https://arxiv.org/pdf/2603.20309
BubbleRAG: Evidence-Driven Retrieval-Augmented Generation for Black-Box Knowledge Graphs

大语言模型(LLMs)在处理知识密集型任务时,常常会遇到幻觉问题,并且其训练数据的静态性也容易导致知识过时。RAG(检索增强生成)通过引入外部知识来缓解这一困境,其中基于知识图谱(KG)的RAG能够显式地建模跨文档依赖关系,从而支持更结构化的推理过程。
然而,现有方法在面对黑盒知识图谱(即图谱的模式、实体类型和关系结构对外部系统未知)时,仍然存在一些根本性的挑战。
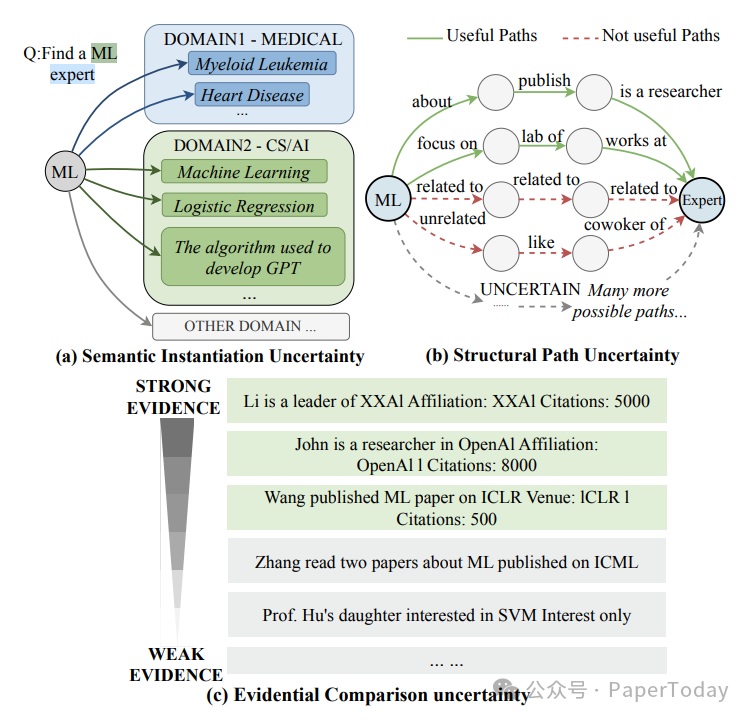
如上图所示,主要存在三方面的不确定性:
- 语义实例化不确定性:查询中的概念可能在图谱中以多种形式存在。例如,查询中的“ML”可能指代医学领域的“Myeloid Leukemia”(髓系白血病),也可能指代计算机科学领域的“Machine Learning”(机器学习)。这种概念歧义会导致检索召回不全。
- 结构路径不确定性:由于缺乏图谱的schema知识,系统难以确定连接不同实体的最优关系路径,导致检索到的证据子图结构不完整或不准确。
- 证据比较不确定性:知识图谱通常不会显式编码像“专业性”这样的抽象概念。要判断某个实体是否是“专家”,需要聚合多个隐式的信号(如论文发表、引用次数、所属机构)并进行排序,这个过程容易引入误差,导致检索精度下降。
方案
BubbleRAG是一个无需训练的即插即用框架。它将检索过程形式化为一个最优信息子图检索(OISR)问题,这本质上是Group Steiner Tree问题的变体,并被证明是NP-hard和APX-hard的。其整体流程如下图所示:
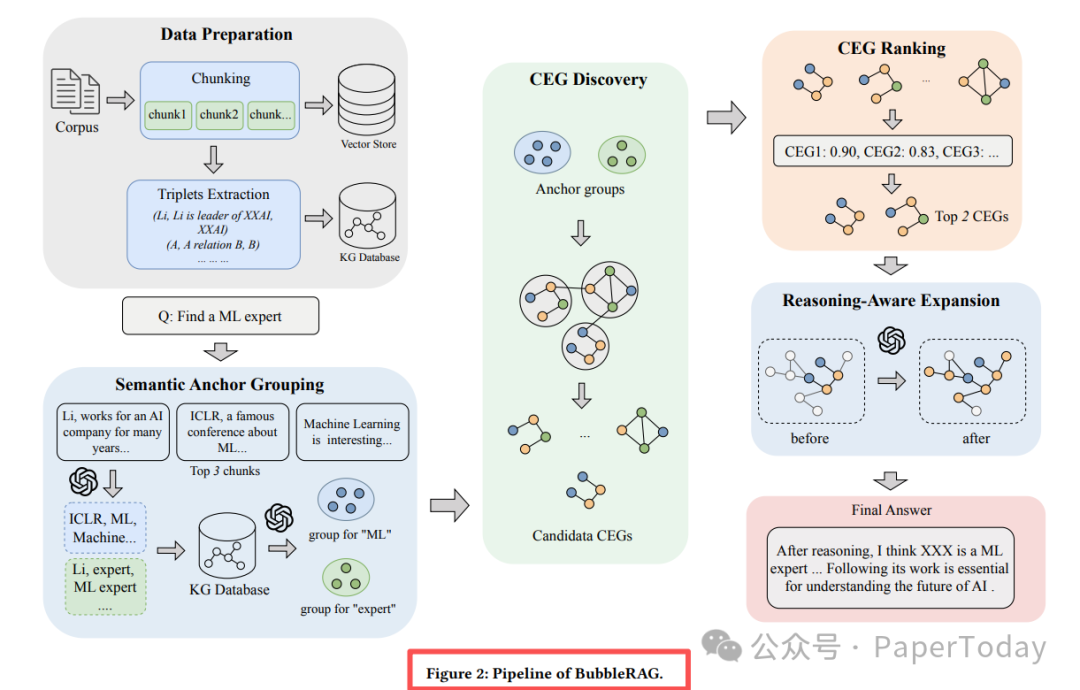
1. 语义锚点分组
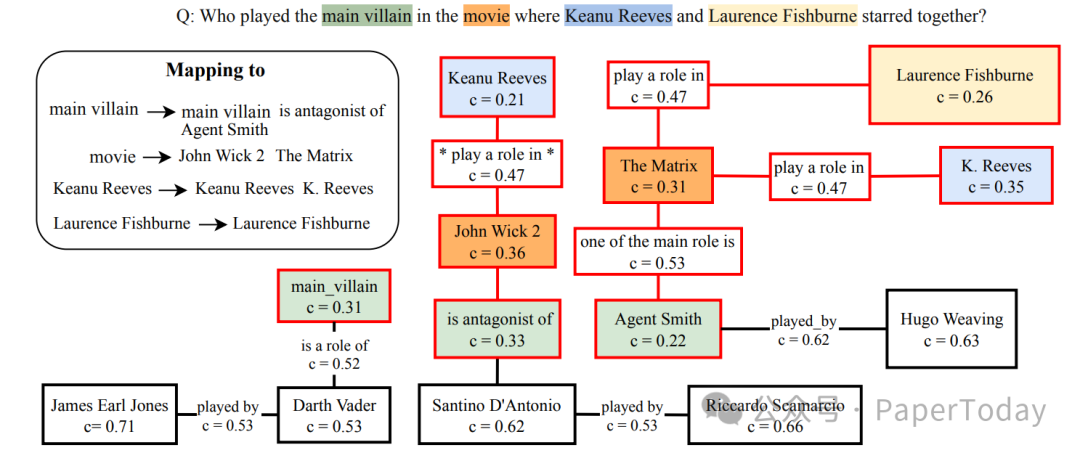
为了应对黑盒图谱中概念的异构性,BubbleRAG会先利用LLM来提取查询中的关键词,并推断其潜在的概念。系统将每个查询概念映射到一组候选锚点,而不是单一的节点,从而容忍别名和schema的变化。同时,它引入了锚点特化(例如,将“mother”细化为“Lothair II‘s mother”)和schema松弛机制,在保持高召回率的同时提升了精度。
2. 候选证据图发现
基于“拓扑凝聚”的思想,BubbleRAG采用了一种称为 “Bubble Expansion” 的启发式算法。该算法从各个锚点组出发,进行各向异性的扩展(优先通过语义相关性高的区域)。当代表不同概念的“气泡”相互碰撞时,它们就会融合形成一个连通的子图,即候选证据图(CEG)。
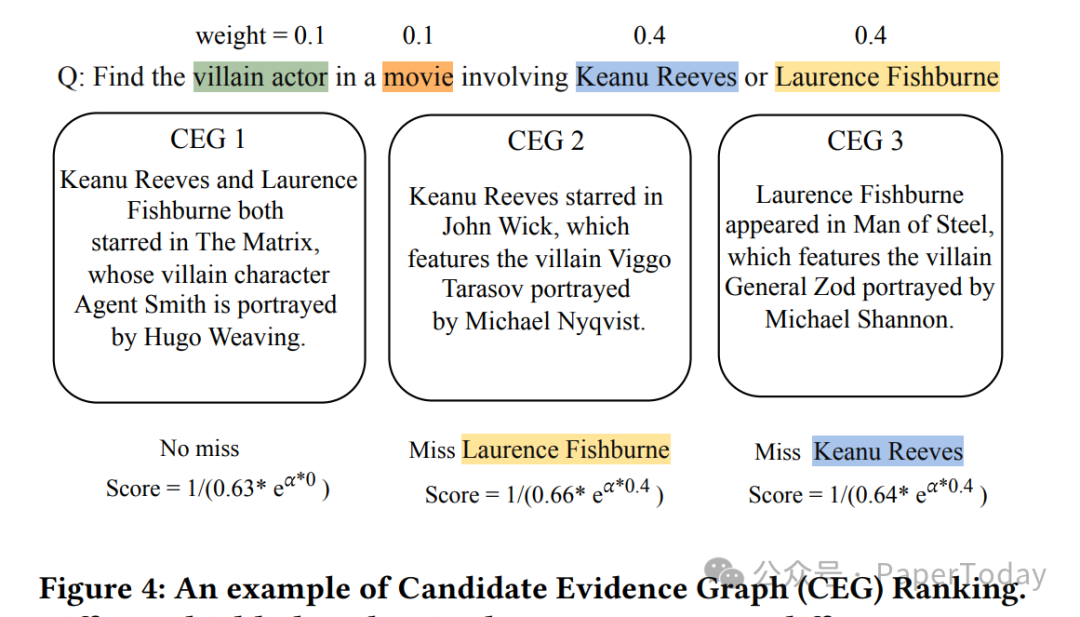
3. 复合排序
系统通过一个复合评分函数来平衡CEG的语义相关性和结构完整性。该函数会根据锚点组的重要性权重,对缺失关键组的候选进行惩罚。通过调节超参数,BubbleRAG可以灵活地支持AND(严格交集)、OR(宽松并集)以及比较类查询,而无需修改整体架构。
4. 推理感知扩展
对排序后靠前的Top-n个CEG,系统会利用LLM进行可控深度(例如 $k$ 跳)的多步扩展,以精确定位最终的答案实体(例如,从“《黑客帝国》这部电影”扩展到“其反派角色的扮演者”)。最终,将扩展后得到的证据子图与相关的原始文本块进行融合,生成最终的答案。
这套方案通过构建局部子图,将计算复杂度与全局图谱的规模解耦,在保持高效性(平均20.99秒/查询,显著快于ToG的45.93秒)的同时,系统性地优化了在黑盒KG上的检索召回率与精度。
结论
实验结果表明,BubbleRAG在复杂的多跳问答基准(包括HotpotQA、MuSiQue、2WikiMultiHopQA)上达到了SOTA性能。如下表所示,在使用30B参数模型时,BubbleRAG的平均F1分数和准确率分别比最强基线HippoRAG2高出2.52%和2.23%。
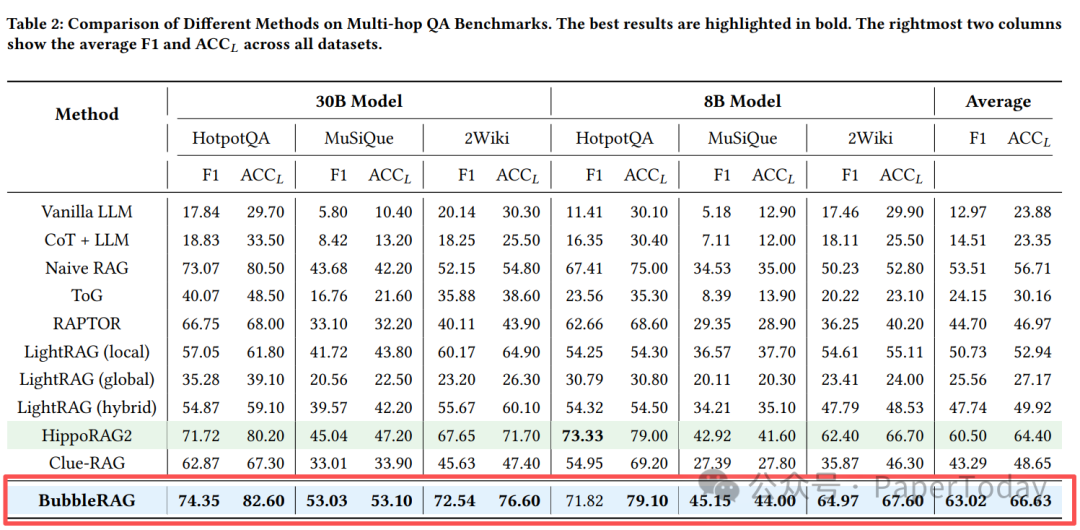
在最具挑战性的MuSiQue数据集(通常需要3-4跳推理)上,BubbleRAG取得了53.03的F1分数,领先HippoRAG2约8个百分点。即使在使用8B小模型的情况下,BubbleRAG的平均F1分数(63.02)仍然可以与许多使用30B模型的基线方法相媲美,这证明了高质量的检索能有效弥补模型规模的不足。消融实验进一步表明,其中引入的schema松弛机制对整体性能的提升最为关键。
BubbleRAG为黑盒知识图谱上的RAG应用提供了一种新颖且有效的解决方案,特别是在处理需要复杂推理的多跳问答场景时优势明显。想了解更多关于信息检索与知识图谱的前沿技术讨论,欢迎访问云栈社区的人工智能板块与其他开发者交流。 |  发表于 2026-3-30 00:57:29
|
查看: 146|
回复: 0
发表于 2026-3-30 00:57:29
|
查看: 146|
回复: 0
