一、概述
本文将详细介绍在 Serverless 容器环境中,借助观测云方案实现容器内日志采集的实用方法。核心方案是通过观测云提供的 CRD 定义,结合 DataKit Operator,以 sidecar 形式注入 logfwd 容器来完成采集任务。这套方案的主要优势在于:
- 集中化管理采集配置:通过监听 Kubernetes
ClusterLoggingConfig 自定义资源定义,暴露匹配的规则供 logfwd sidecar 容器轮询获取(默认每60秒向 Operator 发起一次 HTTP 请求,要求 logfwd 版本 ≥ 1.86.0)。
- 热更新与精细匹配:基于 CRD 定义的 Selector(如命名空间、Pod、标签、容器)可以实时修改并立即生效,无需重建任何工作负载。
二、前置条件
在开始部署之前,请确保您的环境满足以下要求:
- Kubernetes 集群版本为 1.16 或更高。
- 已安装 DataKit,并开启了
logfwdserver 采集器。通常情况下,其默认监听端口是 9533。
- DataKit 的 Service 需要开放
9533 端口,以确保其他 Pod 能够通过 datakit-service.datakit.svc:9533 地址访问到它。
- 已安装 DataKit-Operator,版本为 v1.7.0 或更高。
- 具备集群管理员权限,用于注册所需的 CRD。
三、采集流程
1. 注册 Kubernetes CRD
首先,我们需要在集群中注册一个名为 ClusterLoggingConfig 的 CRD。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: clusterloggingconfigs.logging.datakits.io
labels:
app: datakit-logging-config
version: v1alpha1
spec:
group: logging.datakits.io
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
apiVersion:
type: string
kind:
type: string
metadata:
type: object
spec:
type: object
required:
- selector
properties:
selector:
type: object
properties:
namespaceRegex:
type: string
podRegex:
type: string
podLabelSelector:
type: string
containerRegex:
type: string
podTargetLabels:
type: array
items:
type: string
configs:
type: array
items:
type: object
required:
- source
- type
properties:
source:
type: string
type:
type: string
disable:
type: boolean
path:
type: string
multiline_match:
type: string
pipeline:
type: string
storage_index:
type: string
tags:
type: object
additionalProperties:
type: string
scope: Cluster
names:
plural: clusterloggingconfigs
singular: clusterloggingconfig
kind: ClusterLoggingConfig
shortNames:
- logging
kubectl apply -f clusterloggingconfig-crd.yaml
kubectl get crd clusterloggingconfigs.logging.datakits.io

2. 安装配置 DataKit-Operator
接下来,安装并配置 DataKit-Operator。
- 安装 DataKit-Operator v1.7.0 及以上版本。你可以通过
kubectl apply -f datakit-operator.yaml 来应用最新的 Operator 部署文件。或者,参考下面的最小权限配置示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: datakit-operator
rules:
- apiGroups: ["logging.datakits.io"]
resources: ["clusterloggingconfigs"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: datakit-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: datakit-operator
subjects:
- kind: ServiceAccount
name: datakit-operator
namespace: datakit
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: datakit-operator
namespace: datakit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: datakit-operator
namespace: datakit
labels:
app: datakit-operator
spec:
replicas: 1 # Do not change the ReplicaSet number!
selector:
matchLabels:
app: datakit-operator
template:
metadata:
labels:
app: datakit-operator
spec:
serviceAccountName: datakit-operator
containers:
- name: operator
# other..
- 关键在于在 DataKit-Operator 的配置中设置
logfwds 数组。你需要配置 namespace_selectors、label_selectors 等匹配规则,以及 log_volume_paths 来指定挂载的日志目录。请注意,namespace_selectors 和 label_selectors 是“且”的关系。
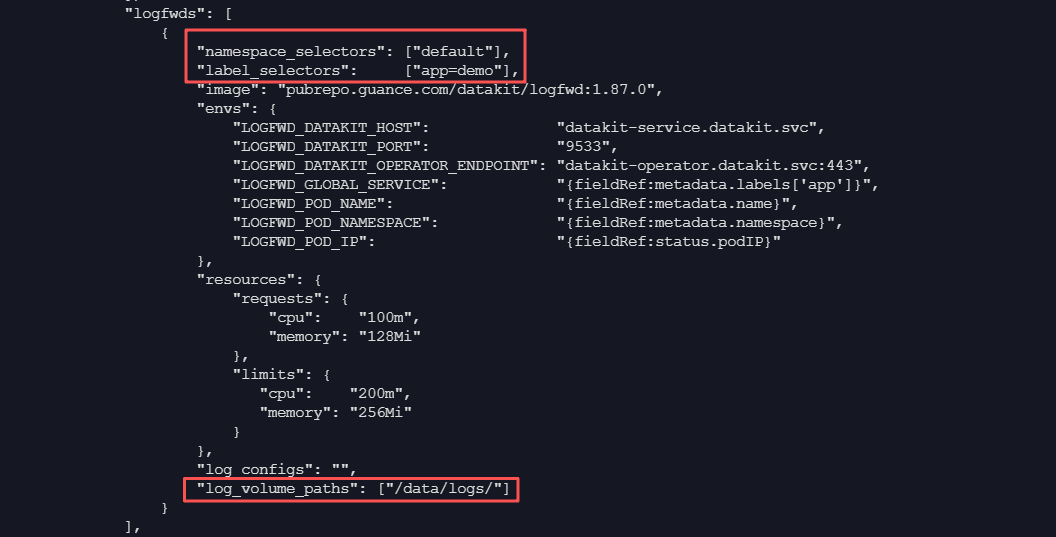
3. DataKit Deployment 部署
在 Serverless 集群(如超级节点集群)中,你需要以 Deployment 的形式部署 DataKit。配置时需特别注意资源类型、副本数、确保开启 logfwdserver 采集器,并适当调整 Deployment 的更新策略。配置示例如下:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: datakit
rules:
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["clusterroles"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["nodes", "nodes/stats", "nodes/metrics", "namespaces", "pods", "pods/log", "events", "services", "endpoints", "persistentvolumes", "persistentvolumeclaims", "pods/exec"]
verbs: ["get", "list", "watch"]
- apiGroups: ["apps"]
resources: ["deployments", "daemonsets", "statefulsets", "replicasets"]
verbs: ["get", "list", "watch"]
- apiGroups: ["batch"]
resources: ["jobs", "cronjobs"]
verbs: ["get", "list", "watch"]
- apiGroups: ["monitoring.coreos.com"]
resources: ["podmonitors", "servicemonitors"]
verbs: ["get", "list", "watch"]
- apiGroups: ["logging.datakits.io"]
resources: ["clusterloggingconfigs"]
verbs: ["get", "list", "watch"]
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: datakit
namespace: datakit
---
apiVersion: v1
kind: Service
metadata:
name: datakit-service
namespace: datakit
spec:
selector:
app: daemonset-datakit
ports:
- name: svc-http-port
protocol: TCP # for HTTP apis and some collector(inputs) HTTP server, such as DDTrace
port: 9529
targetPort: http-port
- name: svc-statsd-port
protocol: UDP
port: 8125
targetPort: statsd-port
- name: svc-otel-grpc-port
protocol: TCP
port: 4317
targetPort: otel-grpc-port
- name: svc-logfwd-port
protocol: TCP
port: 9533
targetPort: logfwd-port
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: datakit
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: datakit
subjects:
- kind: ServiceAccount
name: datakit
namespace: datakit
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: daemonset-datakit
name: datakit
namespace: datakit
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: daemonset-datakit
template:
metadata:
labels:
app: daemonset-datakit
spec:
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ENV_K8S_NODE_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- name: ENV_K8S_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
#- name: ENV_K8S_CLUSTER_NODE_NAME
# value: cluster_a_$(ENV_K8S_NODE_NAME)
- name: ENV_DATAWAY
value: https://openway.guance.com?token=tkn_3a0052c9f6d3498c8ce9ca0988fd9c82 # Fill your real Dataway server and(or) workspace token
- name: ENV_CLUSTER_NAME_K8S
value: lyr-test
- name: ENV_GLOBAL_HOST_TAGS
value: host=__datakit_hostname,host_ip=__datakit_ip
- name: ENV_GLOBAL_ELECTION_TAGS # Default not set
value: ""
- name: ENV_DEFAULT_ENABLED_INPUTS
value: statsd,dk,cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container,kubernetesprometheus,logfwdserver,ddtrace
- name: ENV_ENABLE_ELECTION
value: enable
- name: ENV_HTTP_LISTEN
value: 0.0.0.0:9529
- name: HOST_PROC
value: /rootfs/proc
- name: HOST_SYS
value: /rootfs/sys
- name: HOST_ETC
value: /rootfs/etc
- name: HOST_VAR
value: /rootfs/var
- name: HOST_RUN
value: /rootfs/run
- name: HOST_DEV
value: /rootfs/dev
- name: HOST_ROOT
value: /rootfs
image: pubrepo.guance.com/datakit/datakit:1.86.2
imagePullPolicy: IfNotPresent
name: datakit
ports:
- containerPort: 9529
hostPort: 9529
name: http-port
protocol: TCP
- containerPort: 8125
hostPort: 8125
name: statsd-port
protocol: UDP
- containerPort: 4317
hostPort: 4317
name: otel-grpc-port
protocol: TCP
- containerPort: 9533
hostPort: 9533
name: logfwd-port
protocol: TCP
resources:
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "2000m"
memory: "4Gi"
securityContext:
privileged: true
volumeMounts:
- mountPath: /usr/local/datakit/cache
name: cache
readOnly: false
- mountPath: /rootfs
name: rootfs
mountPropagation: HostToContainer
- mountPath: /var/run
name: run
mountPropagation: HostToContainer
- mountPath: /sys/kernel/debug
name: debugfs
- mountPath: /var/lib/containerd/container_logs
name: container-logs
mountPropagation: HostToContainer
hostIPC: true
hostPID: true
restartPolicy: Always
serviceAccount: datakit
serviceAccountName: datakit
tolerations:
- operator: Exists
volumes:
- configMap:
name: datakit-conf
name: datakit-conf
# - name: hellopythond
# configMap:
# name: python-scripts
- hostPath:
path: /
name: rootfs
- hostPath:
path: /var/run
name: run
- hostPath:
path: /sys/kernel/debug
name: debugfs
- hostPath:
path: /root/datakit_cache
name: cache
- hostPath:
path: /var/lib/containerd/container_logs
name: container-logs
# # ---iploc-start
#- emptyDir: {}
# name: datakit-ipdb
# # ---iploc-end
strategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
kubectl apply -f datakit.yaml
4. 创建日志 CRD 采集配置
现在,我们可以创建一个 ClusterLoggingConfig 资源来定义具体的日志采集规则。
- 例如,以下配置用于采集
default 命名空间中,所有标签为 app=demo 的 Pod 内部日志,并将日志来源命名为 demo-file。
apiVersion: logging.datakits.io/v1alpha1
kind: ClusterLoggingConfig
metadata:
name: demo-logs
spec:
selector:
namespaceRegex: "^(default)$"
podRegex: "^(deploy.*)$"
podLabelSelector: "app=demo"
podTargetLabels:
- app
- version
- enviroment
configs:
- source: "demo-file"
type: "file"
path: "/data/logs/server/server.log"
tags:
log_type: "server"
component: "springboot-server"
kubectl apply -f logging-config.yaml

5. 查看日志上报(首次需重启业务)
配置完成后,如何验证日志是否成功上报了呢?
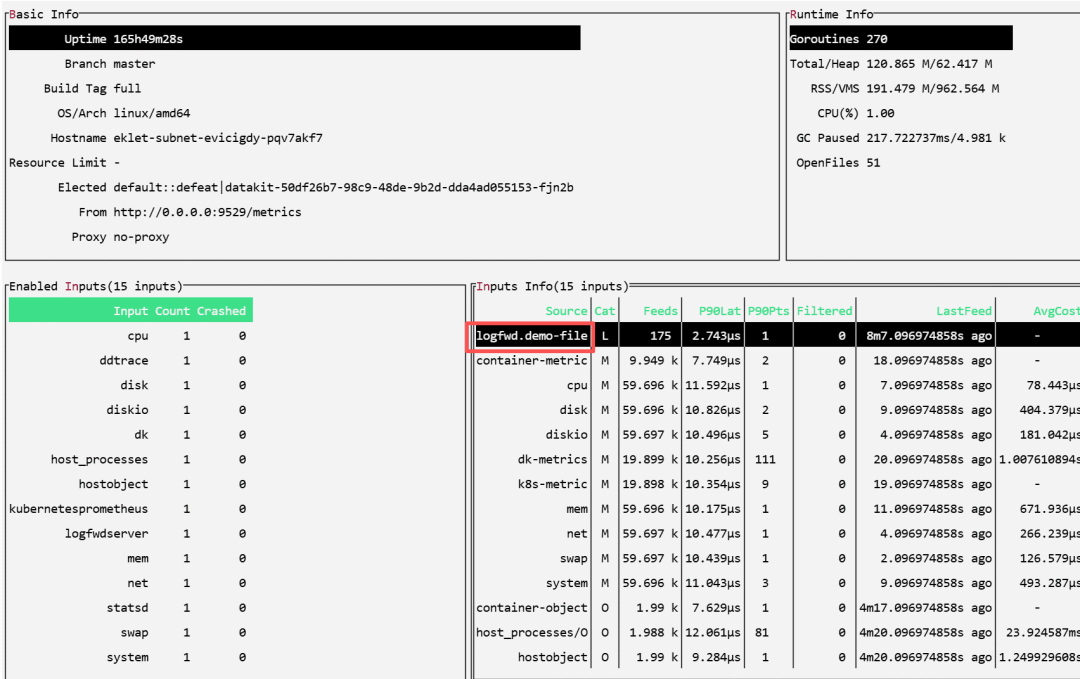
- 在 DataKit 容器内,执行
datakit monitor 命令,可以查看各个采集器的运行状态和日志上报量。logfwd 相关的条目应该会出现。
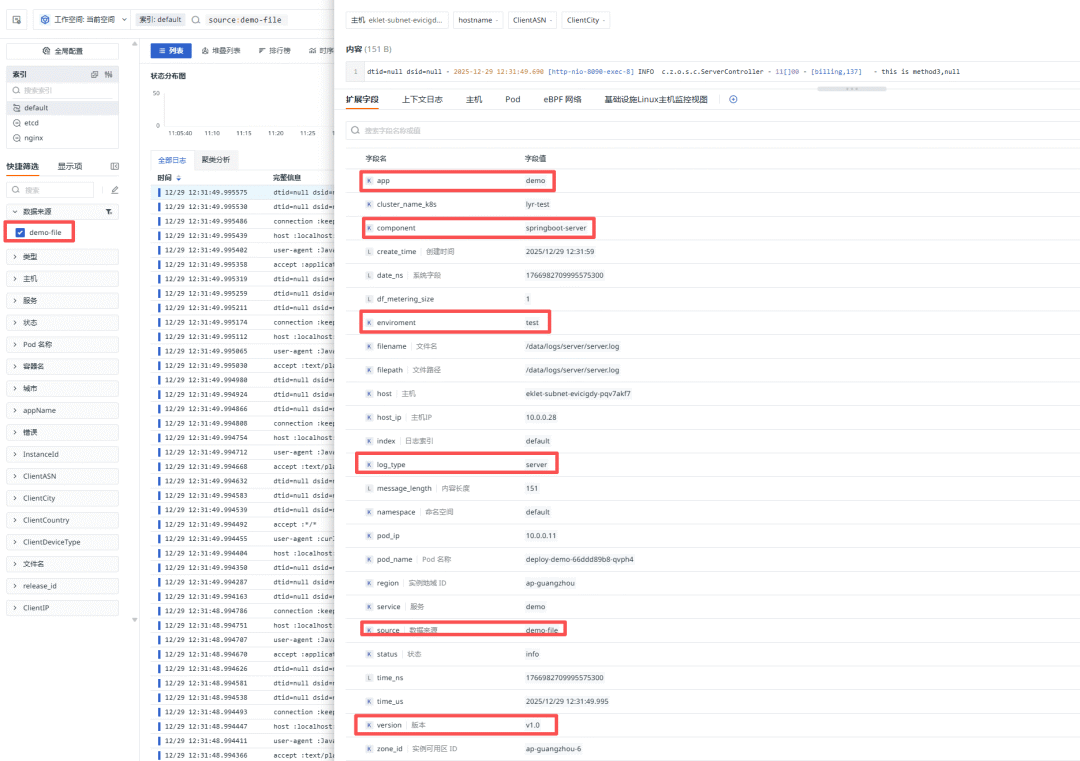
- 最终,容器内的日志数据会成功上报到观测云平台。在观测云的控制台,你可以筛选
source 为 demo-file 的日志进行查看。从下图中可以看到,CRD 配置中定义的字段(如 log_type、component 等)都已作为标签成功展示。
至此,一套基于 Kubernetes CRD 的 Serverless 容器内日志采集方案就完整部署并验证成功了。这种方法将复杂的日志采集配置统一抽象为 Kubernetes 原生资源,大大简化了在动态 云原生 环境中的运维管理。如果你在实践过程中遇到其他 运维 相关的问题,欢迎到云栈社区的对应板块与大家交流讨论。
 发表于 2026-3-12 02:06:27
|
查看: 147|
回复: 0
发表于 2026-3-12 02:06:27
|
查看: 147|
回复: 0
