
近日,一款代号“Hunter Alpha”的神秘AI模型在开发者平台OpenRouter上匿名亮相,迅速吸引了全球开发者的目光。测试数据显示,这款模型具备万亿级参数规模和高达百万token的上下文窗口,仅一周内累计调用量就突破了1.5万亿Token,并多次登顶平台日榜榜首。其出色的表现甚至让“龙虾之父”Peter Steinberger在社交平台X上公开询问:这究竟是哪家厂商的作品?
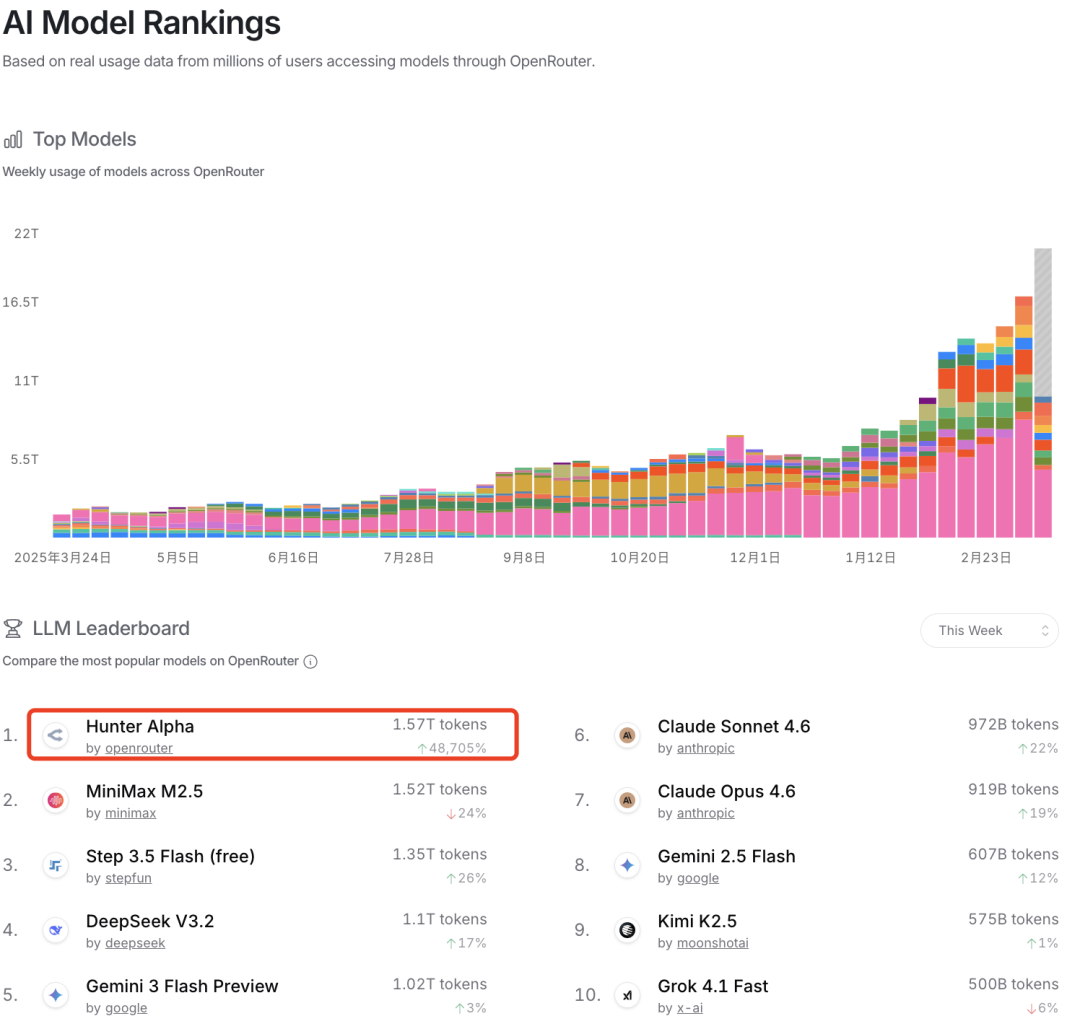
由于性能过于惊艳,起初不少网友猜测这可能是DeepSeek正在秘密测试的新一代模型。然而,剧情很快迎来反转。小米官方随后正式揭晓,这款神秘的Hunter Alpha模型,正是其最新发布的旗舰大模型——MiMo-V2-Pro。

近段时间,随着OpenClaw等框架推动的智能体应用热潮,国内大模型厂商纷纷加速推出适配智能体场景的基座模型。智谱的GLM-5-Turbo、MiniMax的M2.7、阶跃星辰的Step 3.5以及月之暗面的Kimi K2.5等模型都获得了开发者的青睐,市场竞争日趋白热化。在此背景下,入局相对较晚的小米,其模型表现出的性能水准让许多人感到意外。
模型正式发布后,小米创始人雷军在微博上表示:“我们在AI领域相对比较低调,实际进展可能比大家看到的要快很多。在AI领域,我们今年的研发和资本投入就将超过160亿元。” 这番表态也让人联想到,在当前激烈竞争下,迟迟未推出新模型的DeepSeek所面临的压力无疑更大了。

跻身国产模型前三
根据小米官方介绍,MiMo-V2-Pro专为现实世界中高强度的智能体工作场景打造。它拥有超过1万亿的总参数量(其中激活参数为420亿),采用了创新的混合注意力架构,并支持高达100万token的超长上下文长度,实现了从传统代码生成到复杂智能体任务的重要能力泛化。
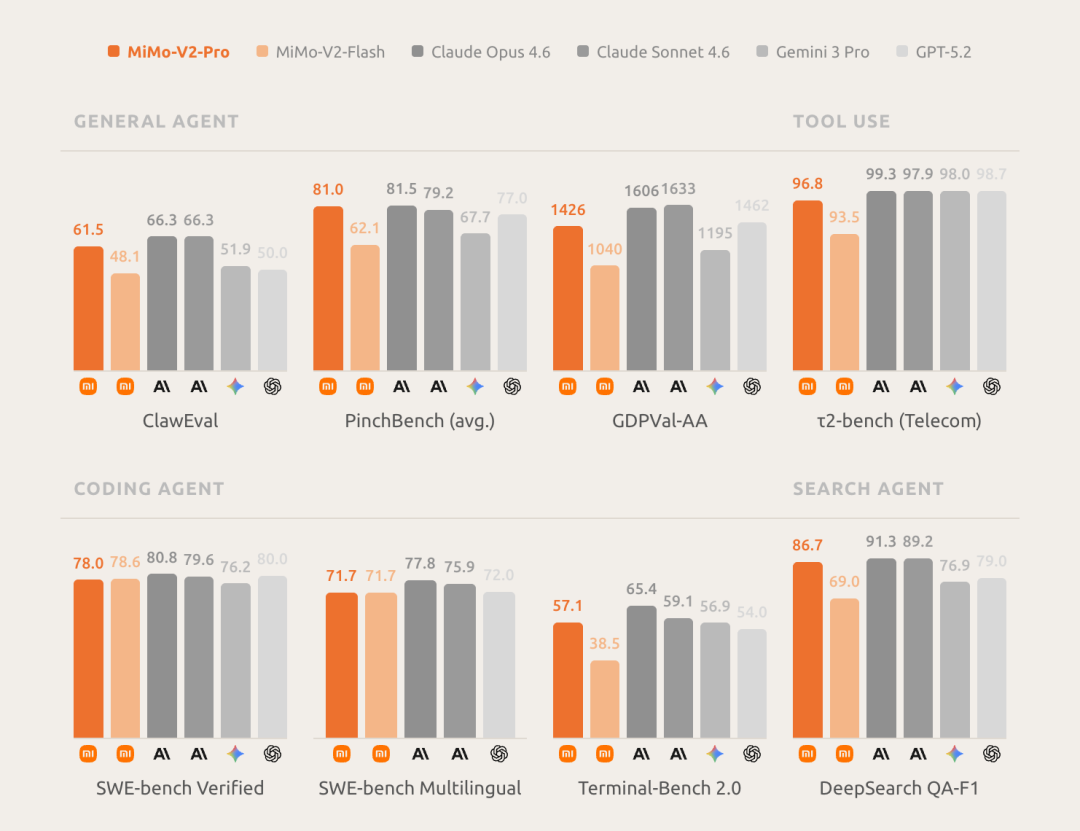
在全球大模型综合智能排行榜Artificial Analysis上,MiMo-V2-Pro位列全球第八、国内第二。官方称,其整体使用体验已超越Claude Sonnet 4.6,逼近Opus 4.6,而API定价仅为后者的五分之一。在各个核心能力基准测评中,MiMo-V2-Pro在代码智能、通用智能体能力和工具使用方面,已与Claude Sonnet 4.6、GPT-5.2、Gemini 3.0 Pro等顶尖模型处于同一梯队。
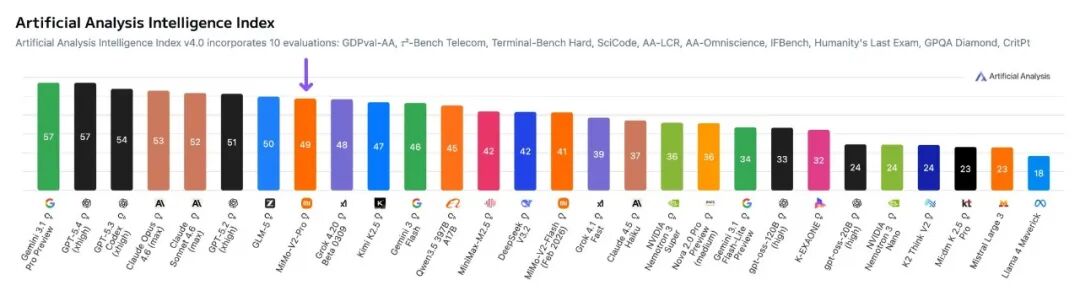
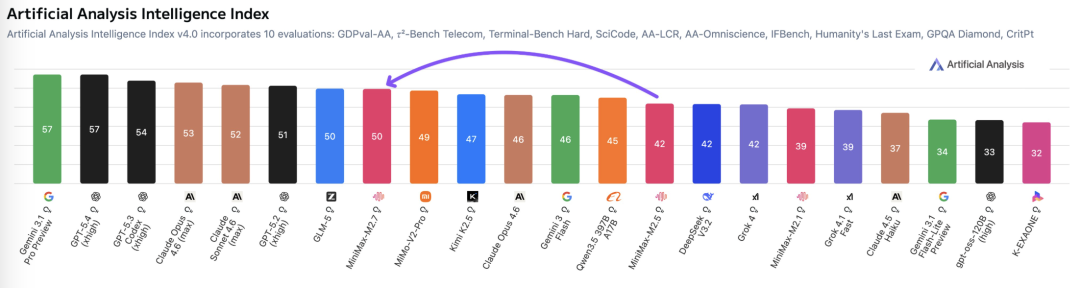
当然,大模型的排行榜位次总是动态变化的。根据最新排名,MiniMax新发布的M2.7模型又反超了小米。小米同样抓住了OpenClaw带来的市场机遇,对MiMo-V2-Pro进行了针对性的深度优化。该模型通过SFT(监督微调)和RL(强化学习)在多样化的代理框架上进行了精细调优,从而具备了更强大的工具调用和多步骤推理能力。

在OpenClaw的标准评估基准测试PinchBench和ClawEval中,MiMo-V2-Pro取得了全球领先的成绩。凭借100万token的上下文窗口,它可以轻松支持高强度、真实世界的智能体工作流。
此外,MiMo-V2-Pro在严肃的代码工程任务中也表现出色。在内部工程师的深度评测中,其体验已接近Claude Opus 4.6,并展现出高阶的代码智能:包括更出色的系统设计与任务规划能力、更优雅的代码风格,以及更高效直接的问题解决路径。

在前端应用场景中,MiMo-V2-Pro展现了不错的端到端完成能力。在OpenClaw框架下,它只需一次查询即可生成既美观又功能完备的网页,兼顾了视觉效果与实用性。
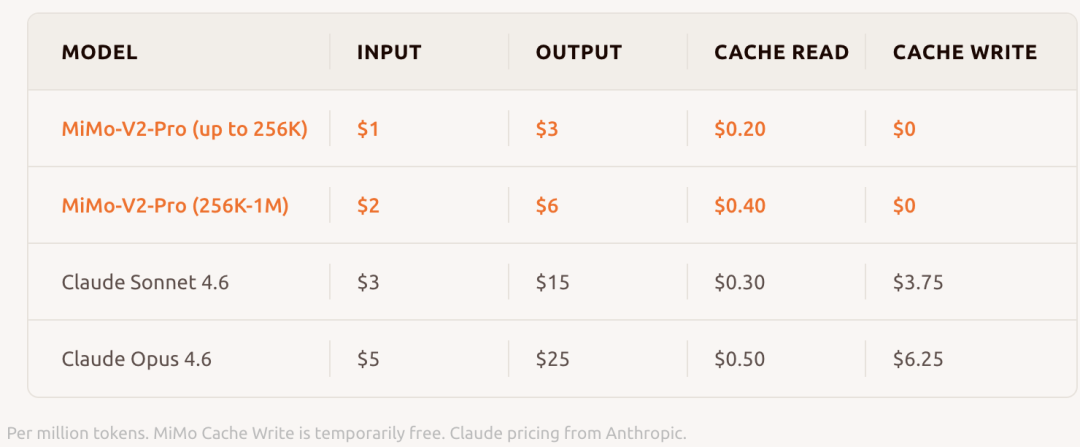
目前,该模型已在多平台同步上线,定价颇具竞争力。在官方体验页面,同步推出了MiMo Claw应用。此外,小米的底层推理引擎还与金山办公WPS生态、小米手机内置的智能助理以及小米浏览器等实现打通,进一步扩展了模型的能力边界。
罗福莉回应“为什么进展这么快”
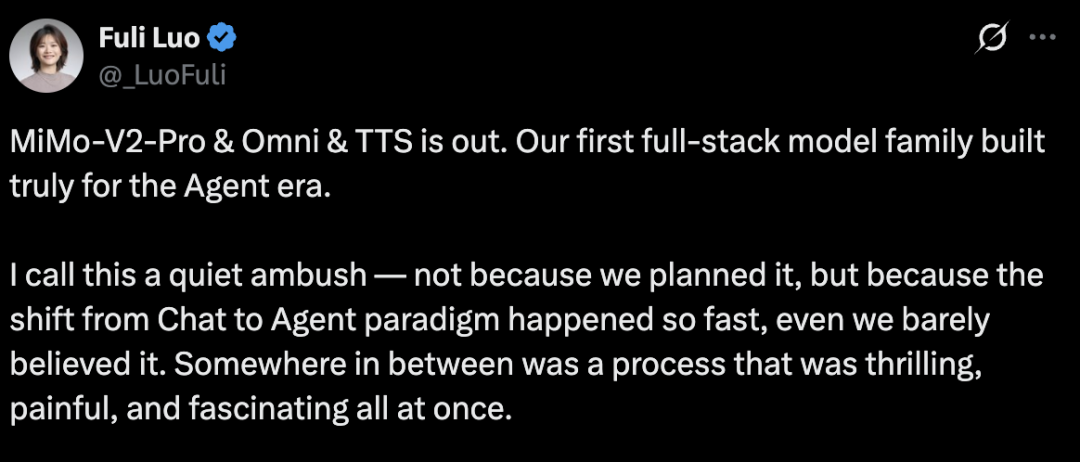
此次与MiMo-V2-Pro一同发布的,还有MiMo-V2-Omni(多模态模型)与MiMo-V2-TTS(文本转语音模型)。小米MiMo大模型负责人罗福莉在社交媒体上发文,称这是“首个真正为智能体时代打造的全栈模型家族”。

她将这次发布形容为“一次悄无声息的突袭”——并非因为团队事先精心策划,而是因为从聊天模式到智能代理模式的范式转变发生得太快,以至于团队自身都感到有些难以置信。在这个过程中,团队经历了一段既激动人心、又充满挑战的探索之旅。
罗福莉透露,参数量达万亿级的基座模型在数月前就已启动训练,最初的目标是提升长上下文推理的效率。小米内部团队在混合注意力机制方面做出了实质性创新,没有过度激进,而事实证明,这一架构恰好契合了智能体时代的需求。百万级上下文窗口与MTP推理所实现的超低延迟与低成本,这些都是在市场明确需求之前就已构建的结构性优势。
“真正改变一切的,是我第一次体验到一套复杂的智能体架构——我称之为‘编排式上下文’,第一天我就被震撼了,”罗福莉回顾道,“我试图说服团队去用它,但没成功。于是我下了一道强硬指令:明天之前,MiMo团队里对话次数不满100轮的人,可以直接离职。”
这招奏效了。一旦团队的想象力被智能体系统的强大功能所激发,这种热情便直接转化为了惊人的研发速度。

罗福莉在帖子中写道:“总有人问我们为什么进展这么快?在打造DeepSeek R1的过程中,我亲眼见证了答案。我的真实总结是:
- 基座与基础设施研发周期很长,你需要在成果兑现前一年就拥有战略定力。
- 后训练阶段的敏捷性是另一项核心能力:靠产品直觉驱动评估,压缩迭代周期,及早捕捉范式转变。
- 不变的是:好奇心、敏锐的技术直觉、果断的执行力、全身心的投入——还有一件很容易被低估的事:对自己正在构建的世界,发自内心的热爱。”
最后,她还表示,当模型足够稳定、值得开源的时候,会把模型向社区开放。这或许意味着未来我们有机会在开源实战中看到它的身影。
历时3个月的逆袭
大模型行业已经走过了前期试水与洗牌阶段,开源AI技术创新力量正处于上升期,推理时代的AI Agent应用也处于爆发前夜,商业应用日趋成熟。有分析指出(此前曾分析),就资本实力而言,小米比一些纯粹的AI初创公司更具优势。其AI业务有着手机、智能汽车、IoT与生活消费产品、互联网服务等主干业务作为持续的营收支撑,数据和落地场景十分丰富,集团用于AI研发的投入也相当充沛。只要人才和目标明确,快速向第一梯队看齐是大概率事件。

作为AI大模型赛道的“逆袭者”,小米正在展现出后发竞争优势。去年12月,罗福莉入职小米后首次公开演讲,带队推出了开源模型MiMo-V2-Flash,其性能当时已可媲美DeepSeek-V3.2。当时的技术报告提到,相较于顶尖闭源模型,MiMo-V2-Flash仍有明显差距,后续计划通过扩大参数量和训练计算量来逐步缩小差距,未来工作将聚焦于构建更稳健、高效的智能体导向型模型架构。
时隔仅3个月,这个目标便已实现,研发团队的“爬坡速度”令人印象深刻。对于大模型和智能体这场战役而言,真正的游戏或许才刚刚开始,最终的领跑者依然充满悬念。想要了解更多前沿技术动态和深度讨论,欢迎来云栈社区与广大开发者一起交流探索。
 发表于 2026-3-21 06:52:47
|
查看: 139|
回复: 0
发表于 2026-3-21 06:52:47
|
查看: 139|
回复: 0
