临床决策是一项需要融合多源异构证据的复杂认知活动。近日,南加州大学的研究团队在 arXiv 上发布了一项引人注目的研究成果—— MED-COPILOT 系统。该系统通过结合指南驱动的 GraphRAG 检索与混合语义关键词相似患者检索,旨在为临床医生和医学生提供一个透明、可循证的临床决策支持工具。其在包含 36000 例患者的结构化数据库上验证,并在临床笔记生成和医学问答任务中表现优异,为构建更可信赖的 临床决策支持系统 提供了新思路。

图:MED-COPILOT 论文封面及系统核心功能概览
研究背景:临床AI的现实困境与可能的突破口
尽管大型语言模型在通用领域的推理能力令人瞩目,但直接将其应用于严肃的医疗环境仍面临巨大挑战。幻觉问题、置信度校准偏差以及缺乏可验证的证据基础,这些都阻碍了 LLM 在临床环境中的可靠应用。
业界逐渐形成一个共识:安全可信的医疗 AI 必须依赖外部临床证据的显式检索,而非仅仅依靠模型的参数化知识。检索增强生成框架部分回应了这一需求,但传统的 RAG 方法通常在扁平的、非结构化的语料库上运行,难以建模临床推理所必需的关系和层次结构。更关键的是,临床决策中一个核心环节——通过与相似患者进行类比推理——在现有系统中往往被忽视。
核心贡献:三项关键创新
该研究团队提出了一个统一且可解释的框架,在一个流程中整合了基于图谱的指南检索、混合相似患者检索以及大语言模型推理。
- 首个统一框架:首次系统性地将图结构化的指南检索与相似患者检索结合到一个临床决策支持系统中,实现了权威知识与临床经验的双重支撑。
- 构建标准化临床证据资源:策划了包含 118 条 WHO 指南和 525 条 NICE 指南的语料库(超 4000 万 token)。同时,维护了一个包含 36000 例结构化患者病例的存储库,为检索提供丰富基础。
- 实证性能提升与开放系统:在多项医学推理任务中验证了方法的有效性,并将完整的交互式系统部署在 HuggingFace Space,支持可复现的临床推理工作流。
系统架构:双管齐下的证据检索
MED-COPILOT 系统支持两种输入:标准 SOAP 格式的患者病例或自由文本的临床问题。输入之后,系统并行检索两种互补的证据:
- 图结构化的指南知识:编码了多步临床逻辑,如治疗路径、禁忌症等。
- 临床相似患者病例:捕获了在真实或模拟诊疗轨迹中呈现的类比模式。

图 1:系统工作流程概览,展示了从相似患者病例和图结构化临床指南中并行检索证据以支持推理的过程。
检索到的证据会被聚合,并明确标注来源,以支持下游推理和用户审查,这种透明度是建立临床信任的关键。
指南增强检索:将权威知识图谱化
为确保证据的可靠性与临床安全性,系统的所有指南知识均来源于 WHO 和 NICE 这两个国际公认的权威机构。这些长篇幅、结构复杂的指南文档首先被分割成语义连贯的文本单元(对应单个建议或临床场景)。
每个文本单元都使用医学命名实体识别和领域适配的 LLM 提示进行实体和关系抽取,进而构建成一个临床知识图谱。实体被标准化到 SNOMED-CT、ICD-10 等标准医学词表,关系和约束也被显式编码,且所有图谱元素都与其来源的指南部分保持链接。

图 2:GraphRAG 模块的详细构建和检索流程,包括文本分割、知识图谱提取、索引和混合检索步骤。
为了在细粒度建议和高级别指南逻辑之间实现高效检索,研究团队采用了混合索引策略,将指南文本单元、图谱社区摘要和实体描述嵌入后存储在向量数据库 LanceDB 中。
相似患者检索:36000例病例中的临床智慧
相似患者检索基于一个精心策划的、包含 36000 个结构化患者病例的存储库。为确保数据的临床真实性与多样性,该库融合了两个来源:
- MIMIC-IV 重症监护数据库:包含 18000 例经过去标识化处理的真实 ICU 就诊记录,并通过规则引导转换为标准 SOAP 格式。
- Synthea 合成患者生成器:生成了 18000 条额外的患者轨迹,模拟纵向疾病进程,并以相同的 SOAP 规范重写以实现结构统一。
识别临床相似患者需要兼顾严格的临床约束(如特定诊断)和整体轨迹的相似性。因此,系统采用混合检索公式,结合了强调离散临床信号(诊断、干预)的关键词对齐和捕获整体语义的嵌入相似度计算。
统一工作流与实验评估
在实际推理时,用户查询会并行触发语义向量检索和图谱关系检索。检索到的指南证据和相似患者病例被聚合并明确标注来源,形成一个统一的证据集供大语言模型使用并进行人工审查。
研究团队在临床笔记生成(基于 MIMIC-IV)和医学问答(MedQA, MMLU-clinical)任务上评估了该框架。他们与强大的纯参数 LLM 基线(DeepSeek-Chat, GPT-4.1-mini, Gemini 2.5)以及标准的 RAG 方法进行了对比。
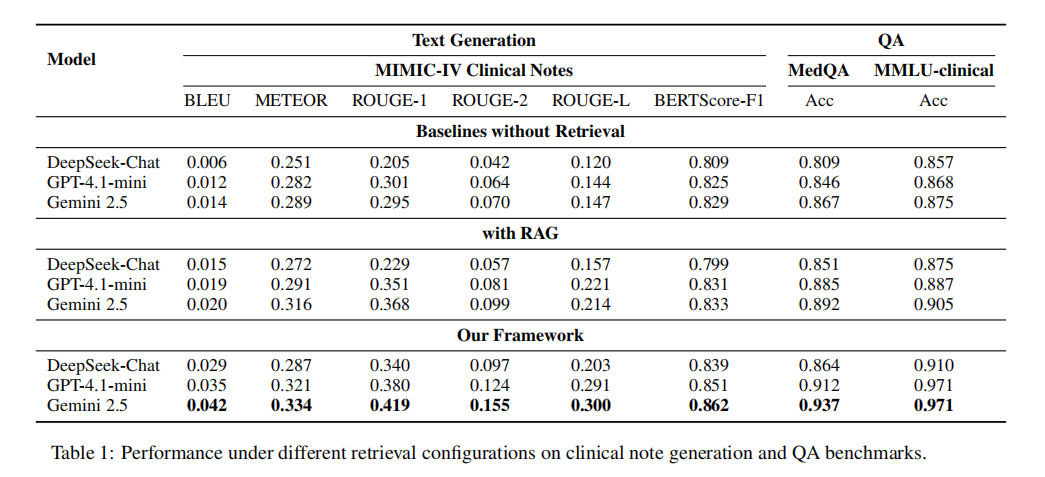
表 1:在不同检索配置下,临床笔记生成和问答任务的性能对比。结果显示,检索增强能一致提升性能,而结合相似患者检索和 GraphRAG 能带来最强效果。
消融实验进一步证实了每个组件的贡献:
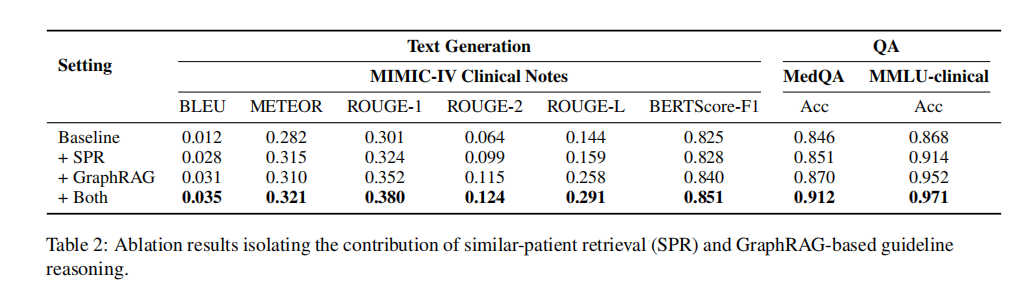
表 2:消融实验结果。相似患者检索和基于 GraphRAG 的指南推理均能独立提升性能,而组合框架实现了最大增益。
交互式系统演示
为了让研究成果更易于访问和验证,团队在 HuggingFace Space 上部署了一个公开的交互式系统。
系统访问地址:https://huggingface.co/spaces/Cryo3978/Med_GraphRAG
该系统提供了端到端的临床探索界面,核心功能包括:
- 双重证据控制:用户可以自由选择启用或禁用“相似患者”或“指南知识”任一证据源,进行可控推理。
- 患者病例输入与锁定:允许用户输入或锁定一个患者病例作为持续查询的上下文。
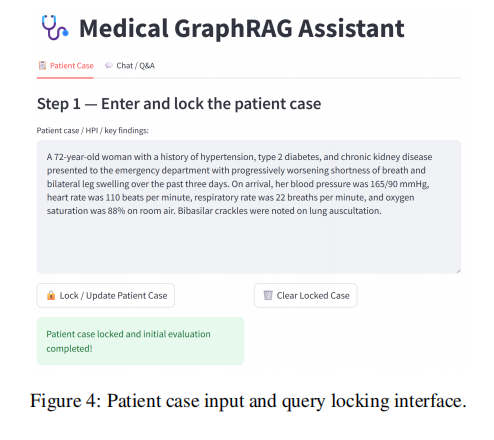
图 3:患者病例输入和查询锁定界面。
- 查询条件显著性高亮:在检索出的相似患者病例面板中,系统会根据当前查询自动高亮相关的临床概念(黄/红色),帮助用户快速定位关键信息。

图 4:从病例库中检索到的最相似患者病例,临床显著属性根据与查询的相关性被高亮显示。
局限性与未来展望
研究团队也坦诚地讨论了当前工作的局限性:
- 数据异质性:病例库融合了真实和合成数据,其分布仅部分反映了真实世界临床文档的复杂性。
- 知识抽象损失:将叙述性指南转化为结构化图谱时,可能丢失原文中的某些上下文细微差别。
- 原型定位:该系统是研究原型,旨在支持决策和证据审查,而非用于自主临床诊断。
- 评估范围:目前缺乏用于评估患者水平相似性检索的金标准数据集。
未来工作将专注于扩展指南覆盖范围、集成不确定性感知推理机制,并探索在真实临床工作流中的部署可能性。
结论
南加州大学的 MED-COPILOT 系统展示了一个将权威指南知识与临床经验(以相似患者病例形式)深度融合的可行路径。通过提供一个统一、透明、可解释的框架,它使临床医生能够在一个平台上便捷地检索、比对和推理来自不同维度的证据。实验结果证明了这种双重证据整合策略的互补优势,为构建下一代安全、可信、实用的临床 AI 辅助工具树立了一个值得参考的范例。对这类结合前沿人工智能与严肃医疗需求的研究,技术社区始终保持高度关注。如果你对 GraphRAG、RAG 应用或更多人工智能在垂直领域的落地实践感兴趣,欢迎在 云栈社区 与同行深入交流。
原文信息
- 论文标题: MED-COPILOT: A Medical Assistant Powered by GraphRAG and Similar Patient Case Retrieval
- 作者: Shuheng Chen, Namratha Patil, Haonan Pan, Angel Hsing-Chi Hwang, Yao Du, Ruishan Liu, Jieyu Zhao
- 机构: 南加州大学
- arXiv 链接: https://arxiv.org/abs/2603.00460
- 提交日期: 2026 年 2 月 28 日
本文基于 arXiv 论文翻译整理,仅供学术交流参考。该系统为研究原型,不应用于实际的临床诊断或治疗。
 发表于 2026-3-12 04:43:36
|
查看: 231|
回复: 0
发表于 2026-3-12 04:43:36
|
查看: 231|
回复: 0
