你是否遇到过一台物理机上运行着多个相同操作系统的虚拟机,发现它们使用了大量重复的内存页,却无法回收利用?Linux 内核中的 KSM(Kernel Samepage Merging)机制,正是为了解决这类问题而生的内存“瘦身”利器。
简单来说,KSM 的核心思想是合并内容相同的页面。在虚拟化或容器化环境中,大量运行着相同操作系统和应用程序的实例,其内存中充斥着大量内容完全一样的匿名页面。KSM 允许内核扫描这些页面,将内容相同的合并成一个只读的物理页面,从而释放出多余的物理内存供其他应用使用。这个过程对上层应用程序是完全透明的,当某个进程需要修改被合并的页面内容时,会触发写时复制(Copy-On-Write),确保数据安全。
一、KSM的实现机制
KSM 的设计核心是基于写时复制(COW)机制,其实现可以分为两个主要部分:
- 内核启动一个名为
ksmd 的守护线程,它周期性地被唤醒以执行页面扫描和合并工作。
- 用户进程通过
madvise 系统调用显式地将自己的地址空间标记为可合并,以此唤醒 ksmd 线程。
用户若想启用某个内存区域的 KSM 功能,需调用 madvise(addr, length, MADV_MERGEABLE);若要取消,则调用 madvise(addr, length, MADV_UNMERGEABLE)。
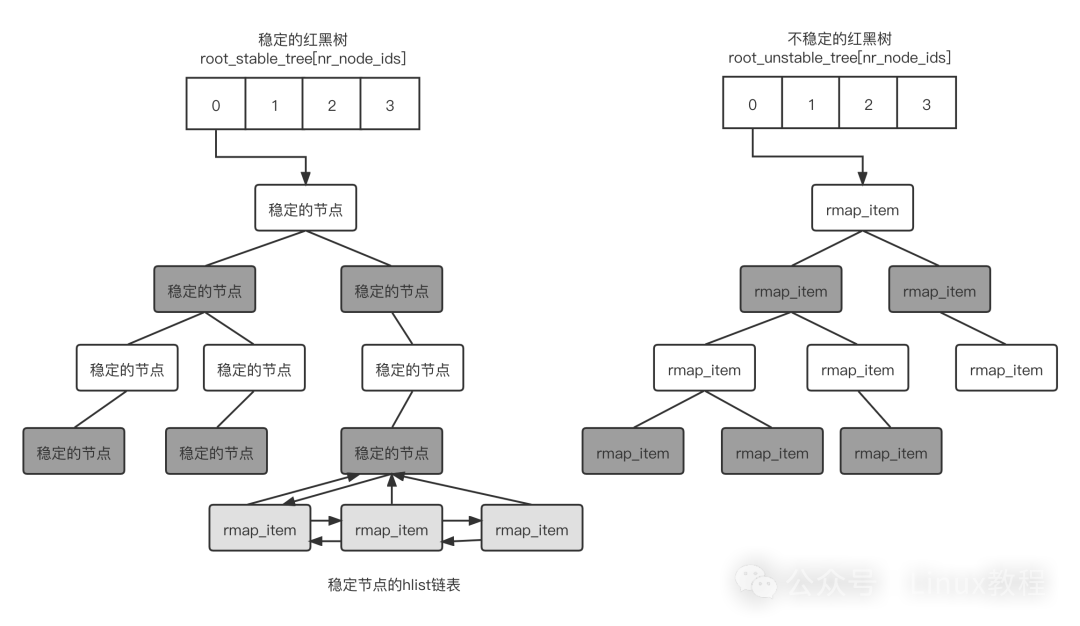
KSM 的工作流程可以概括为:扫描发现两个内容完全相同的页面,将它们合并。合并后,该页面被设置为只读属性。其中一个页面会作为“稳定的节点”加入稳定的红黑树,而另一个页面则被释放。同时,描述这两个页面的反向映射结构 rmap_item 会被链接到稳定节点的哈希链表中。
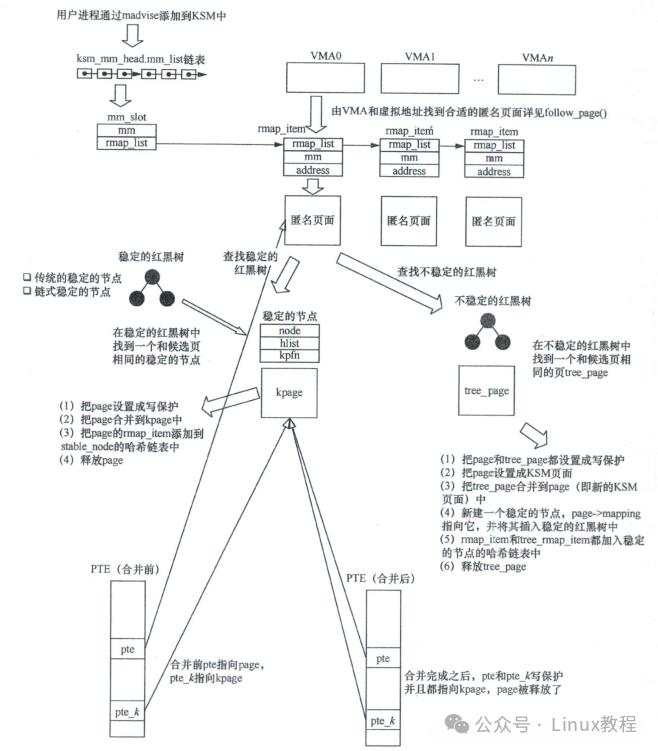
一个简化的合并示例
假设有 3 个 VMA(虚拟内存区域),每个大小恰好为一个页面,分别映射到 3 个内容相同的匿名页。以下是 KSM 扫描合并它们的步骤:
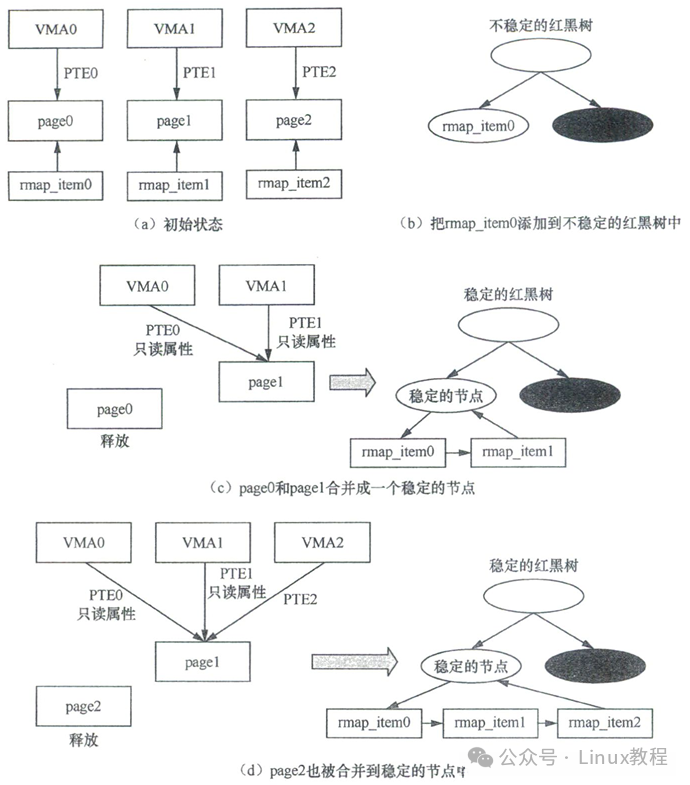
- 初始状态:三个页面
page0, page1, page2 被添加到 KSM 扫描队列。第一轮扫描中,为每个页面分配一个 rmap_item 结构来描述它们,并计算初始的校验和。
- 加入不稳定树:第二轮扫描
page0。此时稳定树为空,无法匹配。如果 page0 的校验和与第一轮相比未发生变化,则将其 rmap_item 插入不稳定的红黑树中。
- 首次合并:扫描
page1。在不稳定树中搜索,发现其内容与 page0 一致。于是尝试将 page0 和 page1 合并。
- 让
VMA0 映射到 page1。
- 将
VMA0 和 VMA1 对应的页表项(PTE)属性都修改为只读。
- 创建一个新的稳定节点(包含
page1 信息),将其插入稳定红黑树。
- 将
page0 和 page1 对应的 rmap_item 链接到该稳定节点的哈希链表。
- 释放
page0 页面。
- 二次合并:扫描
page2。先在稳定树中搜索,发现其内容与稳定节点(page1)一致。
- 让
VMA2 映射到 page1。
- 将
VMA2 的 PTE 属性设为只读。
- 将
page2 的 rmap_item 链接到同一稳定节点的哈希链表。
- 释放
page2 页面。
KSM 关键问题解答
KSM 合并什么类型的页面?
一个典型的应用程序内存由以下几部分组成:
- 可执行文件的内存映射(page cache)
- 程序分配的匿名页面
- 进程打开的文件映射
- 文件系统产生的 cache
- 内核 buffer(如 slab)等
KSM 只处理进程分配的匿名页面。
如何查找和比较相同页面?
KSM 巧妙地设计了两棵红黑树:stable tree(稳定树)和 unstable tree(不稳定树),并通过校验和来判断 unstable tree 中的页面是否近期被修改过。
如何真正节省内存?
页面合并的核心是将多个虚拟地址映射到同一个物理页面。要真正释放物理页面,需要解除所有指向它的映射。KSM 通过扫描进程的 VMA,找到内容相同的页面后,修改其 PTE 指向合并后的 KSM 页面,并设为写时复制(COW)。如果原物理页面只剩下一个映射,那么在该映射解除后,页面即被释放。
1.1 启用 KSM 功能
许多内核默认未开启 KSM,需要通过内核配置 CONFIG_KSM=y 来启用。在 make menuconfig 中的路径通常是:
Processor type and features
Enable KSM for page merging
1.2 KSM 核心数据结构
KSM 的实现依赖于三个核心数据结构,它们是理解其 内存管理 机制的关键:
struct rmap_item: 描述一个虚拟地址的反向映射条目。struct mm_slot: 描述已添加到 KSM 系统中、等待扫描的进程内存描述符 (mm_struct)。struct ksm_scan: 表示当前的扫描状态。
以下是 rmap_item 的定义节选:
/**
* struct rmap_item - reverse mapping item for virtual addresses
* @rmap_list: next rmap_item in mm_slot's singly-linked rmap_list
* @anon_vma: pointer to anon_vma for this mm,address, when in stable tree
* @nid: NUMA node id of unstable tree in which linked (may not match page)
* @mm: the memory structure this rmap_item is pointing into
* @address: the virtual address this rmap_item tracks (+ flags in low bits)
* @oldchecksum: previous checksum of the page at that virtual address
* @node: rb node of this rmap_item in the unstable tree
* @head: pointer to stable_node heading this list in the stable tree
* @hlist: link into hlist of rmap_items hanging off that stable_node
*/
struct rmap_item {
struct rmap_item *rmap_list;
union {
struct anon_vma *anon_vma; /* when stable */
#ifdef CONFIG_NUMA
int nid; /* when node of unstable tree */
#endif
};
struct mm_struct *mm;
unsigned long address; /* + low bits used for flags below */
unsigned int oldchecksum; /* when unstable */
union {
struct rb_node node; /* when node of unstable tree */
struct { /* when listed from stable tree */
struct stable_node *head;
struct hlist_node hlist;
};
};
};
1.3 madvise 唤醒 KSM 内核线程
madvise 系统调用用于给内核提供内存分页 I/O 的建议。与 KSM 相关的是 MADV_MERGEABLE 和 MADV_UNMERGEABLE 参数。当用户调用 madvise 并指定 MADV_MERGEABLE 时,会触发 __ksm_enter 函数。该函数为当前进程创建 mm_slot 结构,并将其加入到待扫描队列,随后唤醒阻塞在等待队列上的 ksmd 内核线程。
1.4 内核线程 ksmd
ksmd 是 KSM 机制的工作引擎。它通过 ksm_init 函数在内核启动时被创建,执行入口函数为 ksm_scan_thread。该线程的主体逻辑是一个循环:
- 在满足运行条件时,调用
ksm_do_scan(ksm_thread_pages_to_scan) 扫描指定数量的页面。
- 扫描完成后,睡眠
ksm_thread_sleep_millisecs 毫秒。
- 如果无事可做(没有可合并的内存区域),则在一个等待队列上休眠,直到被
madvise 调用唤醒。
用户可以通过 /sys/kernel/mm/ksm/ 下的文件节点对 KSM 进行监控和调优,例如:
run: 控制 KSM 的运行(0停止,1运行,2停止并拆分已合并页)。pages_to_scan: 单次扫描的页面数。sleep_millisecs: 扫描间隔时间。pages_shared / pages_sharing: 分别表示稳定树中的节点数和被共享的页面总数。pages_sharing / pages_shared 比值越高,说明共享效果越好。
ksm_do_scan 是执行实际扫描合并工作的函数,其核心流程如下:
ksm_do_scan
scan_get_next_rmap_item // 获取一个待扫描的匿名页面及其 rmap_item
cmp_and_merge_page // 尝试将该页面与稳定树/不稳定树中的页面合并
stable_tree_search // 在稳定树中搜索内容相同的页面
try_to_merge_with_ksm_page // 尝试合并到已有的 KSM 页面
unstable_tree_search_insert // 在不稳定树中搜索/插入
try_to_merge_two_pages // 合并不稳定树中找到的两个页面
cmp_and_merge_page 函数是合并逻辑的核心。它首先尝试在稳定树中查找内容相同的页面(stable_tree_search)并合并。如果失败,则计算页面校验和,若校验和未变,再尝试在不稳定树中查找(unstable_tree_search_insert)。如果找到,则合并这两个页面成为一个新的 KSM 页面,并创建一个稳定节点加入稳定树。
二、匿名页面与 KSM 页面的区别
2.1 如何区分?
在 Linux 内核中,一个 struct page 的 mapping 成员指向其所属的地址空间。通过检查 mapping 的低位标志,可以区分页面类型:
#define PAGE_MAPPING_ANON 1
#define PAGE_MAPPING_KSM 2
#define PAGE_MAPPING_FLAGS (PAGE_MAPPING_ANON | PAGE_MAPPING_KSM)
内核提供了对应的判断函数:
static inline int PageAnon(struct page *page)
{
return ((unsigned long)page->mapping & PAGE_MAPPING_ANON) != 0;
}
static inline int PageKsm(struct page *page)
{
return ((unsigned long)page->mapping & PAGE_MAPPING_FLAGS) ==
(PAGE_MAPPING_ANON | PAGE_MAPPING_KSM);
}
由此可见,KSM 页面一定是匿名页面,是匿名页面的一个子集。
2.2 反向映射的差异
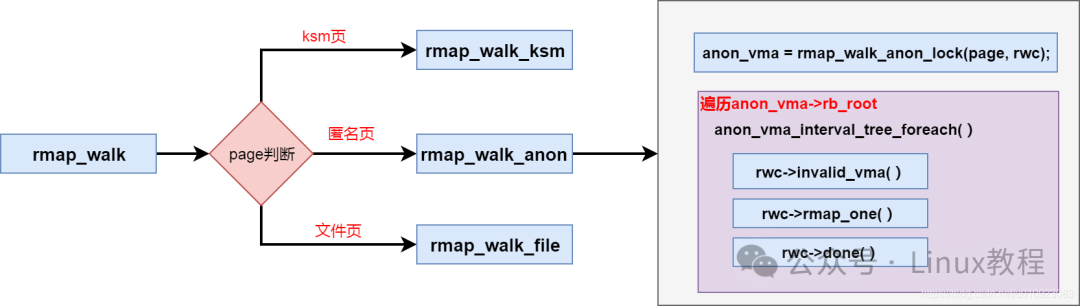
这是匿名页面和 KSM 页面在实现上的一个关键区别,主要体现在如何通过物理页面找到所有映射它的虚拟地址(反向映射)。
- 普通匿名页面:通常由父子进程通过
fork 共享。父进程在映射匿名页时,会在 page->index 中记录该页面在 VMA 中的偏移。子进程复制了页表,因此共享相同的 page->index。在进行反向映射查找时(rmap_walk_anon),通过 page->index 计算出在每个 VMA 中的虚拟地址。
- KSM 页面:可能被任意两个进程(无论是否相关)共享。由于合并的页面可能来自不同 VMA 的不同偏移,
page->index 只保存了第一次映射该页的 VMA 中的偏移,这对其他进程没有意义。因此,KSM 页面使用 rmap_item->address 来精确记录每个映射对应的原始虚拟地址。在进行反向映射查找时(rmap_walk_ksm),直接遍历稳定节点的哈希链表,使用每个 rmap_item 中存储的 address 字段。
小结
KSM 是一种通过合并相同内存页来提升内存利用率的有效机制,尤其在虚拟化、容器化等存在大量重复内存场景下效益显著。其实现基于红黑树进行高效查找,并依赖于写时复制来保证数据一致性。然而,它并非没有代价,持续的页面扫描和比较会带来额外的 CPU 开销。在实际的 虚拟化环境 中,需要根据具体的工作负载权衡内存节省与性能消耗,通过调整 /sys/kernel/mm/ksm/ 下的参数来取得最佳平衡。
对于希望深入了解 Linux 内核 内存管理 机制的同学来说,剖析 KSM 的实现是一个很好的切入点,它涉及了匿名页面管理、红黑树、反向映射等多个核心子系统。
 发表于 2026-3-22 04:04:50
|
查看: 129|
回复: 0
发表于 2026-3-22 04:04:50
|
查看: 129|
回复: 0
