用完毕后,立即调用 Arrays.fill() 将数组内容填充为空白字符(如 \0),这样密码就不会在内存中残留。
Java 标准库自身就遵循了这一安全实践:
javax.swing.JPasswordField.getPassword() 方法返回的就是 char[]。- 如果你必须从
String 转换,使用 String.toCharArray(),但切记在之后清零该数组。
总结
String 是 Java 中最基础、最常用的类,但也正是因为其基础,一些看似简单的用法背后却隐藏着性能与安全的深坑。
最后再回顾一下三个核心要点:
- 循环拼接字符串:果断使用
StringBuilder(或 StringBuffer),彻底告别 +=。
- 字符串内容比较:无条件使用
equals() 或 Objects.equals(),让 == 只用于基本类型和对象引用比较。
- 存储敏感信息:优先选择
char[],并在使用后立即手动清零,这是安全编程的基本素养。
代码看起来正确,并不等于它在所有场景下都能正确、高效、安全地运行。多关注这些底层细节,能帮助我们在云栈社区这样的技术平台写出更健壮、更专业的代码。
 发表于 2026-3-11 19:37:29
|
查看: 233|
回复: 0
发表于 2026-3-11 19:37:29
|
查看: 233|
回复: 0
