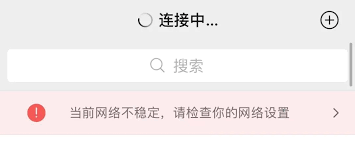
3月29日凌晨,腾讯旗下的微信、QQ等业务出现了功能异常,包括微信语音对话、朋友圈、微信支付,以及QQ文件传输、QQ空间和QQ邮箱在内的多个功能无法使用。
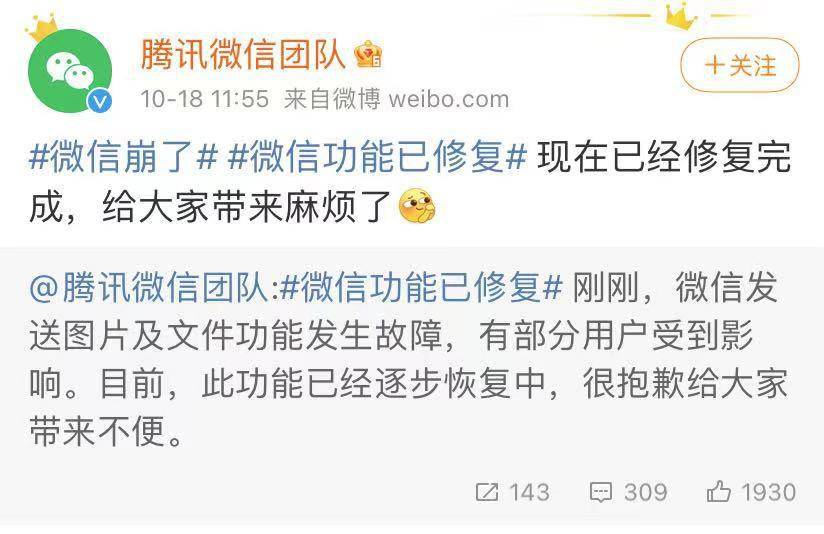
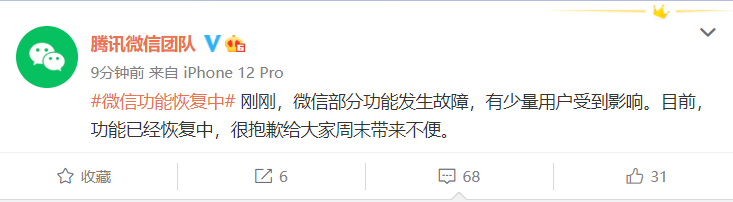
事故原因:广州电信机房冷却系统故障导致
腾讯将其定义为公司一级事故,多名相关高管被处理。

作为普通用户,我们可能对微信、QQ短暂的宕机感受不深。发不出消息,大不了就等一等,或者切换到其他通讯软件应急。我自己就曾经历过一次微信宕机,那天和朋友用支付宝聊了整整一天。
但如果故障发生时,你正处在一个关键的人生时刻呢?比如下面这种情况,恐怕就没人能淡定了,必然会对腾讯发出一连串“亲切问候”。

从本次事故了解互联网的事故等级
在互联网行业,事故通常会根据其严重程度和影响范围被划分为不同等级,以便于进行定责、复盘和后续的运维改进。
以下是业内比较常见的事故等级划分方式:
一级事故(重大事故)
一级事故通常指对用户数据安全、公司核心基础设施、关键业务等产生全局性或严重性影响的事件。
典型的例子包括:大规模数据泄露、严重的网络攻击导致核心系统瘫痪、关键业务服务长时间中断等。
这类事故往往会导致公司业务严重受阻、大规模用户流失、重大财务损失,并对公司声誉和市场地位造成难以挽回的打击。
尤其需要注意的是,任何涉及到支付、交易等资金往来功能的核心故障,几乎都会被自动定义为一级事故! 因为这类故障直接关系到用户的钱袋子,是信任和安全底线。
例如,2017年,微信支付就曾因功能漏洞导致用户资金风险而受到广泛关注和质疑。
本次腾讯的事故就明确属于关键业务服务中断。微信首先是一款即时通讯软件,因此其语音对话、朋友圈等核心社交功能中断,再加上微信支付这一金融功能异常,足以构成最高级别的事故。
二级事故(较大事故)
二级事故通常指对公司的业务运营和用户体验产生了较大范围影响,但尚未触及核心根本的事件。
例如:中等规模的数据泄露、部分非核心业务服务中断、全站性系统性能显著下降导致体验卡顿等。
这类事故可能导致业务暂时受限、引发大量用户投诉、增加合规风险,需要团队紧急响应和处理。
再用微信举例:如果你发现聊天消息发送缓慢、总是转圈圈,或者“语音转文字”、“拍一拍”等附加功能集体失灵,但基础聊天尚可进行,这就可能被界定为二级事故。

三级事故(一般事故)
三级事故通常影响范围有限,针对公司的业务和用户产生的影响处于一般水平。
例如:个别用户的数据错乱或泄露、某个次要服务接口的局部故障、发现中低危的产品安全漏洞等。
三级事故虽然会引起一部分用户的困扰和内部团队的紧张,但通常可以通过既定的预案和流程快速控制并解决。
四级事故(轻微事故)
四级事故通常指那些影响范围极小、易于处理、对整体业务和用户感知影响轻微的事件。
例如:零星的用户功能投诉、非关键路径上的产品体验瑕疵、某个运营活动页面的显示异常等。
这类事故更像是日常运维中的“小插曲”,通过及时响应和处理,基本可以避免其发酵成更大的问题。
事故预防:我们能做什么?
对于事故,我们的态度永远是“预防大于治疗”。虽然没有任何系统能保证100%不出问题,但通过体系化的工作,可以极大降低事故发生的概率和影响。以下是一些核心的预防措施:
- 构建健壮的网络与基础设施防御体系:包括合理的防火墙策略、入侵检测/防御系统(IDS/IPS)、DDoS缓解方案等。
- 落实完善的数据备份与灾备计划:定期备份关键数据,并建立跨地域、跨可用区的容灾切换机制,确保业务连续性。
- 建立全方位的业务监控和预警机制:对核心应用、数据库、服务器、网络链路等进行多维度监控,设置合理的阈值告警,做到问题早发现、早定位。
- 定期进行员工安全培训和意识教育:很多事故源于人为操作失误,通过培训可以有效防范此类风险。
- 严格遵守合规要求:遵循国家法律法规及行业安全规范,这是企业生存的底线。
- 加强设备和基础设施的运维管理:包括机房、服务器、网络设备等的定期巡检、维护和生命周期管理。本次腾讯事故正是源于底层基础设施(机房冷却)的故障。
- 制定并演练应急预案:针对可能发生的各种故障场景,提前制定详细的应急响应流程(SOP),并定期进行演练,提升团队的实战能力。
- 管理好第三方供应商风险:评估并监控供应链中合作伙伴(如云服务商、IDC机房)的稳定性和安全性。

技术的发展让我们的数字生活无比便利,但背后支撑这一切的系统却异常复杂。每一次“岁月静好”的背后,都有一群工程师在努力维系着系统的稳定。对事故等级的清晰界定和严肃处理,体现的正是科技公司对用户负责的态度。如果你对这类系统稳定性保障、故障复盘等话题感兴趣,欢迎到云栈社区的运维与架构板块,和更多同行一起交流探讨。
 发表于 2026-3-15 10:09:12
|
查看: 174|
回复: 0
发表于 2026-3-15 10:09:12
|
查看: 174|
回复: 0
