还在为C++程序运行时的性能瓶颈发愁吗?明明代码经过精心设计,但上线后却像在开盲盒,CPU使用率异常飙升、内存泄漏难以捉摸、请求延迟卡顿等问题接踵而至。告别仅凭经验和运气的故障排查方式吧。工欲善其事,必先利其器,一套好的监控工具能让你清晰地洞察程序的每一次心跳。
本文将为你梳理5款能够实时掌控C++程序运行状态的性能监控工具,涵盖从指标采集到可视化分析,从系统级监控到容器化追踪的各个层面,助你找到最适合当前场景的解决方案。
Prometheus C++ Client:监控指标暴露的基石
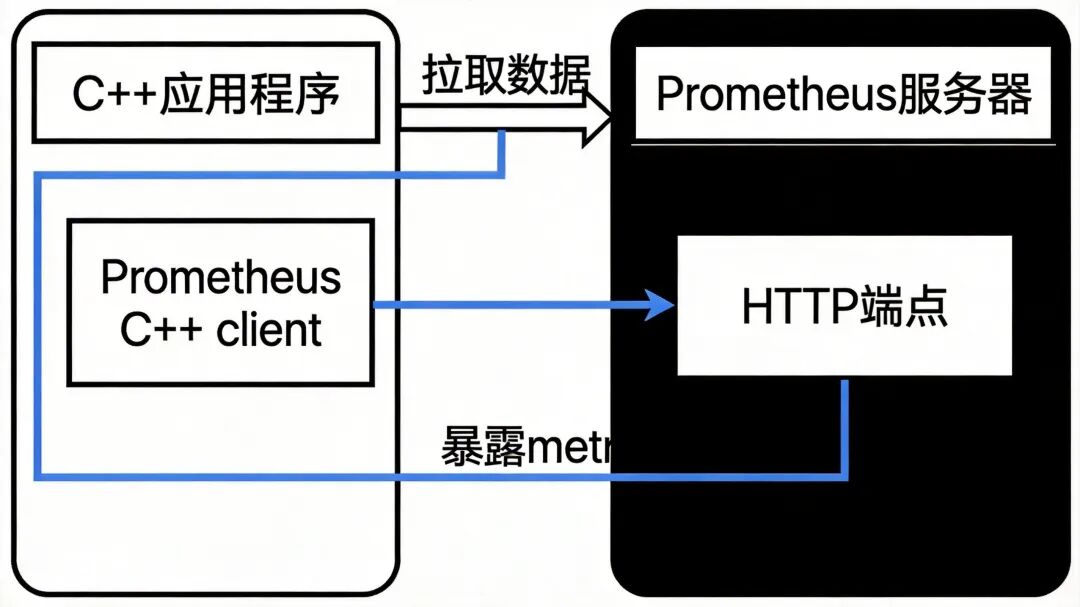
作为云原生监控领域的事实标准,Prometheus的C++客户端库是实现Metrics-Driven Development (MDD) 的利器。它远不止是一个简单的计数器,而是完整实现了Prometheus数据模型,原生支持Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)等多种度量类型。
它的核心特性包括:
- 轻量化设计:添加和更新度量值的开销极低,非常适合高性能环境。
- 维度标签:通过标签为度量信息添加上下文,极大方便了后期的聚合与数据分析。
- 内置HTTP服务器:库内集成了Exposer,可在指定端口轻松启动服务,接收Prometheus服务器的定期抓取请求。
- 高度可定制:支持插件机制,便于对接各种自定义的数据收集策略。
在实际应用中,你只需通过简单的代码启动Exposer来暴露metrics端点,Prometheus服务器便会周期性地拉取这些数据。整个过程对应用核心逻辑的侵入性极小,却能为你提供持续、丰富的性能指标支持。
项目地址:https://github.com/jupp0r/prometheus-cpp
Grafana:数据可视化的强力搭档
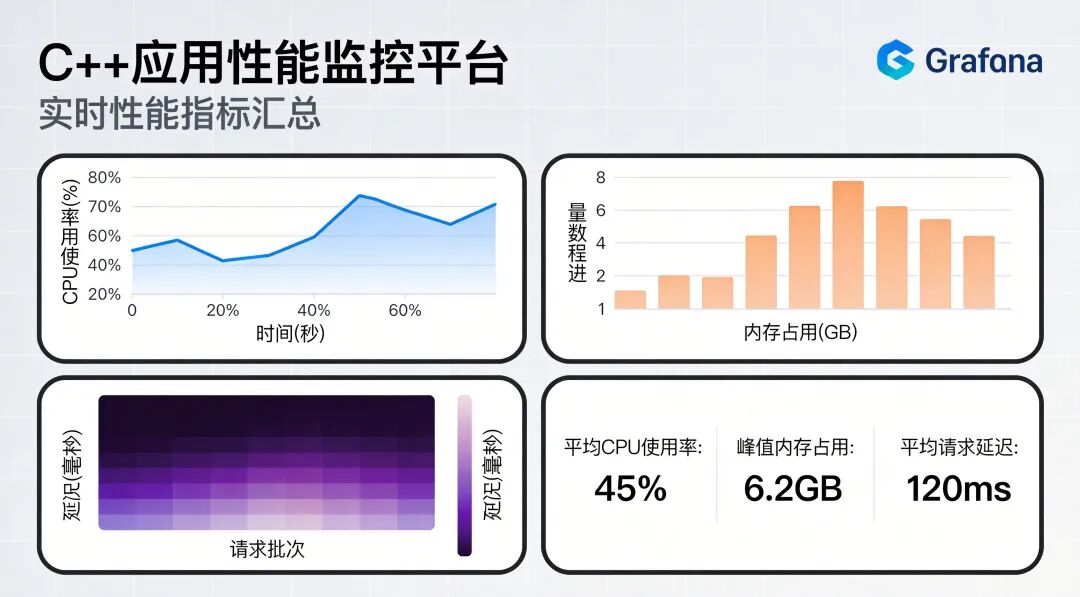
仅有数据是不够的,我们需要让数据“说话”,变得直观易懂。Grafana便是让Prometheus采集的数据“活”起来的最佳搭档,它不只是一个图表工具,更是一个功能完整的监控可视化平台。
其强大之处在于:
- 丰富的图表类型:支持实时曲线图、直方图、热力图、仪表盘等多种可视化方式。
- 灵活的数据源:除了Prometheus,还无缝支持InfluxDB、Elasticsearch等多种数据源。
- 强大的告警引擎:支持基于指标阈值设置复杂的告警规则,并可通过邮件、钉钉、Webhook等多种方式通知。
- 模板化变量:允许创建动态仪表盘,轻松适配不同环境、不同应用实例的监控需求。
你可以为你的C++应用创建专属的性能仪表盘,实时监控关键指标如请求延迟(P50、P99)、错误率、吞吐量(QPS)等。内存使用率是否在持续攀升?P99延迟是否突然飙升?这些问题在Grafana的图表界面中都将一目了然。
官方地址:https://grafana.com
Netdata:开箱即用的全栈实时监控
如果你希望快速搭建监控系统,不愿在初始配置上花费过多时间,那么Netdata将是你的理想选择。它主打“开箱即用”,号称能在60秒内完成部署,并自动发现系统中的各类指标。
它的亮点包括:
- 真正的实时性:默认每秒采集一次数据,并以亚秒级延迟进行可视化,让你感知系统的每一次细微波动。
- 内置异常检测:集成了机器学习模型,能自动检测指标中的异常模式并发出预警。
- 全面的指标覆盖:拥有800多个自动发现集成,覆盖CPU、内存、磁盘、网络、进程等几乎所有系统层面。
- 统一观测平台:在一个界面中整合了指标、日志、进程树和网络连接信息,提供关联分析的能力。
对于C++开发者而言,Netdata的eBPF插件尤为有用,它能深入到系统性能分析和内核调用层面,帮你监控系统调用异常、文件描述符泄漏等深层次问题。是否存在因高频sync调用导致的I/O瓶颈?文件描述符数量是否在持续增长而未被释放?Netdata可以帮你快速定位这些“隐形”问题。
官方地址:https://www.netdata.cloud
当性能问题需要从应用层深入到操作系统和硬件层面进行剖析时,就需要像PCP这样的专业工具包。它是一个为复杂系统环境和长期性能分析而设计的框架。
PCP的核心优势体现在:
- 分布式架构:采用轻量级的代理进行数据采集,天然支持跨多台主机、多种操作系统的统一监控。
- 丰富的命令行工具集:提供
pmstat、pminfo、pmval、pmlogger等工具,满足从实时查看到数据记录的各种需求。
- 历史数据回溯:支持将性能指标归档存储,便于事后对历史性能问题进行深入回溯和分析。
- 强大的扩展性:提供了Python、Perl、C、C++等多种语言的接口,方便你添加自定义的性能指标。
在Linux环境下,PCP通过Performance Metrics Domain Agent (PMDA) 来收集内核、系统服务、数据库、Web服务器等不同“域”的性能数据。由pmcd守护进程负责管理和路由这些数据,客户端工具则可以实时查询或从归档日志中提取历史记录进行分析。
官方地址:https://pcp.io
Sysdig:系统调用追踪的深度洞察
最后一款工具是Sysdig,它被誉为“系统调用的tcpdump”。它整合了strace、tcpdump、lsof、htop等多个传统命令行工具的功能,提供了一个统一的强大接口,专门用于实时追踪系统调用和诊断系统级故障。
Sysdig的杀手级特性包括:
- 系统调用级监控:能够捕获每一个系统调用,并提供详细的文件、网络、进程参数等信息。
- 强大的过滤能力:支持按进程名、容器ID、文件目录、网络端口、系统调用类型等多个维度进行过滤,精准定位问题。
- 丰富的Chisel脚本:内置了大量预置的分析脚本(Chisels),可以实现一键式完成诸如查看容器网络流量、分析文件访问慢等常见任务。
- 优秀的容器化环境支持:在Docker、Kubernetes环境中表现尤为出色,能够轻松关联容器与系统活动。
在微服务和云原生架构中,Sysdig的价值更加凸显。你可以用它监控特定容器的所有系统调用、追踪容器间的网络流量、分析容器内的异常文件活动,或是快速查看容器内进程的CPU和内存排名,让容器环境的故障排查变得高效而直观。
官方地址:https://sysdig.com
工具选型与实战指南
面对功能各异的工具,该如何选择?关键在于明确你的核心需求,因为它们各有侧重,不存在能解决所有问题的“银弹”。
- 如果你需要:构建应用层的性能指标监控和可视化仪表盘 → 选择 Prometheus C++ Client + Grafana。
- 如果你需要:快速搭建一个全面的实时监控系统,不愿投入过多配置时间 → 选择 Netdata。
- 如果你需要:进行深度的操作系统层面性能分析与长期数据积累 → 选择 PCP。
- 如果你需要:在容器环境中进行故障排查和系统调用级的深度追踪 → 选择 Sysdig。
- 最佳实践:构建完整的可观测性体系 → 组合使用上述工具。例如,用Prometheus+Grafana监控业务指标,用Netdata看护主机健康状态,用Sysdig/PCP对疑难问题进行深度下钻分析。
避坑与最佳实践
工具本身强大,但用对方法才能事半功倍。以下是一些实用的建议:
- 聚焦核心指标:不要试图一开始就监控所有东西。从最关键的少数几个业务和技术指标开始(如核心接口延迟、错误率、资源使用率),再逐步扩展。
- 合理设置告警:避免告警风暴。告警阈值应基于历史基线数据设定,并结合业务敏感度进行调整。定期回顾和优化告警规则,确保每一个告警都 actionable(可行动)。
- 主动趋势分析:不要等问题发生再被动响应。定期查看性能趋势报表,主动发现潜在的性能劣化点,如内存的缓慢增长、延迟的逐步抬升等。
- 关联业务价值:技术指标很重要,但最终要服务于业务。尝试将系统指标(如CPU使用率)与业务指标(如交易成功率、用户活跃度)关联起来综合评估。
结语
C++性能监控与可观测性建设,早已不是锦上添花的选项,而是保障现代软件系统稳定、高效运行的必备环节。选择合适的工具,并掌握其正确使用方法,能让你对程序的运行状态了如指掌,让性能瓶颈和系统故障无处遁形。

希望这5款工具的介绍和选型指南,能帮助你为你的C++项目装上明亮的“眼睛”,从容应对各种性能挑战。如果你在工具使用或性能优化中有更多心得,欢迎在云栈社区与广大开发者交流探讨。
 发表于 2026-3-27 03:38:23
|
查看: 158|
回复: 0
发表于 2026-3-27 03:38:23
|
查看: 158|
回复: 0
