你一定经历过这样的场景。
大促前夜,团队信心满满。缓存集群扩到了50个节点,总吞吐量远超预估峰值。限流阈值也调好了,全局QPS上限设得很保守。一切就绪,等着流量洪峰到来。
然后,开场30秒,某个爆款商品详情页的缓存节点CPU飙到100%,连接队列爆满,响应超时。你一看监控:集群整体QPS才用了40%,大部分节点很闲。但那一个节点,已经被打穿了。
全局限流没有任何反应,因为总量根本没到阈值。
问题出在哪?不是总量不够,而是流量集中在了少数几个Key上,限流却对此一无所知。
这就是今天要聊的话题:热点限流。从全局到精准,限流策略的粒度需要跟着QPS量级一起演进,这也是构建千万级QPS系统时必须面对的挑战。
热点,一个被低估的缓存杀手
在聊限流之前,先理解一下「热点」到底是什么。
缓存中的访问分布,几乎从来都不是均匀的。它遵循一个经典的幂律分布:少数Key承担了绝大多数的访问压力。在实际业务中,Top 1%的Key往往承担了超过50%的流量。
这个分布在低QPS场景下不是问题。假设你的系统跑在10万QPS,Top 1%的Key大概承受5万QPS,分散到几个节点上,每个节点几千到一两万QPS,Redis轻松消化。
但当总QPS到了千万级别,Top 1%的热点Key可能集中承受500万甚至更多的QPS。单个Key只落在一个分片上,无论你加多少节点,这个分片的压力不会被分摊。
热点问题在不同量级下的表现完全不同:
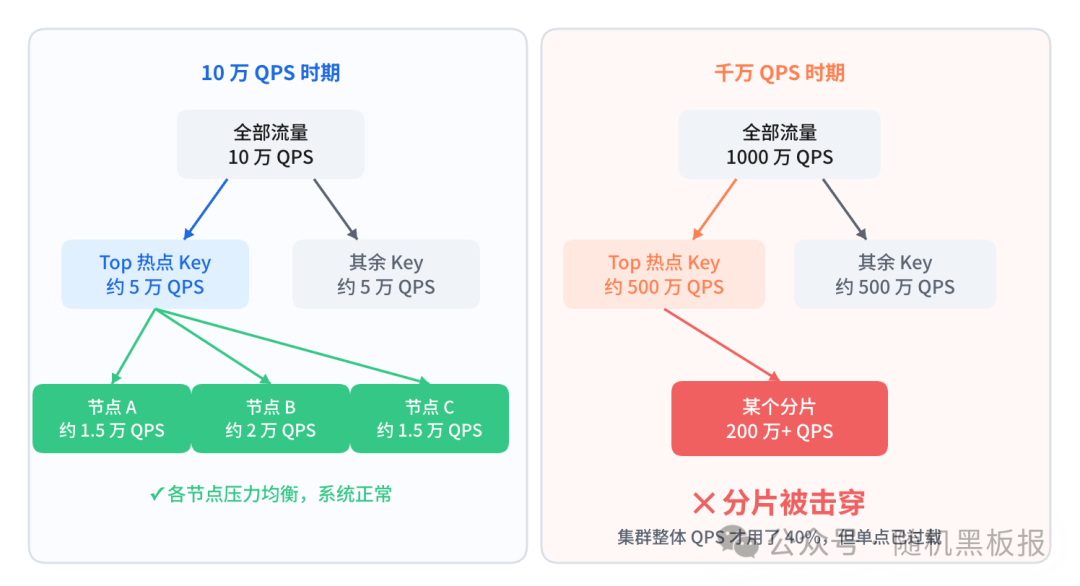
图1:10万QPS与千万QPS下,热点流量分布与节点压力的巨大差异
这就是热点问题的本质:缓存集群的瓶颈不在总容量,而在单分片的承载上限。你加再多的节点,也救不了那个被热点Key钉死的分片。这种单点压力问题,是迈向高并发系统时必须精细设计的部分。
全局限流为什么不够用了
理解了热点的本质,再来看限流策略。
最朴素的限流思路是全局限流:给整个缓存集群设一个总QPS上限,超过就拒绝。这在十万QPS级别完全够用,因为此时流量分布的不均匀还不足以击穿单个节点。
到了百万QPS,我们通常会细化到服务级或接口级限流。比如:商品详情服务限20万QPS,搜索服务限30万QPS。这一层粒度足以在服务间做流量隔离,防止某个服务把整个缓存集群的资源吃光。
但到了千万QPS,这两种策略都暴露了同一个盲区:它们只关心「谁在请求」和「请求总量」,却不关心「请求的是哪个Key」。
一个具体的例子:某明星突然官宣,其个人主页缓存Key瞬间被数百万用户同时访问。对全局限流来说,总QPS可能还没到阈值;对服务级限流来说,用户服务的总调用量也在限额内。但这一个Key对应的缓存分片,已经承受了远超设计容量的压力。
限流“看到了”流量,却“看不到”热点。

表1:全局限流、服务级限流与Key级精准限流的适用范围与盲区对比
从粗放到精准:限流策略的三级演进
如果把限流策略的演进画成一条线,你会发现它本质上是限流粒度不断细化的过程,而驱动这个演进的,正是QPS量级的增长。
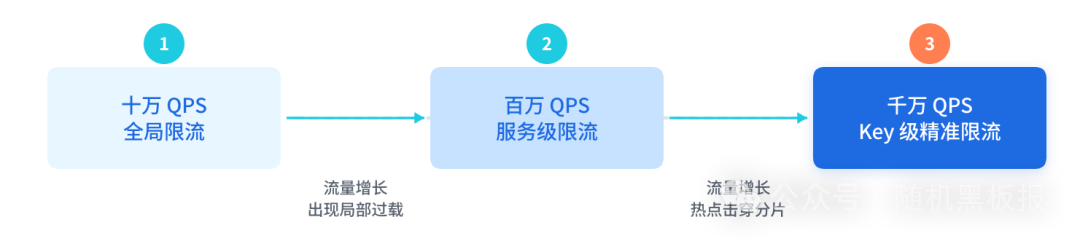
图2:随着QPS从十万到千万级增长,限流策略从全局走向精准的三级演进路径
第一阶段:全局限流,守住大门
在十万QPS级别,系统架构相对简单,缓存通常是单机或者小规模集群。此时的限流目标很明确:防止流量超过系统总承载能力。
实现方式通常是在网关层或接入层做一个全局计数器,超过阈值直接拒绝。这就像一栋大楼的安保,只管进大门的总人数,不管你去几楼。
在这个阶段,热点问题通常还不突出,因为即使流量分布不均,单节点也能扛住。
第二阶段:服务级限流,分区管理
当QPS增长到百万级别,系统拆分成了多个服务,缓存也变成了集群。此时全局限流的问题开始显现:A服务的流量暴增,把B服务的缓存配额也挤占了。
解决方案是引入服务级限流,也就是给每个服务、每个接口设独立的配额。这像是大楼里每层楼都有了门禁,不同楼层互不影响。
在这个阶段,热点Key的问题开始出现,但通常可以通过增加缓存副本、做读写分离来缓解。限流策略还不需要深入到Key维度。
第三阶段:Key级精准限流,精确打击
到了千万QPS,服务级限流也挡不住了。核心矛盾变成:你无法预知哪个Key会在下一秒变成热点。
这时需要的是一套能够实时发现热点Key并对其进行精准限流的机制。这不是简单地把限流阈值设小,而是一个从「发现」到「决策」到「执行」的完整闭环。
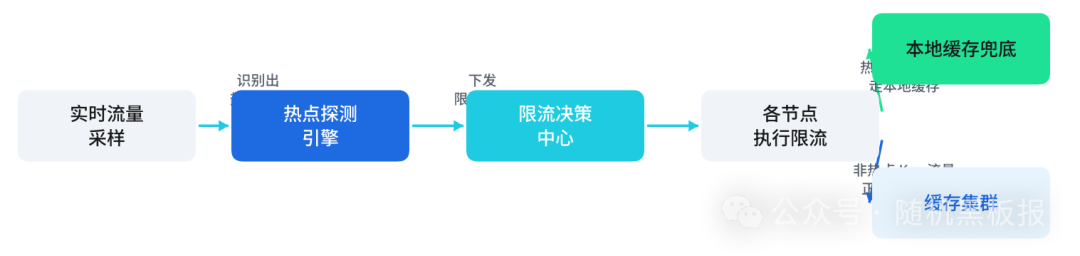
图3:实现Key级精准限流所需的“发现-决策-执行”完整闭环机制
精准限流的三个核心能力
实现Key级精准限流,需要三个相互配合的能力。
第一:实时热点探测,知道「谁」是热点
精准限流的前提是精准发现。如果你不知道哪个Key是热点,限流就无从谈起。
热点探测的核心挑战在于:千万QPS意味着每秒有上千万次访问,逐一统计每个Key的频次,内存和计算开销都不可接受。
业界主流的做法是利用概率型数据结构进行流式统计。比如用滑动窗口内的频次估算,或者基于Count-Min Sketch这类数据结构,在可控的内存开销下完成Top-K热点Key的识别。
这里有一个重要的设计取舍:热点探测不追求100%精准,而是追求「高召回 + 低延迟」。漏掉一个真热点,最多是某个分片压力大一点;但如果探测延迟太高,热点已经把节点打挂了你才发现,那就毫无意义了。
在实践中,通常采用「本地预聚合 + 中心汇总」的两级架构:
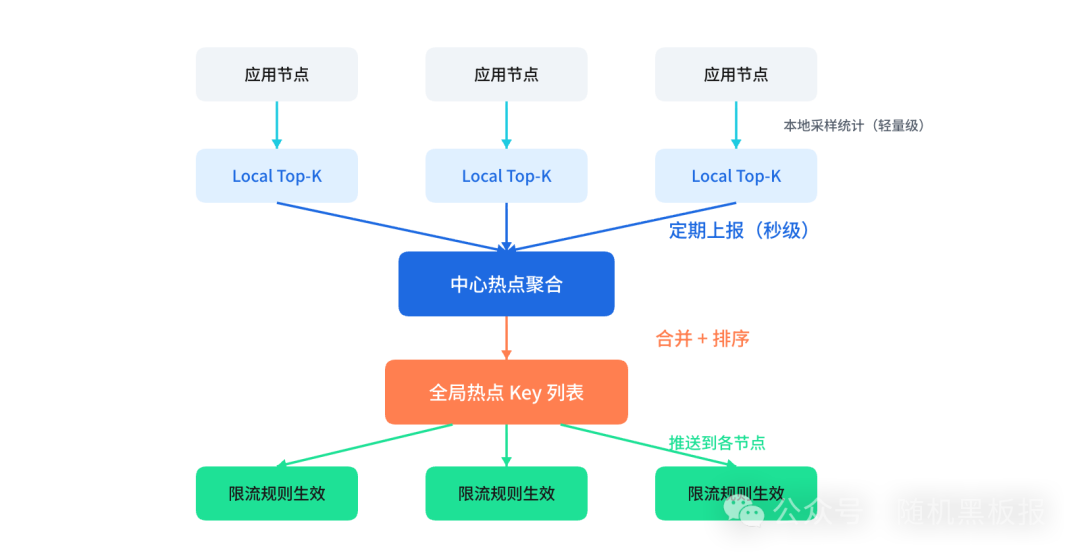
图4:本地Top-K预聚合与中心全局汇总的两级热点探测架构
每个应用节点在本地做轻量级统计,只把自己的Top-K上报给中心节点。中心节点做全局聚合,得出真正的全局热点列表,再推送回各节点。这样既控制了网络开销,也保证了秒级的探测时效。
第二:分级限流策略,决定「怎么」限
发现了热点Key之后,下一个问题是:限多少?怎么限?
这不是一刀切的事情。不同的热点Key背后的业务含义不同,限流策略也应该不同。
一种常见的做法是分级响应:

表2:根据热度等级制定差异化限流动作的分级策略
注意,这里的「限流」不一定是拒绝请求。对于读场景,更好的做法往往是把热点Key的数据缓存到应用本地内存,用本地缓存来承接流量,而不是简单地返回限流错误。好的限流是让用户无感知的,不是粗暴地返回429。
第三:本地缓存兜底,做好「最后一道防线」
精准限流的最终执行手段,在读场景下往往落到本地缓存上。
为什么?因为当一个Key的QPS达到百万级,任何远程调用都是开销。即使你的缓存集群扛得住,网络往返本身就是瓶颈。本地缓存把热点流量就地消化,从根本上消除了网络和远程节点的压力。
但本地缓存不是万能的,它引入了一个经典问题:数据一致性。热点Key的数据更新了,各个应用节点的本地缓存怎么同步?
这里通常的做法是:
- 短TTL:本地缓存设置非常短的过期时间,比如1到3秒,确保数据不会「过期太久」
- 主动失效:通过消息通知机制,在数据源更新时主动推送失效信号
- 容忍短暂不一致:对于大多数读场景,秒级的数据延迟是可以接受的
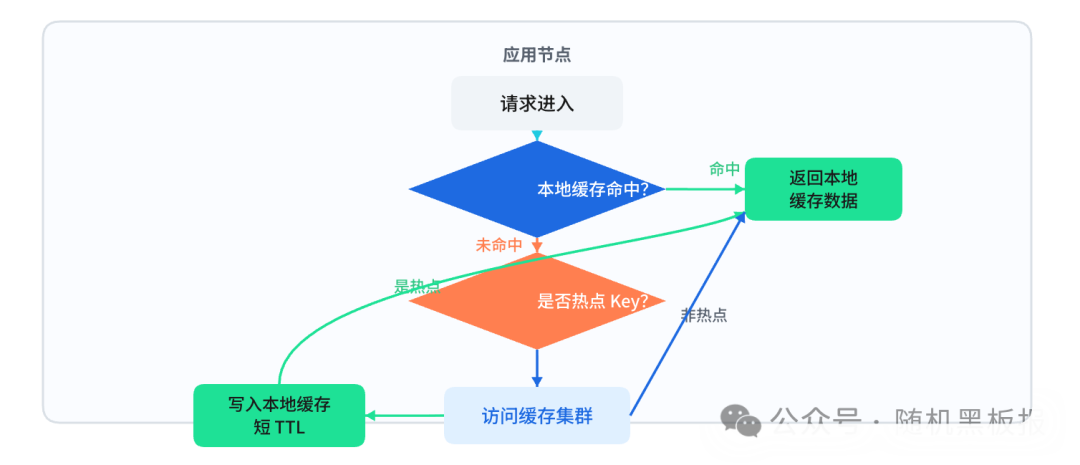
图5:应用节点通过本地缓存命中判断与热点识别来处理请求的流程
这里有一个容易踩的坑:本地缓存的容量管理。如果你不加限制地把所有热点Key都放进本地缓存,应用节点的内存会被撑爆。本地缓存需要严格的容量控制和淘汰策略,只缓存「真正的」热点Key,而不是所有看起来有点热的Key。这需要与Redis等远端缓存集群的策略进行联动设计。
写场景下的热点限流
上面讨论的主要是读场景。写场景的热点限流有所不同,因为写操作没办法用本地缓存来「吸收」。
对于写热点,核心思路是 「合并写入,削峰填谷」:
- 写合并:将短时间内对同一个Key的多次写入合并为一次,降低实际写入频率
- 异步化:将写请求放入队列,由后台线程批量处理
- 分桶打散:将一个热点Key拆分为多个子Key,分散到不同分片上,写入时随机选择一个子Key,读取时聚合
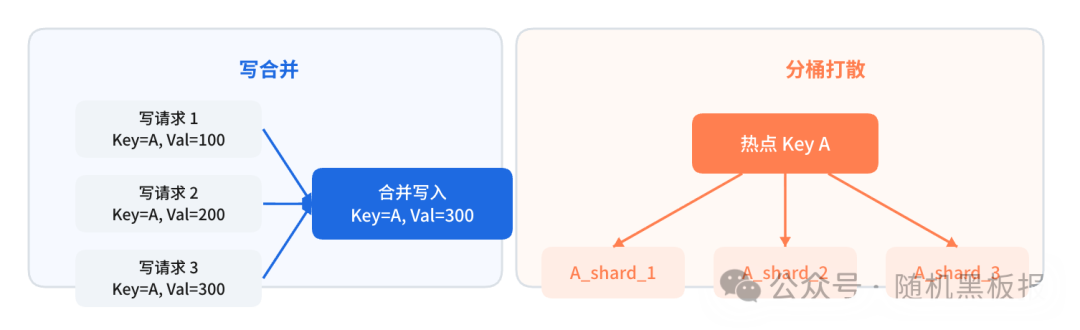
图6:处理写热点的两种核心策略:请求合并与分片打散
不过坦白说,写热点的处理比读热点复杂得多,涉及数据一致性、时序保证等问题,需要根据具体业务场景做取舍。这里不展开,后续可以单独聊。
一些实战中的思考
聊了这么多,最后分享几个我在实践中的体会。
精准限流不是万能药。它最擅长的场景是「突发热点」,比如爆款商品、热搜话题、直播间。对于那些可以预判的热点(比如首页Banner、核心配置),更好的做法是提前做缓存预热和本地缓存规划,而不是等热点探测系统去发现它。
限流粒度不是越细越好。Key级限流的探测、决策、执行都有成本。如果你的系统跑在百万QPS级别,服务级限流已经够用,没必要为了“架构先进性”强上Key级限流。限流策略的粒度应该跟系统的QPS量级匹配,而不是跟你的技术追求匹配。
监控先行。在上精准限流之前,先做好热点监控。你需要能回答这些问题:系统中有哪些热点Key?热度排名是什么?热点Key的QPS波动趋势如何?没有这些数据,任何限流策略都是在“盲打”。
这才是千万QPS的思维方式
回到开头的故事。那个被打穿的缓存节点,问题不在于集群容量不够,而在于限流策略太粗放,看不到Key维度的流量分布。
从全局限流到Key级精准限流,本质上是从「管总量」到「管分布」的思维转变。百万QPS的系统,管好总量就够了;千万QPS的系统,必须管好每一个分片、每一个热点Key的流量。
这也是「千万QPS不是百万QPS乘以10」的又一个例证:当量级跨越一个数量级,系统的瓶颈从「容量」转移到了「分布」,解题思路也需要从「堆资源」转变为「精细化治理」。
最后抛一个开放问题:如果热点Key的生命周期极短(比如只有几秒),探测系统的响应速度跟不上热点的产生和消亡,你会怎么设计?欢迎在云栈社区的技术论坛一起探讨。
 发表于 2026-3-21 04:05:37
|
查看: 114|
回复: 0
发表于 2026-3-21 04:05:37
|
查看: 114|
回复: 0
