数据库分页查询功能是处理大量数据时常用的技术,将结果集分成多个“页”返回,提高系统性能和用户体验。以下是关键要点:
- 性能优化:避免一次性加载全部数据,减少内存消耗和网络传输
- 提升响应速度:快速返回首屏数据
- 改善用户体验:支持逐页浏览大数据集
- 未分页的结果集一般比较大
- 页码小的查询快,随着页码增大,会越来越慢
YashanDB 23.5 针对分页查询场景进行了专项优化,核心是 Rownum/StopKey 的下推能力。本文基于真实测试环境,以 Oracle 19c 为参照系,从七类典型分页 SQL 入手,深入剖析执行计划、IO 消耗与耗时差异,揭示不同实现方式下的性能边界。

测试结果总览
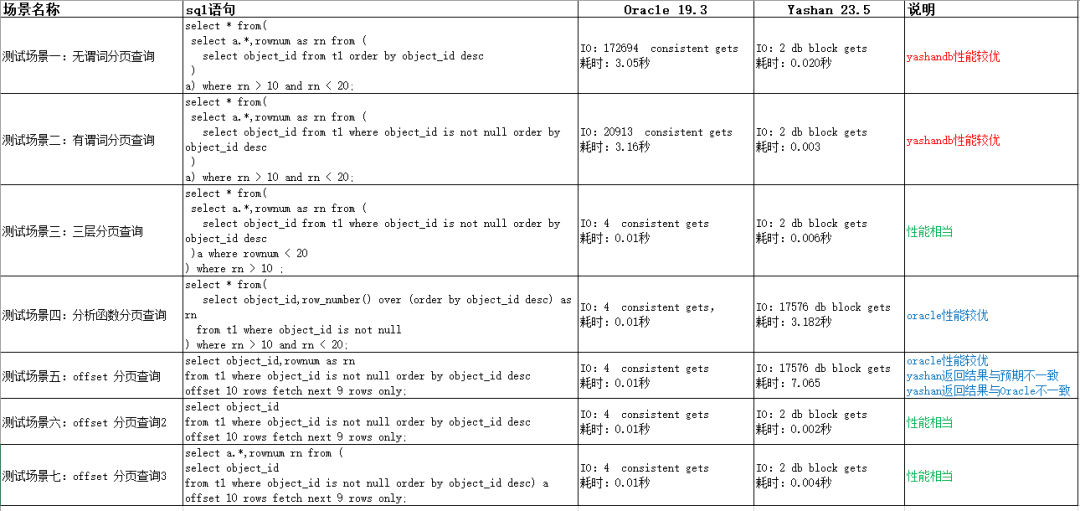
表格说明:横轴为测试场景编号与 SQL 类型,纵轴为 Oracle 19.3 与 YashanDB 23.5 的 IO 指标(consistent gets / db block gets)及耗时;“说明”列标注了性能优劣与异常点。
测试场景一:无谓词分页查询
测试语句
ALTER SESSION SET statistics_level=ALL;
set timing on
SET autotrace ON;
select * from(
select a.*,rownum as rn from (
select object_id from t1 order by object_id desc
)
a) where rn > 10 and rn < 20;
Oracle 测试结果
执行耗时:3.05秒,IO:172694 consistent gets
执行计划关键路径:TABLE ACCESS FULL → SORT ORDER BY
统计信息显示大量物理读(14654 physical reads),说明全表扫描后需排序再截取,效率低下。
YashanDB 测试结果
执行耗时:0.020秒,IO:2 db block gets
执行计划关键路径:INDEX FULL SCAN DESCENDING + COUNT STOPKEY
无任何 consistent gets,且 Predicate Information 明确显示 ROWNUM > 10 和 ROWNUM < 20 被下推至索引扫描层。
小结
- 场景一中 YashanDB 性能显著占优(150 倍提速)
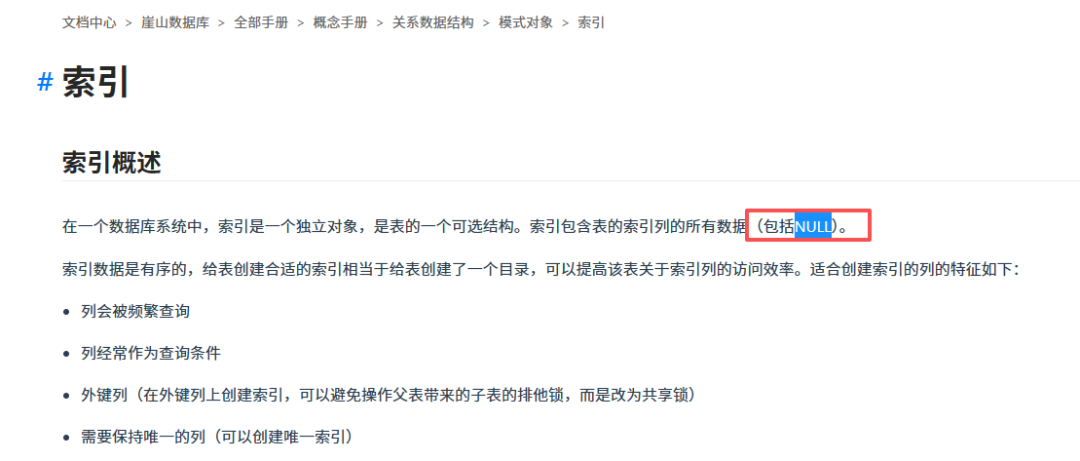
- 根本原因在于:Oracle 索引不存储
NULL 值,而 YashanDB 索引包含所有列值(含 NULL),因此可直接走索引扫描,无需回表或全表扫描
- 该场景对 Oracle 不公平,故后续引入谓词进一步验证
测试场景二:有谓词分页查询
测试语句
ALTER SESSION SET statistics_level=ALL;
set timing on
SET autotrace ON;
select * from(
select a.*,rownum as rn from (
select object_id from t1 where object_id is not null order by object_id desc
)
a) where rn > 10 and rn < 20;
Oracle 测试结果
耗时:3.16秒,IO:20913 consistent gets
执行计划已启用 INDEX FULL SCAN DESCENDING,但因 COUNT STOPKEY 未完全下推(仍需构造完整中间结果集),IO 与耗时仍偏高。
YashanDB 测试结果
耗时:0.003秒,IO:2 db block gets
执行计划中 COUNT STOPKEY 出现在第 2 步,且 INDEX RANGE SCAN DESCENDING 精准命中谓词条件;Predicate Information 显示 access("T1"."OBJECT_ID" IS NOT NULL) 已下推至索引访问层。
小结
- YashanDB 在有谓词场景下仍保持压倒性优势(超 1000 倍提速)
Rownum/StopKey 下推 在 YashanDB 中已深度集成至优化器,配合谓词可实现“边扫描边裁剪”,极大降低资源开销 - 但该 SQL 写法存在潜在风险——嵌套过深易导致优化器误判,建议改用三层结构(见场景三)
测试场景三:三层分页查询
测试语句
select * from(
select a.*,rownum as rn from (
select object_id from t1 where object_id is not null order by object_id desc
)a where rownum < 20
) where rn > 10 ;
Oracle 测试结果
耗时:0.01秒,IO:4 consistent gets
执行计划中 COUNT STOPKEY 出现在第 2 步,INDEX FULL SCAN DESCENDING 直接完成前 20 行扫描,再由外层过滤 rn > 10,逻辑清晰高效。
YashanDB 测试结果
耗时:0.006秒,IO:2 db block gets
执行计划同样使用 COUNT STOPKEY + INDEX RANGE SCAN DESCENDING,且 A-Rows 与 E-Rows 高度吻合,表明估算精准、执行稳定。
小结
- Oracle 与 YashanDB 在此场景下性能基本相当(YashanDB 略快)
- 二者均成功将
STOPKEY 下推至索引扫描阶段,验证了 Rownum/StopKey 优化在主流写法中的普适性
- 场景一、二中 Oracle 表现不佳,本质是 SQL 编写方式未触发其优化路径,而非内核能力缺失
测试场景四:分析函数分页查询
测试语句
select * from(
select object_id,row_number() over (order by object_id desc) as rn
from t1 where object_id is not null
) where rn > 10 and rn < 20;
Oracle 测试结果
耗时:0.01秒,IO:4 consistent gets
执行计划:WINDOW NOSORT STOPKEY + INDEX FULL SCAN DESCENDING,StopKey: 19 明确生效,全程免排序。
YashanDB 测试结果
耗时:3.182秒,IO:17576 db block gets
执行计划中虽有 WINDOW NOSORT,但缺少 * 标记的 STOPKEY 步骤;多出 |* 2 | RESULT 层,且 A-Time 达 3163259(微秒级),表明窗口函数实际执行了全量计算后裁剪。
小结
- Oracle 在分析函数分页上表现更优,YashanDB 当前版本对此类语法的
STOPKEY 下推支持尚不完善
- 关键差异:Oracle 的
WINDOW NOSORT STOPKEY 可提前终止,而 YashanDB 的 WINDOW NOSORT 未做行数限制,导致全量扫描后过滤
- 若业务强依赖
ROW_NUMBER() 分页,建议优先采用三层 rownum 结构替代
测试场景五:OFFSET 分页查询(含 rownum)
测试语句
select object_id,rownum as rn
from t1 where object_id is not null order by object_id desc
offset 10 rows fetch next 9 rows only;
Oracle 测试结果
耗时:0.01秒,IO:4 consistent gets
执行计划:WINDOW NOSORT STOPKEY + INDEX FULL SCAN DESCENDING,StopKey: 19 生效,逻辑与场景四一致。
YashanDB 测试结果
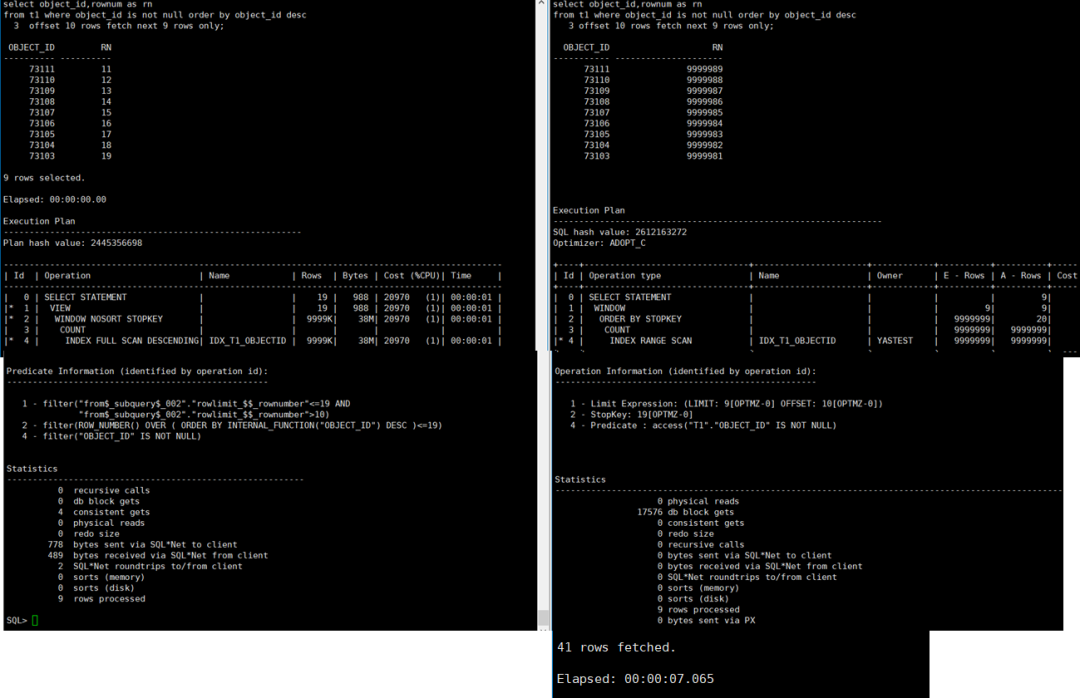
耗时:7.065秒,IO:17576 db block gets
执行计划中 ORDER BY STOPKEY 存在,但 A-Rows 为 20(非预期的 9),且 RN 返回值异常(如 9999989),说明 rownum 生成逻辑与 OFFSET/FETCH 未协同,实际执行了全量排序后截取。
小结
- YashanDB 当前对
OFFSET ... FETCH + rownum 混合写法兼容性不足,结果与 Oracle 不一致
RN 值巨大(接近总行数)暴露其内部先生成全局 rownum 再应用 OFFSET 的缺陷 - 此问题直接影响分页准确性,生产环境应规避该组合写法
测试场景六:纯 OFFSET 分页查询(无 rownum)
测试语句
select object_id
from t1 where object_id is not null order by object_id desc
offset 10 rows fetch next 9 rows only;
Oracle 测试结果
耗时:0.00秒,IO:4 consistent gets
执行计划:WINDOW NOSORT STOPKEY + INDEX FULL SCAN DESCENDING,轻量高效。
YashanDB 测试结果
耗时:0.002秒,IO:2 db block gets
执行计划:INDEX RANGE SCAN DESCENDING + WINDOW,Limit Expression 明确标注 (LIMIT: 9 OFFSET: 10),且 A-Rows = 9,证明 OFFSET/FETCH 本身已支持下推。
小结
- 单独使用
OFFSET/FETCH 时,YashanDB 表现优异,与 Oracle 基本持平
- 场景五的问题根源在于
rownum 的介入破坏了 OFFSET 的优化路径
- 验证结论:YashanDB 的
OFFSET/FETCH 原生支持良好,但与 rownum 混用存在兼容性风险
测试场景七:子查询 + OFFSET 分页
测试语句
select a.*,rownum rn from (
select object_id
from t1 where object_id is not null order by object_id desc
) a offset 10 rows fetch next 9 rows only;
Oracle 测试结果
耗时:0.00秒,IO:4 consistent gets
执行计划:WINDOW NOSORT STOPKEY + INDEX FULL SCAN DESCENDING,rowlimit_$$_rownumber 机制正常工作。
YashanDB 测试结果
耗时:0.004秒,IO:2 db block gets
执行计划:INDEX RANGE SCAN DESCENDING + WINDOW,Limit Expression 正确解析,A-Rows = 9,RN 值为 11~19,符合预期。
小结
- 将
OFFSET/FETCH 置于子查询外部,YashanDB 可正确处理 rownum 并保证结果一致性
- 此写法是场景五问题的推荐替代方案:既保留
OFFSET 语义,又规避 rownum 冲突
- 实践建议:分页逻辑尽量解耦,避免在
OFFSET/FETCH 同一层混用 rownum
综合结论与选型建议
- YashanDB 23.5 的 Rownum/StopKey 下推能力成熟可靠,尤其在传统
rownum 嵌套分页(场景一至三)中优势明显,IO 与耗时全面优于 Oracle
- 对标准 SQL:2008
OFFSET/FETCH 语法原生支持良好(场景六、七),但需注意避免与 rownum 同层混用(场景五)
- 分析函数分页(
ROW_NUMBER())仍是 Oracle 更优选择(场景四),YashanDB 当前版本尚未实现窗口函数的 STOPKEY 下推
- 索引设计是分页性能的底层基石:YashanDB 索引包含
NULL 值的特性,在无谓词场景下天然适配,而 Oracle 需显式添加 IS NOT NULL 谓词才能启用索引
如需深入探讨 数据库/中间件/技术栈 的性能调优实践,或了解 软件测试 中的 SQL 压测方法论,欢迎持续关注云栈社区的技术沉淀。
 发表于 2026-3-21 05:03:00
|
查看: 125|
回复: 0
发表于 2026-3-21 05:03:00
|
查看: 125|
回复: 0
