在上一篇文章操作系统是如何启动的中,我们提到了实模式和保护模式,但未深入探讨。今天,我们就来系统性地剖析这两个关键的 CPU 工作模式。在开始之前,不妨先看一个来自极客时间《操作系统实战45讲》的例子,它能非常形象地说明引入保护模式的必要性。
请看下面这段 C 语言代码:
int main()
{
int* addr = (int*)0;
cli(); //关中断
while(1)
{
*addr = 0;
addr++;
}
return 0;
}
如果这段代码能被顺利执行,后果将非常可怕。它直接获取了内存地址 0,并开始顺序向下遍历,肆意向内存写入数据。更关键的是,它还关闭了中断(cli())。想象一下,在一台多人共享的服务器上,一旦某个用户的进程执行了这段代码,所有其他用户留在内存中的数据都会被无情地清零,且在此过程中你无法通过中断来终止这个“破坏者”进程。
这段代码所体现的,正是实模式下的内存访问方式。实模式的主要特点在于其寻址方式,而这种寻址方式也直接导致了其在寻址范围和保护性上的局限性。现代操作系统中保留实模式,主要是为了兼容早期的系统。通常,在加载bootsect.s以及由bootsect.s执行载入setup和system模块的阶段,CPU 运行在实模式下;之后,便会切换到功能更强大的保护模式。接下来,我们将分别深入这两种模式的工作原理。
Part1:实模式下的寻址
为了更直观地理解实模式,我们先回顾一下 BIOS 的加载过程,这正是实模式在工作的典型场景。BIOS 由硬件厂商预先烧录在 ROM 中,其物理地址被固定在 0xFFFF0。CPU 上电后,首要任务就是找到并执行这个地址的指令。
那么,在实模式下,CPU 如何表示一个指令在内存中的位置呢?它通过两个 16 位的寄存器协同工作:CS(Code Segment,代码段)寄存器和IP(Instruction Pointer,指令指针)寄存器。CS 寄存器存放段基址,IP 寄存器存放偏移量。
这里简单解释一下“段”的概念。了解汇编语言就会知道,程序代码通常被划分为多个逻辑段,例如代码段、数据段等。程序载入内存时,也是按段加载的。因此,取指令时就需要先找到段的起始位置(基址),再加上段内的偏移,才能得到最终的物理地址。
具体计算方法如下:将 CS 寄存器中的值左移 4 位(二进制),然后加上 IP 寄存器的值。以寻找 BIOS 地址为例,假设 CS 为 0xFFFF,IP 为 0x0000。0xFFFF 左移 4 位(十六进制视角下相当于乘以 16)得到 0xFFFF0,再加上 0x0000,最终物理地址就是 0xFFFF0。这样,CPU 就成功定位到了 BIOS 的起始指令。
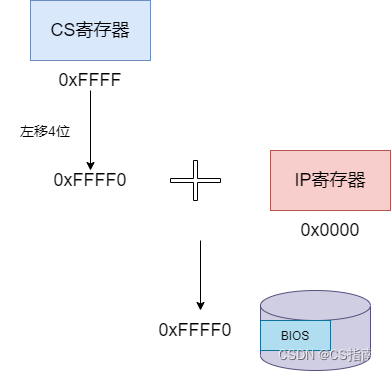
之所以要将 CS 左移 4 位,是因为 CS 和 IP 都是 16 位寄存器,单独只能寻址 64KB 的空间。通过“(CS << 4) + IP”这种计算方式,形成了 20 位的有效地址,使得实模式下的寻址范围达到了 1MB。
然而,1MB 的寻址范围对于现代计算机来说实在太小了(即便是 32 位 CPU,其 CS 寄存器在实模式下依然是 16 位的)。这构成了实模式的一大主要缺陷。那么,保护模式是如何突破这个限制的呢?
Part2:保护模式的革新与内存保护
对于 32 位计算机而言,仅能寻址 1MB 内存显然不够。理论上,32 位地址总线应能寻址 4GB 空间。但为了保持向后兼容(例如在加载 BIOS 和最初引导阶段仍需使用实模式寻址),CS 寄存器仍然保持 16 位宽度,只是用于存放偏移的寄存器扩展成了 32 位的 EIP。
为了适应这种变化,保护模式下 CS 寄存器中存储的不再是直接的段基址,而是一个称为“段选择子(Segment Selector)”的索引。段选择子的低 2 位用于权限控制,高 13 位则是一个索引号,用于查找全局描述符表(GDT, Global Descriptor Table)。

CPU 根据段选择子中的索引,在 GDT 中找到对应的“段描述符(Segment Descriptor)”。段描述符中包含了真正的 32 位段基址、段长度界限以及各种访问权限属性。最后,将段描述符提供的段基址与 EIP 中的 32 位偏移相加,就得到了最终的线性地址(再经过分页机制转换得到物理地址)。
这个 GDT 表至关重要,它不仅是实现扩展寻址的关键,更是实现内存管理和保护机制的基石。让我们看看段描述符中几个关键字段的作用:
- 段基址:与实模式类似,但现在是完整的 32 位地址。
- 段界限:规定了段内偏移地址的最大范围。如果程序试图访问超出此界限的地址,CPU 会触发异常,从而阻止非法访问。
- 描述符特权级(DPL):定义了访问该段所需的CPU特权级别。只有当段选择子中记录的当前特权级(CPL)满足 DPL 要求时,访问才被允许。这为实现用户态与内核态的隔离提供了硬件支持。
- 类型字段:明确标识该段是代码段还是数据段,并规定其可读、可写、可执行等属性。
可以看出,GDT 对每个内存段的性质(代码/数据)、大小、位置和访问权限都做了精确描述。每次通过段选择子访问内存时,CPU 都会自动进行一系列严格的检查。
下面这张流程图清晰地展示了保护模式下完整的取指过程:
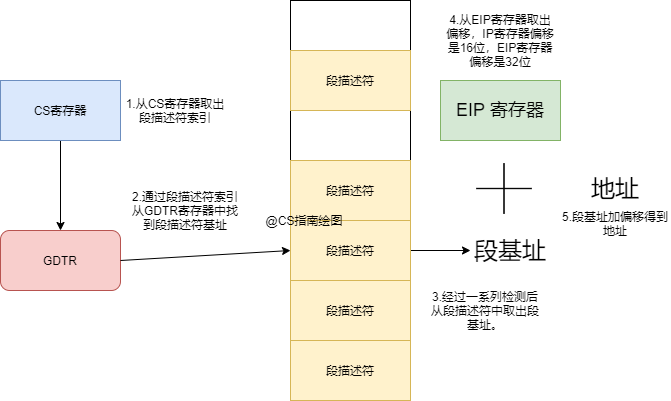
通过对比可以发现,保护模式通过引入段描述符和权限检查机制,从根本上解决了实模式的两个核心问题:一是将寻址能力从 1MB 扩展到了 4GB(32位下),二是为内存访问提供了硬件级别的安全保护,防止了文章开头那段“破坏性”代码的执行。理解这两种模式的差异,是深入学习操作系统内核与系统编程的重要基础。想了解更多计算机底层原理的深入讨论,可以关注云栈社区的相关技术板块。
 发表于 2026-3-29 04:25:12
|
查看: 137|
回复: 0
发表于 2026-3-29 04:25:12
|
查看: 137|
回复: 0
