最近,我从负责基础架构的团队转入了具体的业务开发组,开始真正地用上了 Agentic Engineering 的方法论来开发真实项目。依靠纯粹的 Vibe Coding 模式,我已经上线了三个项目,其中两个是已经落地的,包括一个 AI 对话页面和它对应的客户端。
这个过程里,很多原有的认知被刷新了。不过在聊那些“大”的洞察之前,我想先分享一个很小的、却让我彻底改变习惯的发现——关于如何跟AI沟通。
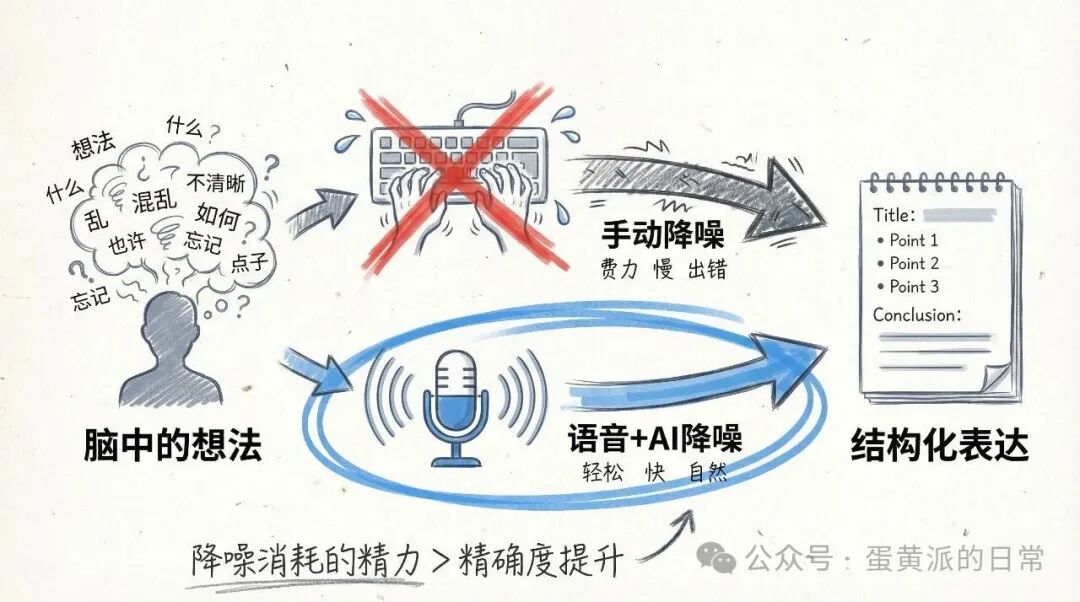
我以前是个坚定的文字输入拥护者,总觉得思想应该自己组织、自己敲出来。但开始纯 AI 开发后,我意识到一个事实:脑子里的想法常常就是一瞬间的念头,把它变成文字的过程,其实是在“降噪”。降噪本身没问题,问题在于,降噪所消耗的精力,往往远大于它带来的那一点点精确度提升。
现在,AI 可以帮你完成这件事。你把模糊的、口语化的想法说出来,它就能帮你整理成结构化的、逻辑清晰的表达。想明白这一点后,我彻底转向了语音输入。现在甚至觉得在手机上打字成了一件痛苦的事——花半天时间敲出的,可能只是脑子里一秒钟就闪过的内容。
我试过微信输入法的语音转文字,但它的体验和 Typeless 这类工具完全不同。微信在做的是“还原”你说过什么,而 Typeless 这类工具在做的是“降噪”——把你的口语变成你真正想表达的那个意思。这两件事,差别巨大。
人变成了审计员
第二个让我印象深刻的发现,是关于新的协作流程。
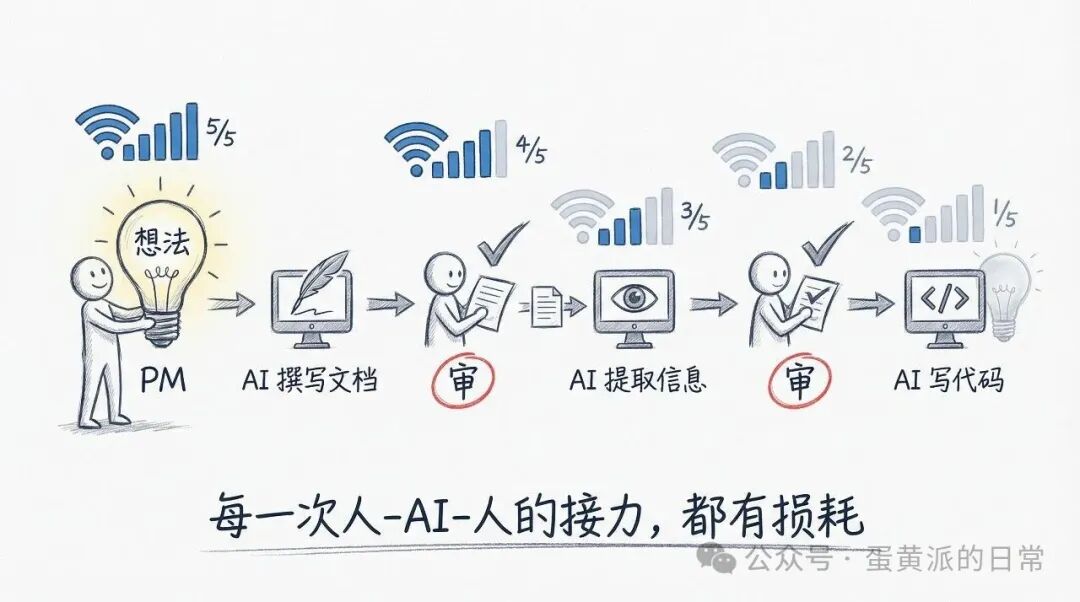
在这个 AI Native 的工作流里,我注意到产品同事的文档已经是 AI 生成的了:他负责出点子,AI 负责撰写,而他则变成了“审计员”,负责审核。文档到我这里后,说实话我也懒得逐字阅读——我会同样让 AI 帮我处理,提取出关键信息和待确认的技术点,然后我再审核一遍技术方案的合理性。
在整个链条中,人的角色发生了根本性转变。我们不再是在“写”,而是在“审”。
这本身没什么不好,审计是一个非常重要的角色。但它引发了我更深层的思考:既然从想法到执行的中间环节,AI 已经能覆盖大部分,那我们为什么不能直接给出一个想法,让 AI 端到端地去执行呢?
目前当然还做不到。但“做不到”的原因,与其说是 AI 不够聪明,不如说我们还没有建立起足够高效的上下文传递机制。产品同事的原始意图,在经历了“AI写文档”和“我用AI读文档”这两层转换后,信息损耗不小。每一次人-AI-人的接力,都存在损耗。
这个观察,引出了我这段时间思考最多的一件事。
Spec 不是越多越好
我在开发中大量使用了 Spec-driven 的方式。简单说,就是在让 AI 写代码前,先写清楚这个功能的约束条件、设计决策和边界。
听起来很合理,对吧?初期也确实非常好用。但在完成三个项目后,我遇到了一个反直觉的问题:Spec 写得越多,反而成了一种负担。
负担体现在两个层面。
第一是上下文窗口的消耗。Spec 会占用宝贵的 AI 上下文。如果你把所有的约束都塞进去,AI 反而会在“理解 Spec”这件事上消耗太多“注意力”,留给实际编写代码的“思考”空间就变小了。
更关键的是,很多 Spec 写的是“代码应该怎么写”——用什么模式、什么代码风格、什么命名规范。但这些信息,其实你不需要告诉 AI。你项目里已有的代码,本身就是最丰富的上下文,AI 会自动从中学习你的风格和模式。你没必要再写一份 Spec 去描述它。
真正需要写进 Spec 的,是那些 AI 无法从现有代码中自行推断出来的业务决策。比如:
- 为什么这个用户数据不能缓存在本地,必须每次请求服务端?
- 这个页面的缓存应该在什么时候清除?是用户离开页面就清,还是需要持久化一段时间?
- 为什么这个复杂的筛选逻辑不能放在前端做?或者反过来,为什么必须由前端来处理?
这些都是业务和架构层面的“为什么”,而不是技术实现的“怎么做”。AI 能从代码里看到你用了 useState 还是 localStorage,但它无法知道你选择这个方案背后的业务考量。Spec 应该记录的就是这些“为什么”。
第二个层面的问题更棘手。到现在,我已经积累了超过300个需求的 Spec。但说实话,我自己都不想回头去读它们。
人不想读300份文档,AI 也一样——它不知道什么时候该去翻哪份 Spec,更不知道哪些 Spec 还有效、哪些已经过时了。
这让我开始设想:在 AI 协作的体系中,或许我们需要一种“记忆”机制,它应该包含主动的“遗忘”功能。让重要的信息浮现,不重要的则自动下沉。就像人的大脑,并非所有经历都值得记住,关键是在需要时能准确调取关键信息。
我不是说这些 Spec 应该被删除。也许未来更大的上下文窗口、更智能的检索技术会让它们重新变得有价值。但在现阶段,我们确实缺少一个有效管理和利用这些历史沉淀的好方法。

你看不见 AI 改了什么
第四个发现与团队协作有关,而且这个问题比较隐蔽。
以往人和人协作时,有一个很自然的过程:我把 A 和 B 两个函数抽象成一个公共模块,完成后我会告诉团队所有人——以后都用这个公共模块,别再自己写一遍。大家知道了,下次遇到类似场景就会复用。
但在 AI 协作的环境下,这个“通知”链条断了。
AI Agent 可能已经把代码抽成了公共模块,但除了让它这么做的那个开发者,团队里其他人都不知道。更麻烦的是,即便你广而告之,下次大家写代码时用的也是 AI。你不可能在每一个需求描述里都写上“注意,这里有个 utils/formatDate.js 可以用”——你只能告诉 AI “如果有现成的公共函数,就复用,别自己造轮子”。
但它到底听没听话?有没有发现那个公共函数?你无从知晓。
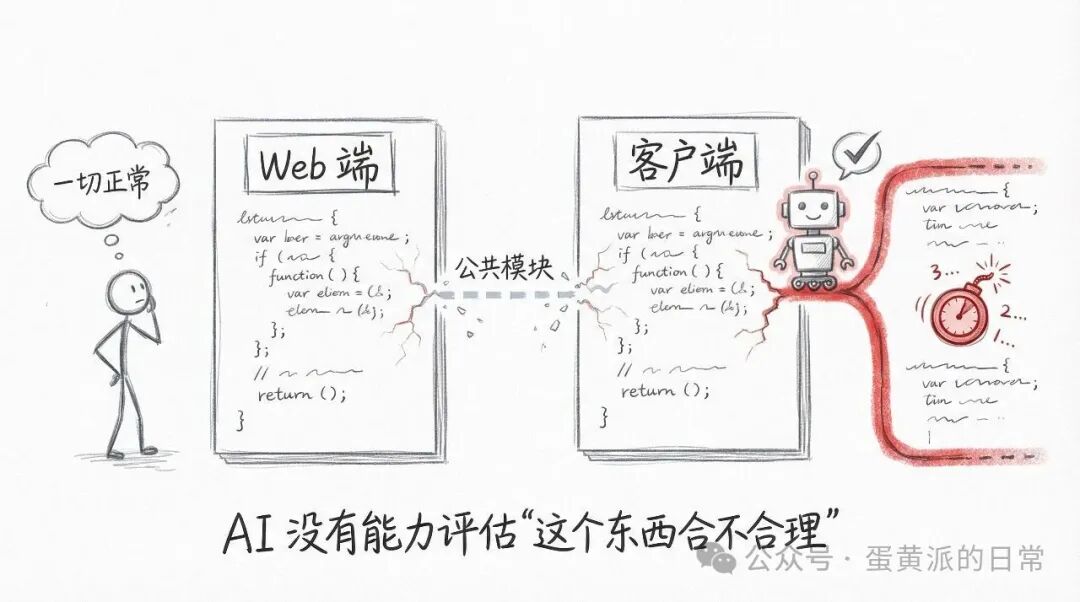
我们遇到过一个真实案例:一个日期格式化功能在 Web 端和客户端都有实现,本应复用同一套逻辑。但 AI 在开发客户端时,看了一眼 Web 端的实现,觉得有点复杂(可能包含了不必要的时区处理),就自己写了一套更轻量的。功能完全正确,测试也通过了。但后来 Web 端因为业务需求调整了逻辑,客户端那边就被遗忘了——因为没人知道那里还有一份逻辑相似的“副本”。
这个问题,只有在测试阶段才有可能被发现,而且还得靠人去发现。AI 没有能力去评估“这个实现方案在全局视角下是否合理”,因为它缺乏项目的全局视野。
说到底,AI 写得比你快、比你多,它的实现思路可能跟你完全不同。你已经不可能逐行审查它的每一个微决策了。那么,接下来的核心问题就变成了:如何建立一种可观测的机制,让 AI 系统能自行保持代码和逻辑的一致性? 如何让一个 AI Agent 团队能自己从80分演进到90分,而不是靠你手动把它从80分一点点改到90分?
我还在思考这个问题的答案。
卓越和通用不可兼得
最后一点,是关于企业如何拥抱 AI 开发这件事的观察。
我看到很多公司都很着急。AI 发展这么快,大家都想赶紧搞出一个“开发平台”或者一套标准作业程序 (SOP),让所有开发者照着做,就都能产出质量不错的代码。
我理解这种迫切,但我认为这条路很难走通。
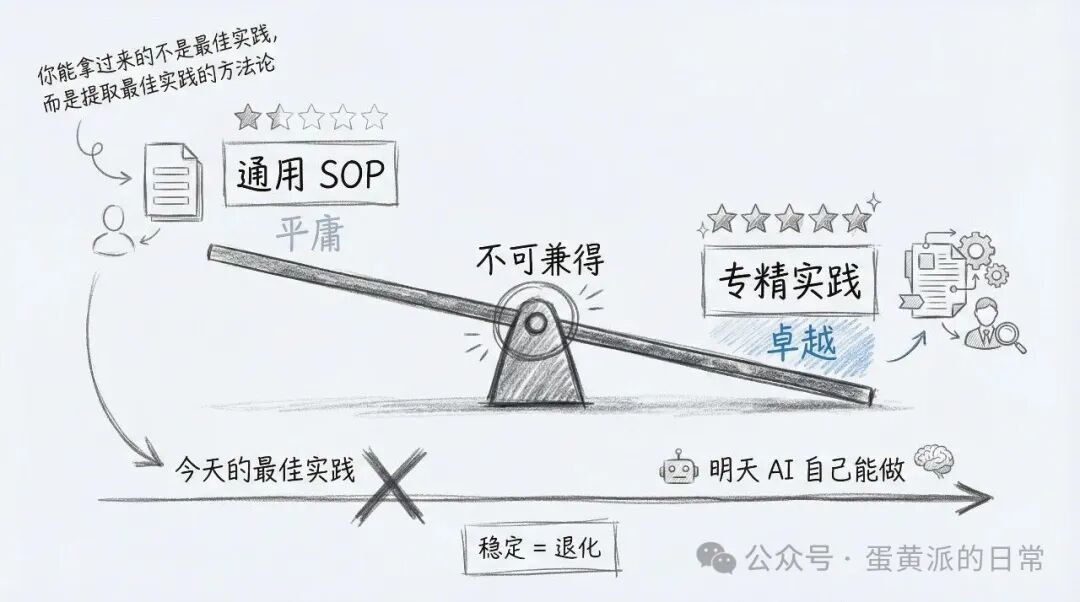
原因很简单:如果你的 SOP 设计得非常通用,那它注定会变得平庸。通用,意味着它要覆盖所有可能的场景,不能对任何具体业务做太强的假设。但现在的 AI 模型本身就已经具备了不错的通用能力,你这份“通用”SOP 的效果,可能还不如直接让模型自由发挥。
反过来,如果你的 SOP 写得非常具体、极具针对性,那它就必然失去通用性。它可能只适用于你们团队当前的业务、特定的技术栈和代码规范。换一个项目,这套 SOP 可能就完全失灵了。
你想让它卓越,就必须接受它偏科。你想让它通用,就必须接受它平庸。
很多管理者可能会想:“我能不能把业界或者隔壁团队验证过的最佳实践直接拿过来用?”大概率不行。你能借鉴的,不是最佳实践本身,而是“如何从自身实践中提取出最佳实践”的方法论。每个团队、每个项目,都需要从自己的土壤里,生长出适合自己的那一套工作流。
还有一个更根本的挑战:AI 本身在高速进化。你今天花大力气设计的 Spec-driven 流程、精心编写的 tasks.md,现在对 AI 来说非常好用。但也许一年后,AI 自己就能从需求描述中发现并拆解任务,你这个固化的任务清单反而会限制它的思维——它会困惑“我到底是该严格遵循 tasks.md,还是按我自己的理解来?”,而那份 tasks.md 很可能已经过时了。
所以,我现在的看法是:我们使用的工具和流程,应该随着 AI 模型的迭代而不断演进和调整,而不是去追求一个一劳永逸、稳定不变的“终极版本”。在这个领域,追求稳定本身,可能就意味着一种退化。
没有结论的结尾
三个项目做下来,我最大的感受既不是“AI 真厉害”,也不是“AI 还不行”,而是:我们和 AI 的协作方式,整体上还处在一个非常早期的探索阶段。
Spec 究竟该写到什么粒度?团队的“记忆”该如何管理?协作中的一致性如何保障?企业级的 SOP 到底要不要搞、怎么搞?——对于这些问题,我都没有确定的答案。我能确定的只有一点:用三个月前的经验来指导今天的 AI 开发实践,大概率是会出错的。
所以,我选择把这些零散的观察记录下来,并非因为我已想清楚了要传递什么结论,而是觉得在这个所有人都在摸索前行的阶段,探索的过程本身,或许比任何一个暂时的结论都更有价值。
如果你也在进行类似的 AI Native 开发实践,遇到了有趣的挑战或踩过坑,欢迎来 云栈社区 一起聊聊。
 发表于 2026-3-28 08:05:21
|
查看: 144|
回复: 0
发表于 2026-3-28 08:05:21
|
查看: 144|
回复: 0
