传统 Python PDF 库的表格提取准确率常常令人头疼,复杂报表最终可能还是得靠手动复制。今天分享一个我近期测试过的工具: LlamaParse。它并非普通的 Python 库,而是 LlamaIndex 官方推出的、专为大型语言模型(LLM)用例设计的文档解析服务。
提前说明:它是一项基于 API 的付费服务,但提供了每天 1000 页的免费额度。对于个人开发者和小型项目进行技术验证和测试来说,这个额度已经非常充裕。
一、LlamaParse 是什么?
LlamaParse 是由 LlamaIndex 开发的 AI 原生文档解析器,它专门针对 PDF、PPTX、DOCX 等复杂格式文件,旨在为 RAG(检索增强生成)、智能代理(Agent)以及数据预处理等 LLM 应用场景提供高质量的结构化数据。
截至最新版本(v0.6.90),它支持超过 90 种文档格式,核心能力并非简单的 OCR 识别,而是针对 LLM 消费进行了深度优化。它与 LlamaIndex 框架紧密集成,方便用户构建端到端的数据处理管道。
二、核心功能与特点
- 布局与文本感知解析:能够理解多栏排版、嵌套结构、页眉页脚等复杂文档布局,准确还原内容逻辑。
- 智能表格与图像处理:这是它的强项。可以高精度地提取表格,保留合并单元格、跨页表格等复杂关系。同时支持多模态解析,处理图表、手写文字和嵌入图片。
- 灵活的出力格式:默认输出 Markdown 格式,这种格式对 LLM 非常友好。同时也支持 JSON、纯文本或根据自定义 Schema 进行结构化输出。
- 易于集成:提供 Python SDK,通过
pip install llama-parse 即可安装,使用前需要申请 API 密钥。
三、动手实践:两种使用方式
方式一:通过 Python SDK 调用
首先,你需要在 LlamaCloud 官网 注册并获取 API 密钥。
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# 设置API密钥
parser = LlamaParse(
api_key="YOUR_API_KEY",
parse_mode="agent_plus", # v2代理+模式,适合复杂文档
result_type="markdown" # 输出Markdown
)
# 加载和解析文件
documents = SimpleDirectoryReader(
input_files=["example_report.pdf"],
file_extractor={".pdf": parser}
).load_data()
# 输出第一页内容
print(documents[0].text)
这段代码演示了基本的集成流程。使用 agent_plus 模式可以更好地处理结构复杂的文档,如包含大量表格的报告。
方式二:通过官方 Web 平台直接上传
如果你不想写代码,也可以直接访问 LlamaCloud 平台,在“Parse”功能模块中上传文件。平台会直接提供解析后的结果预览和下载,对于快速测试和查看效果非常方便。
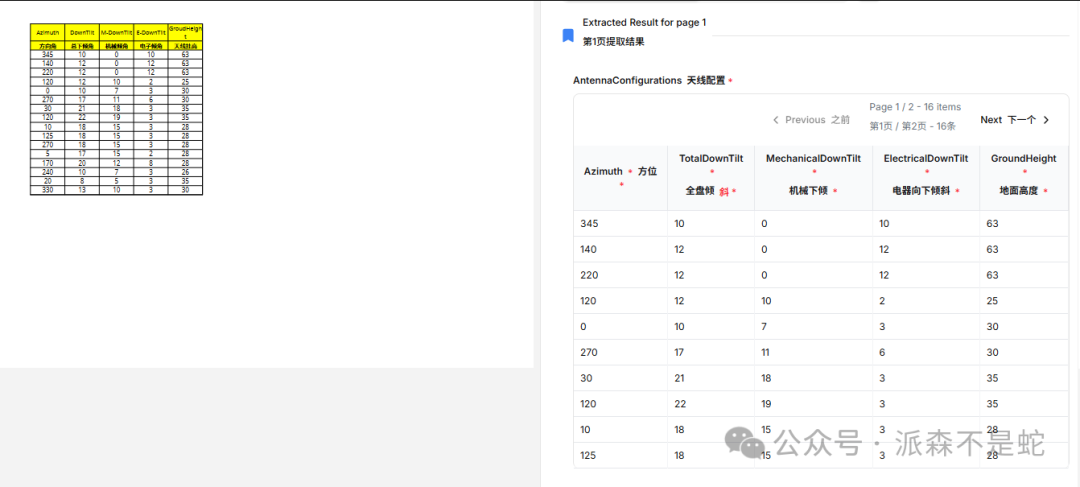
下图展示了将一个包含天线配置参数的中文PDF表格上传后,LlamaParse 准确提取并结构化输出的结果对比。可以看到,它成功识别了表头和多行数据,并将中文表头转换为了对应的英文字段。
总结与思考
经过实际测试,LlamaParse 在表格提取的准确率和结构化程度上,确实比许多传统开源 Python 库表现更优,尤其适合作为 RAG 管道的前置数据处理工具。其免费额度降低了体验门槛,开发者可以轻松评估它是否适合自己的项目需求。
当然,作为一项云服务,它对网络有一定依赖,且复杂文档的解析可能需要一些等待时间。但对于追求数据提取质量、特别是需要处理大量非结构化报表的 AI 应用开发者 来说,它无疑是一个值得放入工具箱的选项。如果你想了解更多类似的工具评测和 技术文档,可以持续关注云栈社区的技术分享。 |  发表于 2026-3-25 14:44:01
|
查看: 216|
回复: 0
发表于 2026-3-25 14:44:01
|
查看: 216|
回复: 0
