“用户下单失败,如何快速定位问题?”这个京东经典面试题,考察的正是分布式系统的可观测性设计能力。本文将系统性讲解微服务架构下实现全链路追踪的原理、技术选型、实战部署以及京东级别的优化经验。
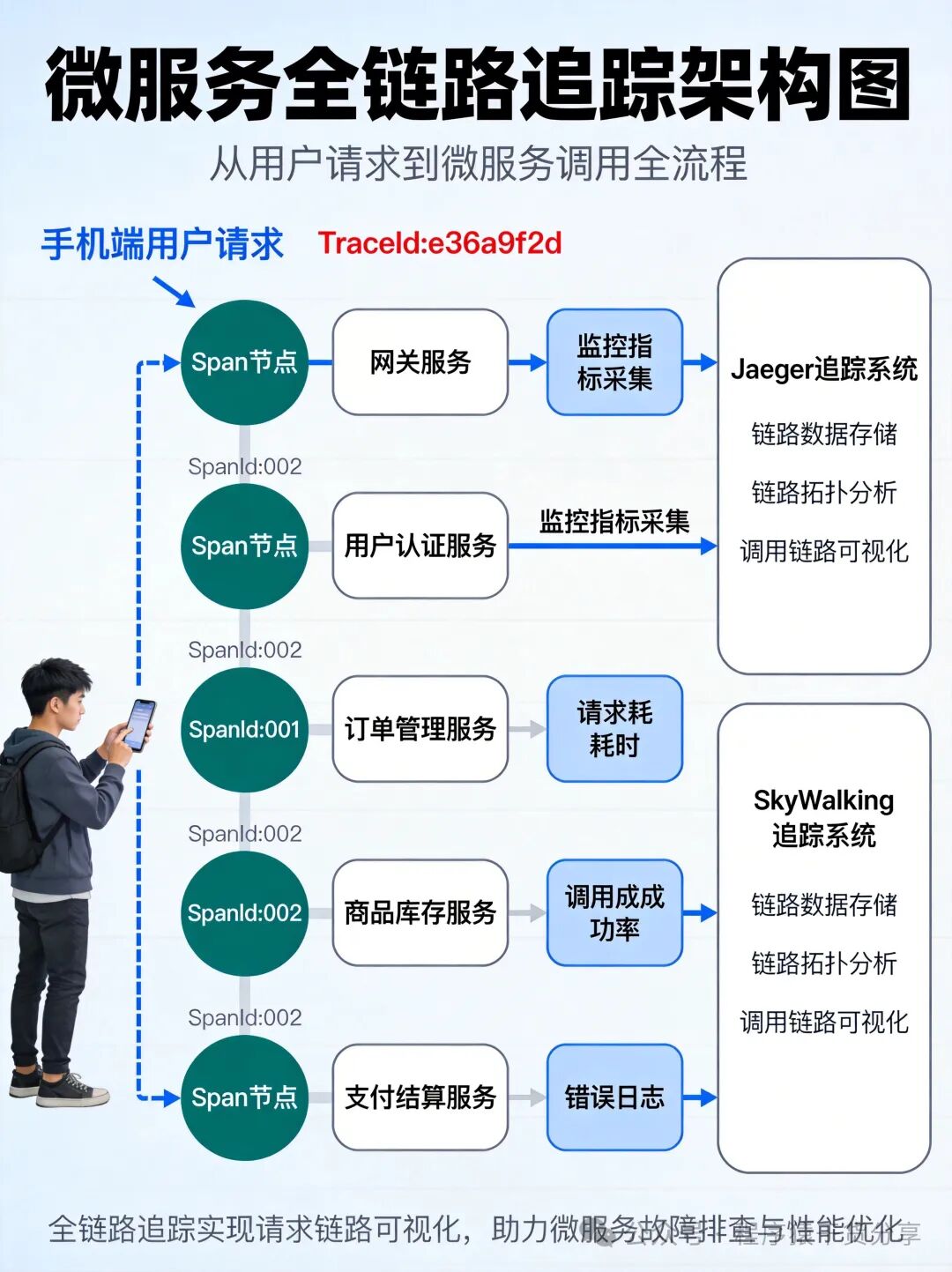
一、为什么需要全链路追踪?
微服务的痛点
在单体应用时代,一个请求的完整调用栈一目了然。但当业务拆分为一个个独立的微服务后,调用链变得错综复杂:
用户下单 → 订单服务 → 库存服务
↓ ↓
支付服务 优惠券服务
这时,我们会遇到几个典型问题:
接口响应慢:用户抱怨系统卡顿,但你不知道瓶颈究竟卡在网关、订单服务还是底层的数据库查询。
偶发性失败:某个请求莫名其妙失败了,难以复现,更难以定位是哪个环节出了问题。
性能优化无头绪:想提升系统整体性能,却不知道该从哪个服务、哪个接口下手优化。
全链路追踪正是为解决这些问题而生,它的核心价值在于:
- 故障定位:将问题定位时间从小时/分钟级缩短到秒级。
- 性能分析:可视化地识别出慢查询、慢依赖,让优化有的放矢。
- 容量规划:基于真实的调用链路和耗时数据,进行更科学的资源分配与容量规划。
二、核心概念:Trace 与 Span
数据模型
理解全链路追踪,首先要掌握两个核心概念:
Trace(追踪):代表一个完整的请求链路。从请求发起到最终响应,这整个过程的轨迹称为一个Trace,全局唯一。
Span(跨度):代表Trace中的一个操作单元,通常对应一次服务调用、一次数据库查询或一段业务逻辑。一个Trace由多个具有父子关系的Span组成。
TraceId: abc123...
├─ Span1: 网关接收请求 (0ms → 5ms)
├─ Span2: 订单服务 (5ms → 50ms)
│ ├─ Span2.1: 库存扣减 (10ms → 25ms)
│ ├─ Span2.2: 支付调用 (25ms → 45ms)
│ └─ Span2.3: 日志记录 (45ms → 50ms)
└─ Span3: 响应返回 (50ms → 55ms)
TraceId 传递机制
为了实现跨服务的链路串联,TraceId 和 SpanId 需要在服务间传递。常见的传递方式有:
HTTP 头传递:
GET /order/create HTTP/1.1
X-Trace-Id: abc123...
X-Span-Id: span001
RPC 框架传递(以Dubbo为例):
RpcContext.getContext().setAttachment("X-Trace-Id", traceId);
RpcContext.getContext().setAttachment("X-Span-Id", spanId);
三、技术选型:主流方案对比
面对众多的开源方案,如何选择?下表对比了三种主流方案:
| 方案 |
优势 |
劣势 |
适用场景 |
| SkyWalking |
国产化友好、APM功能全面、可视化强 |
对代码有一定侵入性 |
Java技术栈为主的中大型项目 |
| Jaeger |
云原生亲和、性能出色、由Uber开源 |
界面相对简洁,功能聚焦追踪 |
Go语言或云原生微服务架构 |
| Zipkin |
轻量、生态丰富、社区成熟 |
功能相对基础,APM能力弱 |
快速验证原型或轻量级追踪需求 |
京东的实践:在实际生产环境中,京东采用了 SkyWalking 与 Jaeger 混合使用的策略,根据不同业务线和技术栈的特点进行选型。
四、实战:SkyWalking 部署与集成
快速部署(Docker 方式)
SkyWalking 分为后端收集器(OAP)和前端界面(UI)两部分。
-
部署 OAP 服务:
# Docker部署OAP
docker run -d --name skywalking-oap \
-p 11800:11800 -p 12800:12800 \
apache/skywalking-oap-server:8.9.1
-
部署 UI 界面:
# Docker部署UI
docker run -d --name skywalking-ui \
-p 8080:8080 --link skywalking-oap:oap \
-e SW_OAP_ADDRESS=oap:12800 \
apache/skywalking-ui:8.9.1
部署完成后,访问 http://localhost:8080 即可看到SkyWalking控制台。
Java 应用接入(Agent 方式)
对于Java服务,通常通过Java Agent实现无侵入或低侵入的埋点。
java -javaagent:/path/to/skywalking-agent.jar \
-Dskywalking.agent.service_name=order-service \
-Dskywalking.collector.backend_service=127.0.0.1:11800 \
-jar order-service.jar
自定义埋点
对于Agent无法自动捕捉的关键业务逻辑,可以进行手动埋点。
@Trace
public Order createOrder(OrderRequest request) {
AbstractSpan span = ContextManager.createLocalSpan("createOrder");
span.tag("order.id", request.getOrderId());
span.tag("user.id", request.getUserId());
try {
return orderService.create(request);
} finally {
ContextManager.stopSpan();
}
}
五、Jaeger 实战:云原生方案
Kubernetes 部署
对于已经拥抱云原生的团队,使用Kubernetes部署Jaeger更为便捷。
apiVersion: apps/v1
kind: Deployment
metadata:
name: jaeger
spec:
replicas: 1
selector:
matchLabels:
app: jaeger
template:
metadata:
labels:
app: jaeger
spec:
containers:
- name: jaeger
image: jaegertracing/all-in-one:1.50
ports:
- containerPort: 16686
---
apiVersion: v1
kind: Service
metadata:
name: jaeger
spec:
selector:
app: jaeger
ports:
- port: 16686
targetPort: 16686
Go 语言集成示例
Jaeger 在 Go 微服务生态中集成非常方便。
import "github.com/opentracing/opentracing-go"
import jaegercfg "github.com/uber/jaeger-client-go/config"
// 初始化Jaeger Tracer
func initJaeger(serviceName string) (opentracing.Tracer, io.Closer) {
cfg := jaegercfg.Configuration{
ServiceName: serviceName,
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
},
}
tracer, closer, _ := cfg.NewTracer()
opentracing.SetGlobalTracer(tracer)
return tracer, closer
}
// 在业务函数中埋点
func CreateOrder(ctx context.Context, req OrderRequest) error {
span := opentracing.StartSpan("CreateOrder")
defer span.Finish()
span.SetTag("order.id", req.OrderID)
// 业务逻辑...
return nil
}
六、京东级优化实践
1. 异步采样策略
在高QPS场景下,全量采集所有请求的追踪数据会带来巨大的性能开销和存储成本。京东采用了灵活的采样策略。
# 按比例概率采样 (10%)
sampler {
type: probabilistic
param: 0.1
}
# 限流速采样 (每秒最多100条Trace)
sampler {
type: rate_limiting
max_traces_per_second: 100
}
# 代码中动态决策:核心业务全量采集
if (isCoreBusiness()) {
span.forceSampling();
}
2. TraceId 与业务日志关联
单纯有链路视图还不够,还需要能快速定位到具体的错误日志。将TraceId注入到日志框架中是关键一步。
<!-- Logback 配置示例:在日志模式中追加 %X{traceId} -->
<appender name="CONSOLE" class="...">
<encoder>
<pattern>%d{HH:mm:ss} [%thread] %X{traceId} %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
在代码中,通过MDC(Mapped Diagnostic Context)传递TraceId:
MDC.put("traceId", TraceContext.getTraceId());
3. 慢查询与异常告警
建立基于追踪数据的告警规则,变被动排查为主动发现。
rules:
- name: slow_order
condition: duration > 1000 # 订单创建耗时超过1秒
severity: warning
- name: error_rate_high
condition: error_rate > 5% # 错误率超过5%
severity: critical
七、面试高频问题解析
Q1: TraceId 的生成有什么策略?
A: 常见有三种方案:
- UUID:简单,但生成的是无序字符串,不利于数据库索引。
- Snowflake 算法:生成有序递增的ID,性能高,携带时间戳信息,推荐使用。
- IP + 时间戳 + 随机数:兼顾唯一性和一定的可读性。
京东实践:采用Snowflake的变种算法,结构为 时间戳 + 机器ID + 序列号。
Q2: 全链路追踪的性能开销有多大?
A: 在良好优化下,性能开销可以控制在5%以内。优化手段包括:
- 异步上报:采集和上报分离,不阻塞主业务线程。
- 数据压缩:对Span数据压缩后再进行网络传输。
- 采样控制:如前所述,通过采样策略大幅减少数据量。
Q3: 跨多种语言的技术栈如何实现追踪?
A: 关键在于统一标准。
- 使用 OpenTelemetry:作为CNCF项目,它提供了统一的API、SDK和数据格式,是跨语言追踪的事实标准。
- 统一数据格式:如使用Zipkin V2或Jaeger的Thrift格式。
- 统一传输协议:通常使用gRPC或HTTP。
总结
全链路追踪不是微服务架构的可选装饰,而是保障系统可观测性、可维护性的核心基础设施。它就像是分布式系统的“黑匣子”,在出现问题时能帮你快速回溯现场。
回顾一下京东面试的核心考点:
- 原理理解:能否清晰阐述Trace、Span数据模型及其传递原理。
- 技术选型:了解SkyWalking、Jaeger、Zipkin等方案的优劣及适用场景。
- 落地实践:能否说出部署、接入、埋点的具体步骤。
- 性能优化:是否有成本意识,能设计合理的采样、异步等优化策略。
最后的心法:
- 平衡艺术:在数据完整性与系统性能、存储成本之间找到最佳平衡点。
- 联动思维:全链路追踪需与指标监控(Metrics)、日志(Logging)联动,构成完整的可观测性体系。
- 持续迭代:把它当作一个不断演进的基础设施来建设,而非一次性项目。
全链路追踪,是微服务开发者从“救火队员”迈向“系统架构师”必须掌握的核心技能。
在云栈社区的后端与架构板块,有更多关于分布式系统设计和微服务实践的深度讨论,欢迎交流。如果你正在准备面试,也可以到面试求职区看看其他人的经验和分享。
 发表于 2026-3-30 03:47:09
|
查看: 166|
回复: 0
发表于 2026-3-30 03:47:09
|
查看: 166|
回复: 0
