3月18日晚,Minimax悄然更新了其最新的M2.7模型版本。官方为其赋予了一个核心定义:M2.7是MiniMax第一代深度参与自身进化的模型。
此次升级不仅在指令遵循、办公协同、编程方面有显著提升,其更重要的突破在于能够自主搭建Agent Harness。这意味着,M2.7可以搭建一套完整的任务框架,调用多种技能和工具,解决单个模型难以处理的复杂问题,实现了思考与执行的结合,展现了“自我进化”的潜力。
官方同时提供了可验证的测试数据。在MLE Lite包含的22道高难度竞赛题测试中,M2.7取得了9金5银1铜的成绩,综合表现仅次于Opus-4.6和GPT-5.4,与Gemini-3.1持平。
此外,在行业当前最关注的Agent真实任务执行能力评测——基于标准化OpenClaw Agent测试的PinchBench榜单中,新发布的M2.7迅速攀升,以86.2%的任务成功率击败英伟达Nemotron 3,拿下了Best score榜单的全球第四名,仅次于Claude Sonnet 4.6、GPT-5.4和Claude Opus 4.6,刷新了国内大模型在该榜单的最好记录。
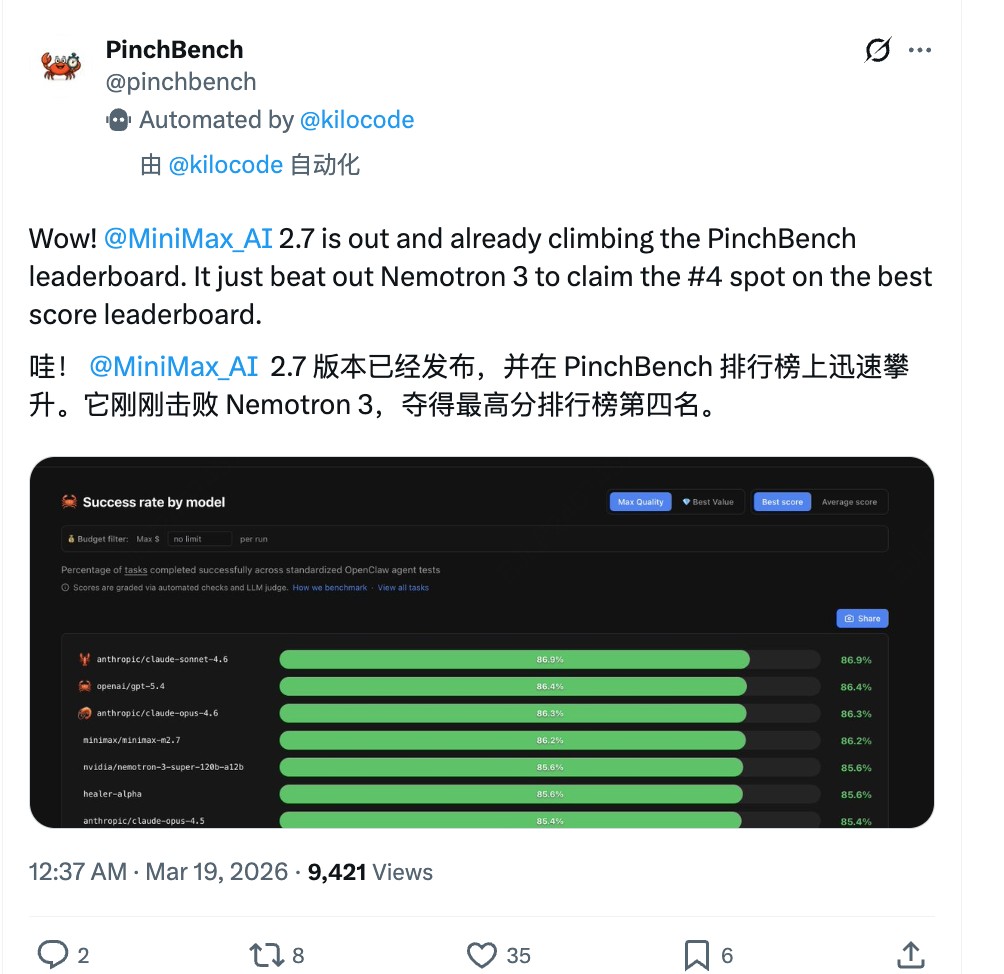
此次更新距离M2.5发布仅过去一个月。接连刷新的榜单和肉眼可见的能力跃升,都在印证一个趋势:大模型的能力边界正在从基础的答题、编程,向自主规划与自主迭代进化。
尤其是在OpenClaw生态引发广泛关注后,业界评估的重点已不再是模型能否写代码,而是其接入真实工作流后的实用性与稳定性。核心在于,当模型与工具串联执行任务时,能否保持连贯、可靠,不“掉链子”。
我们第一时间对M2.7进行了上手评测。本次评测的核心目标是:验证接入OpenClaw后,M2.7的真实体验究竟如何?它是否是目前国内最好的协同工作Agent?

长链路任务的稳定性,才是真分水岭
近期OpenClaw的热度有目共睹。如今将模型接入框架已不新鲜,真正开始拉开差距的,是接入后的实际表现。短平快的任务中,许多模型尚可应对;一旦开始挂载技能、叠加约束、拉长任务流程,问题便暴露无遗:前期条件理解不透彻,后续补充指令易混乱,任务执行中途可能直接中断。
OpenClaw的设计初衷正是为了串联模型、工具与任务链路,因此在该环境中进行测试,反而能更清晰地检验一个模型的可靠性。
第一个测试任务是一道约束条件众多的活动策划题,涉及预算、目标人群、渠道、门店承载量、风险及备选方案等多个限制,重点考察模型能否先梳理清楚条件,再进行任务拆解。
M2.7在这一步的表现令人满意。它没有急于发散思维,而是先提取所有约束条件,再分解任务,最后给出方案。这种起手方式显得更为可靠。这也正是M2.7本次升级的核心强化方向——复杂长链路任务的承接与落地,实测表现的确不俗。
接着,我们将任务进一步拉长。先给出一个基础方案,然后逐轮增加条件:预算不能打折、供应链能力有限、门店人手不足、目标人群变化,最后附加一个更贴近真实业务的要求——希望该活动方案能沉淀为下个月可复用的SOP。
在整个过程中,M2.7没有出现许多模型常见的“一加新需求就推倒重来”的问题,始终能沿着初始的核心逻辑进行持续优化和迭代,这对于长流程工作流至关重要。虽然在第三轮迭代中出现过短暂卡顿,体现出超长链路中仍有小幅波动,但在追问后,它快速补齐了所有内容,包括最小可复用版本、标准化执行环节、人工决策节点,完整承接了需求,没有出现信息遗漏。
完成这两组全链路任务测试后,M2.7在OpenClaw中的表现已非常清晰:其核心价值并非单轮输出多么惊艳的答案,而在于任务启动时逻辑清晰、链路拉长后不易散架、多轮迭代中不丢约束。在真实工作流中,这种稳定的持续交付能力远比单次的华丽输出重要得多。在复杂长链路任务的承接上,M2.7交出了一份符合“国内最好Cowork Agent”期待的答卷。
代码能力全场景验证:从“写代码”到“做项目”的工程化跃升
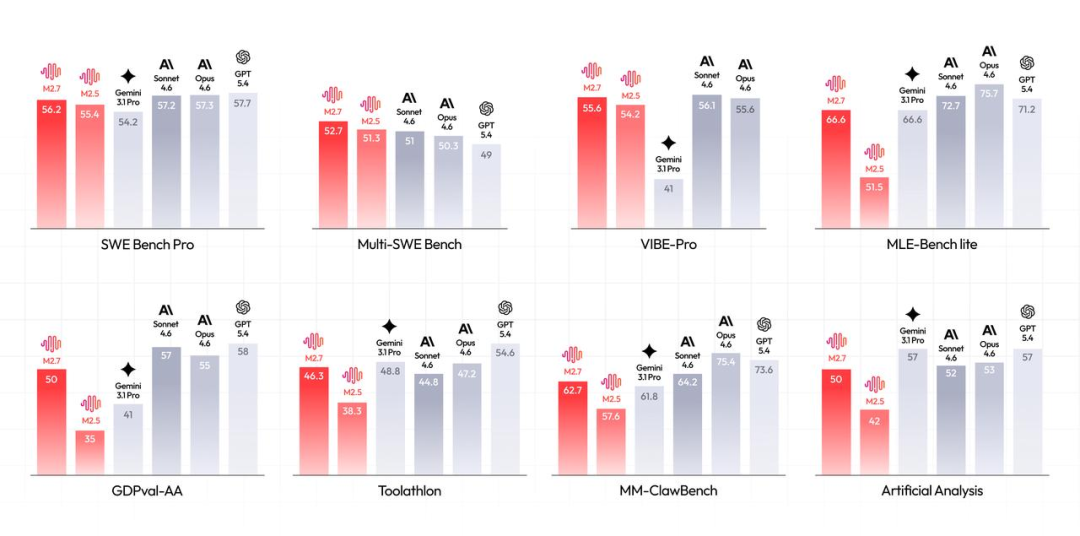
要真实评估编程能力,还需将完整项目丢给模型。MiniMax本次公开的能力方向中,Coding被置于更重要的位置。官方数据显示,在SWE-Pro基准测试中,M2.7得分56.22%,无限接近Claude Opus的顶级水平;在端到端完整项目交付的VIBE-Pro测试中得分55.6%;在复杂工程系统理解的Terminal Bench 2测试中得分57.0%。更重要的是,其能力已从单纯的代码生成,延伸到了日志分析、Bug定位、故障排障、工程重构等高阶开发领域,这种变化在实测中感受极为直观。
在前端测试环节,我们提出了一个品牌展示官网的全量开发需求。这个任务的难点不在于简单的页面拼接,而是需要同时满足品牌调性、视觉配色、页面节奏、交互动效、粒子特效等多个维度,最终产出的是一个真正可商用的官网。许多模型容易在此翻车。
M2.7的表现超出了预期,尤其是在配合官方Skill协同运行时,页面完成度直接拉满,毫无常见的模板化痕迹。视觉层次、品牌配色、交互动效高度统一,最终交付的是一个可直接上线使用的完整站点,而非零散的代码片段。
在后端测试环节,我们交给M2.7的不是修补几段接口代码的小任务,而是一个从零开始搭建的真实项目。技术栈涉及Python、FastAPI和PostgreSQL,内容涵盖接口设计、数据模型、鉴权、迁移、测试、文档及后续排障。这类任务的真正难点不在于代码量,而在于上下文必须始终保持一致,前期定好的架构,后续每一步都不能偏离。
M2.7这一轮最令人惊喜的是,它在连续工程任务中展现出更接近资深开发者的项目管理思维,而非单纯的代码生成工具:先搭建完整的项目骨架,再逐层补齐数据库设计、业务接口、测试用例和接口文档。项目上线跑通后,遇到问题还能自主排查、快速修复,全程逻辑连贯,没有出现任何架构跑偏或上下文脱节的问题。
M2.7在编程能力上最明显的变化,并非某个单点能力突然爆发,而是工程感显著增强。前端开发能向最终展示效果收敛,后端开发能按项目节奏持续推进。当下,模型会写代码已不稀奇,真正有价值的是项目跑起来之后能否持续跟进。从这一点来看,M2.7已不再只是一个代码生成模型,而是在向真正能参与开发流程的Cowork Agent演进。这种工程参与感,在国内同类模型中并不多见。
办公自动化全链路考验:覆盖完整知识工作流的协同能力
在办公自动化测试中,我们未使用简单表格,而是直接设计了一条完整链路:首先生成一套模拟企业经营数据,接着基于数据制作复杂金融图表,最后将图表与数据分析整理成一份网页数据报告。这里测试的已不是是否会写公式,而是数据、图表、分析与展示能否串联成一套完整的成果。
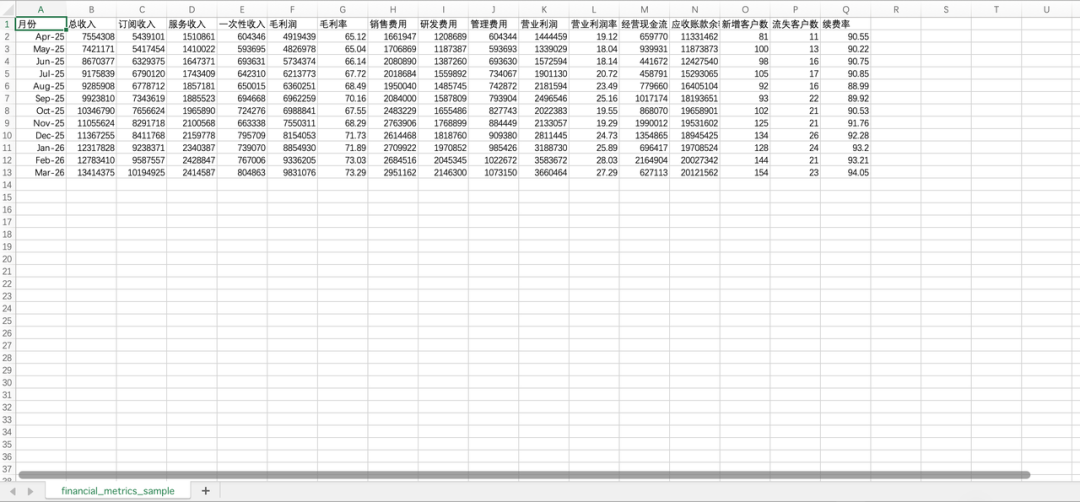
M2.7这一轮表现扎实。数据生成并非随意拼凑数字,收入、利润率、现金流、营收等关键指标间存在基本逻辑关联;图表也不是简单的折线图,而是将多个关键经营指标整合到同一分析视图中,信息密度与重点突出。在继续制作网页报告时,它并未止步于贴图,而是将核心结论、风险点和管理建议一并整理,最终形成了一份可直接用于演示的页面,而非一堆零散素材。
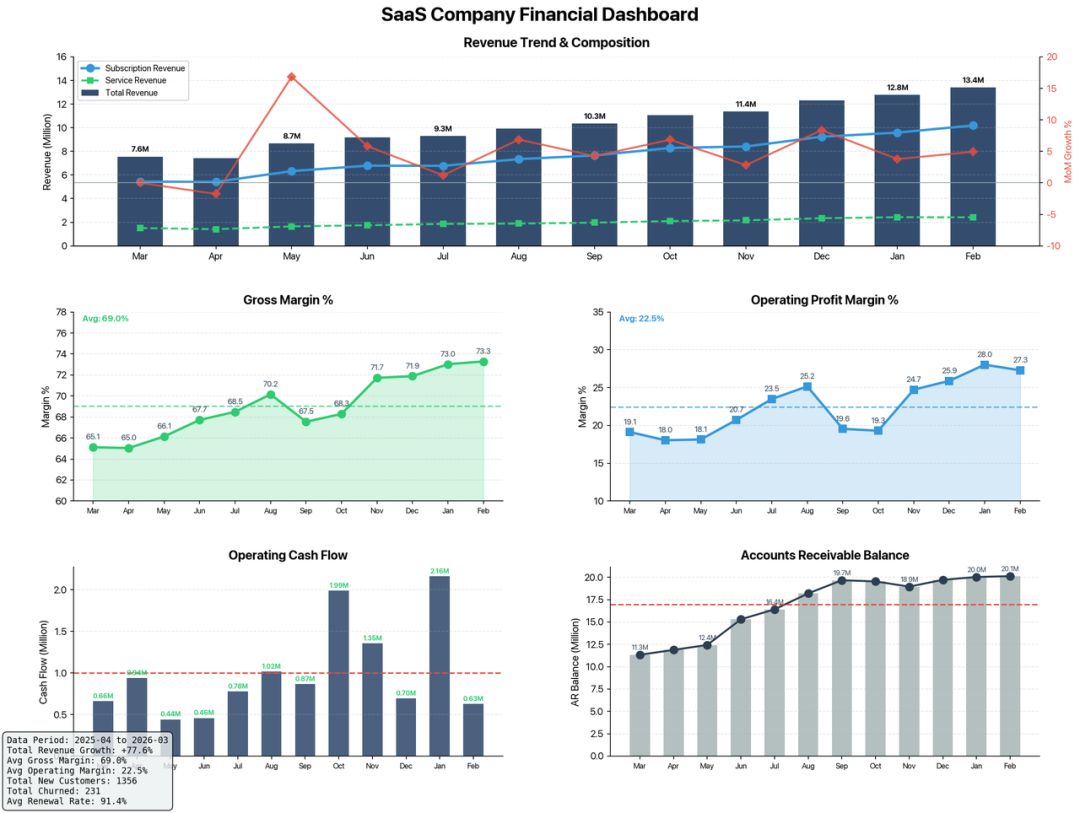
M2.7展现出的,已不再是基础的表格处理能力,而是复杂的Office自动化全链路能力。从数据清洗、图表生成,到分析归纳、汇报整理,这一整条链路它都能持续推进,即便经过多轮修改,整体结构也未明显散架。置于真实办公场景中,这种表现比单独擅长Excel或写报告更有参考价值,因为它开始覆盖的是更完整的知识工作流程。
从能力边界看,M2.7的能力已不限于办公整理层面。它不仅能完整落地企业经营分析全链路任务,对于资料归纳、研究链路梳理、专业分析与结果汇总这类更高阶的知识工作,也能胜任。
最佳Cowork Agent来了吗?
经过本轮全面测试,M2.7最明显的感受已不止于编程能力的提升,真正拉开差距的地方,在于其对智能体工作流的支持更为完整。尤其是在接入OpenClaw后,这种变化尤为明显。交付任务后,它不止于提供一段回答,很多时候能真正顺着任务逻辑持续推进,且过程中不易偏离主线。仅凭这一点,就足以将M2.7定位为国内当前最好的Cowork Agent。
如果用几句话概括M2.7此次最值得关注的亮点,核心在于连续性、稳定性和落地感。
不过更值得注意的是,它已开始显现出自我迭代的能力。
官方给出的技术路径很清晰:不仅是让模型调用Agent Harness来执行任务,更是让其基于短时记忆、自反馈和自优化机制,反复调整任务执行方法。在内部脚手架优化任务中,M2.7可以连续运行超过100轮,分析失败轨迹、规划改动、修改代码、回跑评测、对比结果,再决定保留或回退,内部评测效果提升达30%。在更复杂的机器学习任务中,其在MLE Bench Lite的22个任务上取得了9金5银1铜的成绩,平均得牌率66.6%。这表明它已不仅是任务的执行者,也开始参与到优化任务完成路径的过程中。
当下整个行业都在积极适配OpenClaw,专注于教授模型如何使用人类打造的工具,却鲜少有人真正突破模型的能力边界——让模型自己创造工具、搭建框架、完成迭代进化。M2.7自主搭建Agent Harness的能力,本质上是赋予了模型自主打造“任务操作台”的能力。它不再局限于人类预设的工具与框架,而是能够根据任务需求,自主搭建完整的任务执行体系,调度多智能体协同作业,甚至能通过自反馈与自优化,持续迭代这套体系本身。
更重要的是,它已深度参与到MiniMax自身的模型研发流程中,成为了下一代模型研发的核心参与者,真正实现了“模型训练模型”的正向循环。这种自我迭代的技术创新,不仅让M2.7坐稳了国内最好Cowork Agent的位置,更提前抢占了下一代大模型竞争的核心高地,开启了大模型自主进化的新阶段。
显然,M2.7更适合那些已不满足于简单问答的用户。独立开发者、全栈工程师、产品型开发者,或本就习惯于将模型接入自身工作流的从业者,将更容易感知到其价值。因为这类用户真正关心的,从来不是模型能否说出几句聪明话,而是它能否拆解任务、持续推进、在遇到问题时修正方向,最终交付可靠成果。
借助M2.7,我们似乎窥见了最强Cowork Agent应有的模样。或许在未来,我们将能看到AI承接更复杂、更艰巨的任务。
如果你目前正在关注OpenClaw生态,或正在寻找一款接入后足够顺手、足够强大、能真正融入工作流的大模型,M2.7绝对值得你亲自上手实测。
体验地址:
MiniMax Agent: agent.minimaxi.com
Token Plan订阅: https://platform.minimaxi.com/subscribe/token-plan
欢迎前往云栈社区探讨更多关于AI Agent与模型应用的前沿实践。
 发表于 2026-3-20 11:22:49
|
查看: 164|
回复: 0
发表于 2026-3-20 11:22:49
|
查看: 164|
回复: 0
