上一篇我们探讨了 Kafka 的基础角色:Producer、Consumer、Topic 和 Partition。在实际的生产环境中,保障服务高可用、数据不丢失是更核心的诉求。本文将一次性讲清楚副本(Replica)、ISR、偏移量(Offset)以及消费者组的进阶逻辑,帮助你掌握 Kafka 实现高可用的底层机制。
一、核心概念回顾
- Topic(主题):消息的逻辑分类,类似于一个文件夹。
- Partition(分区):消息实际存储的物理单元,是 Kafka 实现高吞吐量的关键。
- Producer(生产者):负责发布消息到指定 Topic。
- Consumer(消费者):负责从 Topic 订阅并读取消息。
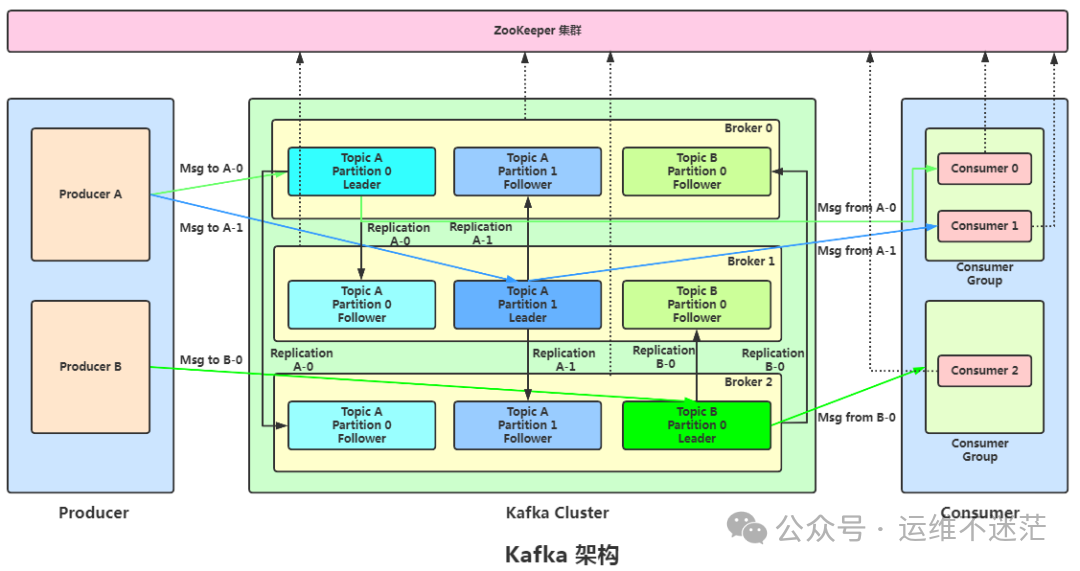
二、副本(Replica)— 高可用的基石
1. 什么是副本?
简单来说,副本就是分区的备份。一个分区可以配置多个副本,这些副本分散存储在不同的 Broker(Kafka 服务器节点)上。副本分为两种角色:
- Leader 副本:如同“班长”,所有生产者的写入和消费者的读取请求,都只由 Leader 副本处理。
- Follower 副本:如同“组员”,其职责是持续地从 Leader 副本同步数据,进行备份,自身不对外提供读写服务。
2. 副本的核心作用
- 数据安全:防止因单台机器宕机导致数据永久丢失。
- 故障转移:当 Leader 副本所在的 Broker 发生故障时,系统可以从 Follower 副本中选举出一个新的 Leader,实现服务的自动恢复。
可以说,没有副本的 Kafka 是在“裸奔”;引入了副本机制,才真正构建起 高可用 的基础。
三、ISR 机制 — 保障数据一致性与选举效率
1. 什么是 ISR?
ISR(In-Sync Replicas)即“在同步中的副本集合”,指的是那些与 Leader 副本保持数据同步的 Follower 副本列表。
2. ISR 机制的作用
在 分布式系统 中,如果某个 Follower 副本由于网络或自身原因同步过慢甚至卡住,Leader 不能无限期地等待它。Kafka 的 ISR 机制就是解决这个问题的:只有那些同步进度跟上 Leader 的 Follower 才会被纳入 ISR 列表。当 Leader 故障需要选举新 Leader 时,候选者必须来自 ISR 列表。这个机制有两大好处:
- 保证数据一致性:确保新 Leader 拥有最新的数据,避免消息丢失或重复。
- 提升选举速度:避免了等待落后副本而导致的长时间服务不可用。
通俗理解:
- Leader 是班长,Follower 是组员。
- ISR 列表 = 那些能跟上进度、按时“交作业”的组员名单。
- 班长(Leader)出事了,新班长只能从这个名单里选。
四、偏移量(Offset)— 消息的“身份证”
1. Offset 的含义
消息被写入分区后,会被分配一个自增的、唯一的、永不改变的序列号,这就是 Offset(偏移量)。
- 从 0 开始递增。
- 只在当前分区内唯一。
- 消息一旦写入,其 Offset 就固定不变。
2. Offset 的核心作用
- 消费进度记录:消费者通过记录自己已消费的 Offset,可以明确知道读到了哪条消息。
- 消费位置恢复:消费者重启或发生重平衡(Rebalance)后,可以从上次提交的 Offset 位置继续消费,实现“断点续传”。
- 数据重处理:可以指定一个更早的 Offset 让消费者重新消费,常用于数据重跑或回溯分析场景。
简言之,Offset 就是消息在分区中的精确位置坐标。
五、消费者组(Consumer Group)— 必须理解的消费模型
消费者组是 Kafka 实现横向扩展消费能力的基础架构。其工作机制有几个关键点:
- 广播与独立消费:一个 Topic 可以被多个不同的消费者组同时消费。消息会发送给所有订阅了该 Topic 的消费者组,各组消费进度互不影响。这常用于将同一份数据提供给不同业务系统使用。
- 组内分区独占:在同一个消费者组内部,一个分区在任一时刻只能被组内的一个消费者实例消费。 这是 Kafka 保证消息在分区内顺序消费的核心规则。
- 消费者与分区的数量关系:一个消费者组内的消费者实例数量,应小于等于其订阅 Topic 的分区总数。如果消费者数量超过分区数,多出来的消费者会处于空闲状态,不会分配到任何分区。
性能与扩展性启示:
- 想提高单个消费者组的消费速度?增加 Topic 的分区数,并相应增加组内的消费者实例。
- 想让多套业务系统独立消费同一份数据?为每套系统创建不同的消费者组即可。
六、总结
我们来串联一下 Kafka 实现高可用、高吞吐、不丢消息的核心逻辑链:
- 一个 Topic 被划分为多个 Partition 以实现并行处理。
- 每个 Partition 配置多个副本(1 Leader + N Follower),实现数据冗余。
- Follower 副本持续同步 Leader 数据,同步跟上的进入 ISR 列表。
- 每条消息在分区内拥有唯一的 Offset 标识。
- 消费者组内的消费者按照 Offset 顺序消费分配到的分区,组间消费互不干扰。
理解副本、ISR、偏移量和消费者组这四者的协同工作原理,是掌握 Kafka 作为企业级消息中间件的关键。希望本文能帮助你构建起清晰的知识脉络。如果想深入交流更多关于系统架构设计的实践,欢迎访问云栈社区与广大开发者一同探讨。 |  发表于 2026-3-29 03:32:50
|
查看: 188|
回复: 0
发表于 2026-3-29 03:32:50
|
查看: 188|
回复: 0
