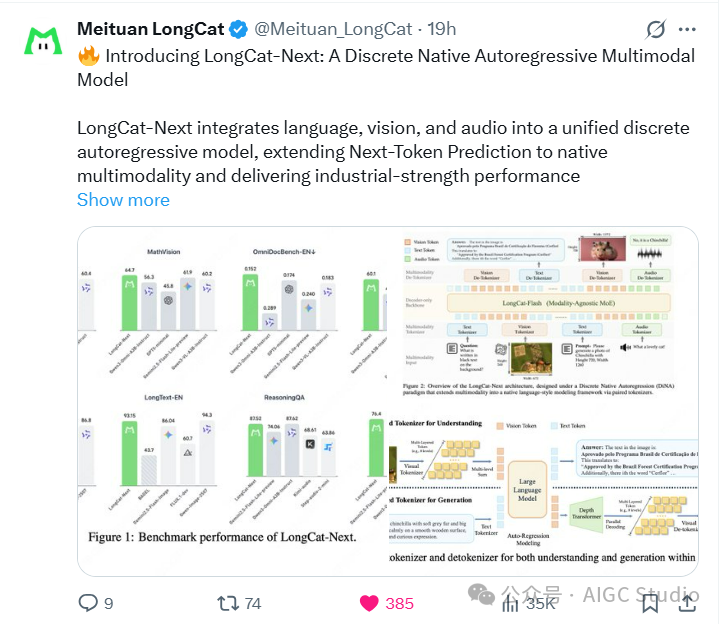
近日,美团开源了一款名为 LongCat-Next 的原生全模态模型,这一动作在人工智能社区引起了不小关注。该模型能够接受文本、语音、图像的输入,并生成相应的文本、语音、图像输出。这一创新性的设计,不仅简化了多模态建模的复杂性,还在图像理解与生成、纯文本处理、语音ASR与TTS等方面展现出了值得关注的性能。
效果展示
下面的图片直观对比了 LongCat-Next 在视觉理解与视觉生成两大核心任务上的能力。

视觉理解:模型能够处理复杂的图文信息,例如从报纸截图中提取完整文章内容、进行数学公式推导、解答字母逻辑谜题,乃至分析股票K线图的形态模式。
视觉生成:根据文本指令,模型可以生成多种风格的图像,包括风景、动物、儿童绘本封面、游戏界面概念图等,展示了其在创造性任务上的潜力。
相关链接
对于希望深入了解或动手实践的开发者,以下资源是关键入口:
将项目托管于 GitHub 等平台,便于社区协作与迭代,是当前优秀开源实战项目的标准做法。
介绍
LongCat-Next 是一个原生多模态模型。它的核心在于采用单一的自回归目标函数来处理文本、视觉和音频数据,并且在语言范式之外,模型的归纳偏置被控制得极小。作为一个规模达到 3B (A3B) 参数的工业级基础模型,它在视觉理解、创造性生成和表达方面表现突出,并在多个多模态基准测试中取得了优异成绩。
特别值得一提的是,它利用语义完备的离散表示,试图突破离散视觉建模在理解任务上长期存在的性能瓶颈,为视觉理解和生成提供了一个统一的解决方案。这一尝试表明,离散标记或许可以作为一种通用方案来表示多模态信号,并能被深度内化到单一的离散嵌入空间中。
LongCat-Next 模型的主要贡献可以概括为以下几点:
- 原生全模态设计:提出了一套全新的离散原生自回归范式,将所有模态(文本、视觉、音频)全部转化为统一的离散 Token,共享同一个自回归预测目标。
- 高效的模态转换器:引入了 dNaViT(离散原生视觉 Transformer)和音频 tokenizer,旨在实现图像和语音的高效压缩与高质量重建。
- 统一语义空间:通过分析表明,LongCat-Next 模型试图将视觉和音频信号视为以语言为中心的自回归范式的内在扩展,从而形成一个统一的语义表示空间。
- 优异的模型性能:在图像理解与生成、纯文本处理、语音 ASR 与 TTS 等多个维度上,LongCat-Next 模型都展示出了有竞争力的性能。
方法概述
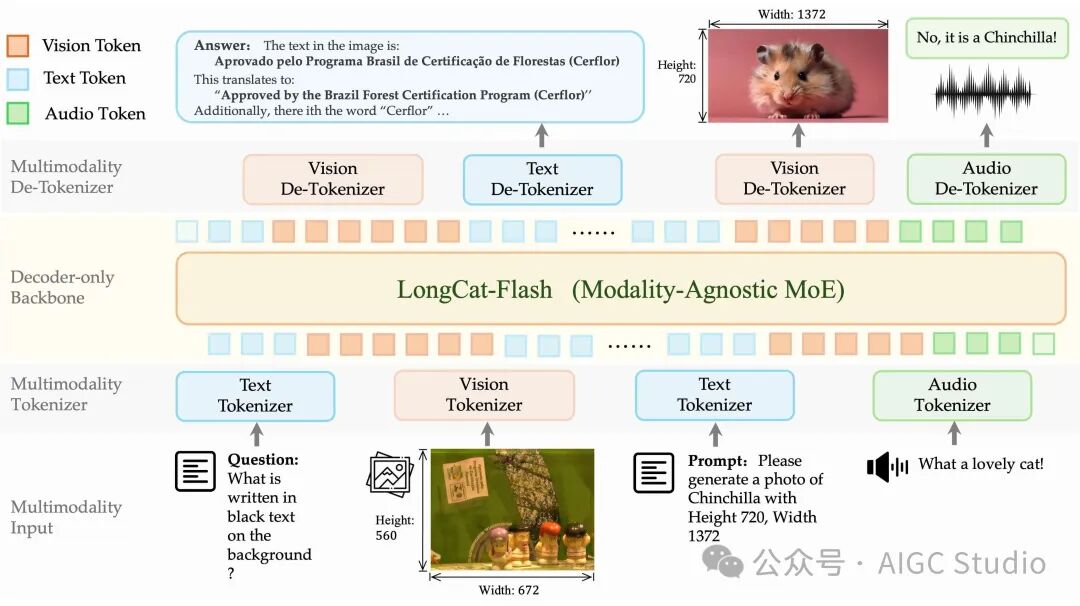
LongCat-Next 模型采用了一套全新的离散原生自回归范式,其目标是将所有模态数据转化为统一的离散 Token 序列。这一范式通过“分词器-反分词器”配对工作,并利用现有大型语言模型的训练基础设施进行训练,旨在简化多模态建模的流程。
模态转换器设计
- 视觉转换器(dNaViT):dNaViT 被设计为一个支持任意分辨率的、兼顾视觉理解和生成的统一 tokenizer。它通过 Semantic-and-Aligned Encoder (SAE) 结合 Residual Vector Quantization (RVQ) 来实现对任意分辨率图像的支持,并在力图保持语义完整的前提下实现高效压缩。
- 音频tokenizer:音频 tokenizer 负责将连续的语音信号转化为离散 token,同时需要保留语义和声学信息。它通过 Whisper 编码器进行音频特征提取,然后通过下采样和 RVQ 量化的方式生成离散 token。
原生多模态训练
LongCat-Next 模型的原生多模态训练涵盖了预对齐、预训练、中间训练和监督微调等多个阶段。在训练过程中,为了应对异构模块间跨阶段通信开销大的挑战,项目团队还提出了 V 型流水线并行技术。
实验评估
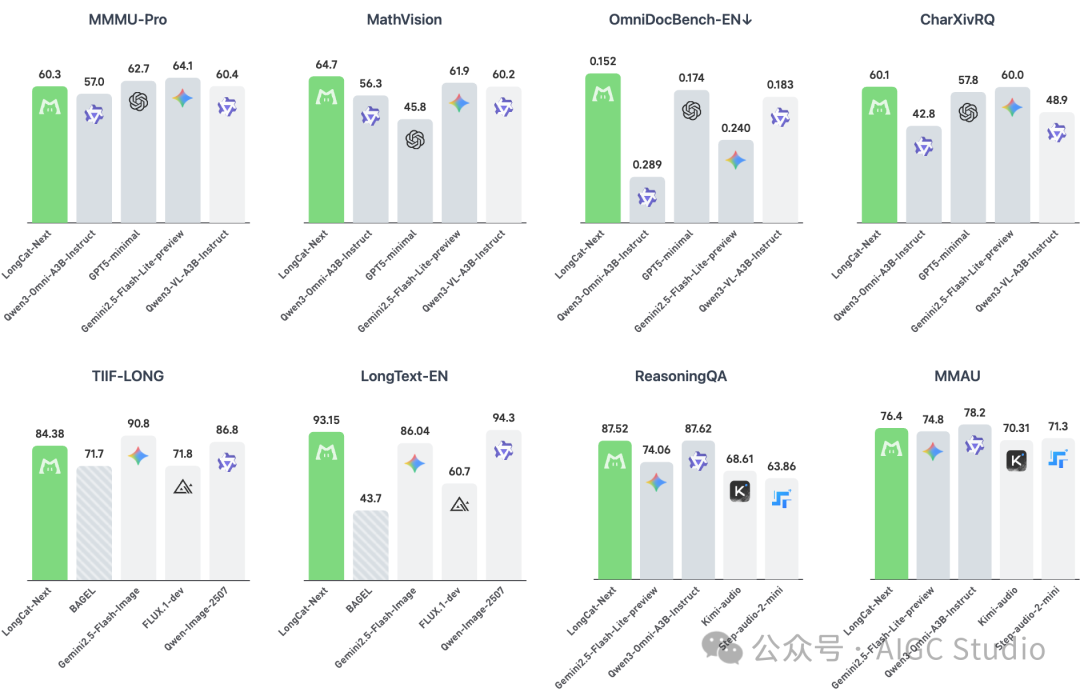
根据官方发布的基准测试结果,我们可以对 LongCat-Next 的能力有一个大致了解:
- 图像理解与生成:在 OCR 等需要细粒度内容识别的任务上,模型表现出色。在视觉理解任务中,模型能够进行精准定位,但对于涉及复杂空间变化和深层逻辑推理的任务,效果仍有提升空间。在图像生成方面,模型能够处理大字报生成等相对简单的指令,但对于更复杂、精细的生成要求,其输出质量有待进一步优化。
- 纯文本处理:在纯文本处理任务中,LongCat-Next 展现出了与同等级别模型相当的竞争力。
- 语音 ASR 与 TTS:在语音自动识别和文本转语音任务中,模型的准确率和生成语音的自然度都达到了可用水平。
总结与展望
LongCat-Next 的推出,为“用一个统一模型处理所有模态”这一颇具吸引力的研究方向提供了一个新的实践案例。其 3B 的参数量在追求效率的边端部署场景下具有显著优势。尽管在复杂推理和超高保真生成方面可能仍与顶尖专用模型存在差距,但其统一、简洁的架构思路值得关注。对于开发者和研究者而言,这是一个很好的、可以深入剖析其技术细节并进行二次创新的开源项目。我们可以在 云栈社区 等技术论坛上看到更多关于此类模型的实践讨论与经验分享。 |  发表于 2026-3-31 22:36:04
|
查看: 170|
回复: 0
发表于 2026-3-31 22:36:04
|
查看: 170|
回复: 0
