随着大模型参数规模呈指数级增长,单一虚拟机或物理机的资源限制已无法满足其需求。为了应对这一挑战,业界引入了许多创新性的部署框架,例如 PD (Prefill-Decode) 分离部署以及大小模型混合部署框架。这些方法彻底改变了推理部署的方式:不再是一个 Pod 处理整个推理任务,现在往往由多个 Pod 协同完成单次推理任务。这种多 Pod 协同已经成为大模型推理部署的关键趋势。

在实践中,推理模型可能仍然运行在单个 Pod 内(如传统的单节点场景)、一组相同的 Pod 中(针对更大的模型),或者跨越具有专门角色的多个 Pod(如 PD 分离部署)。这种灵活的部署方式不仅提高了资源利用率,也实现了更高效的大模型推理。
ModelServing 是 Kthena 定义的一个 API,旨在管理和编排推理模型工作负载的生命周期。得益于其三层架构,它可以非常方便地表示和管理多种部署模式。
三层架构
为了解决 Kubernetes 传统的两层架构(例如 Deployment 和 StatefulSet)在管理多样化推理工作负载部署场景时的局限性,ModelServing 采用了 ModelServing → ServingGroup → Role 的三层架构。架构图如下所示:
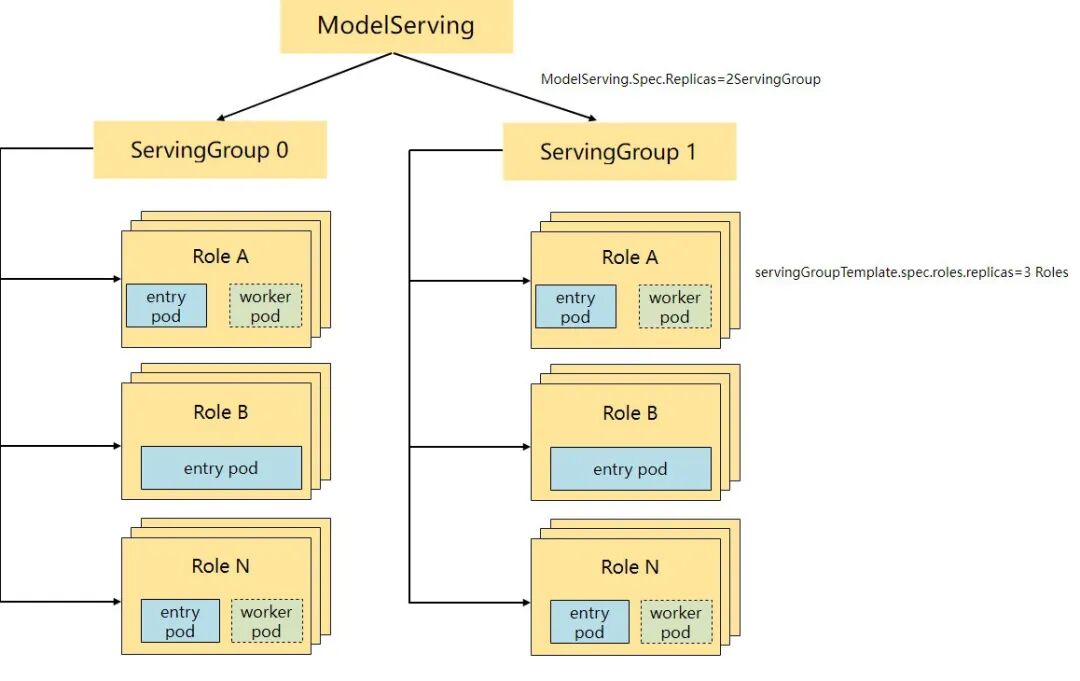
- ModelServing:核心组件,负责管理推理模型工作负载的生命周期。它提供了一个统一的接口,用于部署和管理推理模型以及查询它们的状态。
- ServingGroups:
ServingGroup 是一个 Role(角色)的集合。每个 Group 都可以完成完整的推理任务,对于 PD 分离部署来说,它同时包含 Prefill 和 Decode 角色。
- Roles:一个
ServingGroup 内的每个 Role 由一组 Pod 组成,这些 Pod 是负责执行推理任务的实际工作负载。可以为每个角色分配不同的任务。例如,在 PD 分离场景中,您可以配置一个 prefill role(预填充角色)和一个 decode role(解码角色)。
关于 ModelServing 的定义,请参考 modelServing CRD 参考文档。
通过将推理工作负载整合为 Group 形式,该架构实现了与 Volcano 的 Gang 调度及网络拓扑感知调度的无缝对接。与此同时,针对滚动更新和弹性扩缩容等核心的云原生工作负载管理需求,我们也进行了专门的扩展处理。
Gang 调度
Gang 调度策略是 Volcano-Scheduler 的核心调度算法之一。它满足了调度过程中“同生共死 (All or nothing)”的调度需求,避免了由于为满足任务需求的部分 Pod 部署而导致的资源浪费。Gang 调度算法会观察已调度的 Pod 数量是否满足最小运行数量。当满足 Job 的最小运行数量时,将对 Job 下的所有 Pod 执行调度动作;否则,所有的Pod都不会执行调度。
在 Kthena 中,基于 ModelServing 创建 PodGroups,通过 PodGroups 利用 Volcano 的 Gang 调度能力。subGroupSize 字段指定了每个 Role 中需要进行 Gang 调度的 Pod 数量。
实例级 Gang 调度
创建过程
Kthena将为整个 ServingGroup 实例创建一个单一的 PodGroup。该配置为自动生成,无需手动创建。
PodGroup 配置
以下为 modelServing 示例:
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: ModelServing
metadata:
name: sample
namespace: default
spec:
schedulerName: volcano
replicas: 1 # servingGroup replicas
template:
restartGracePeriodSeconds: 60
gangPolicy:
minRoleReplicas:
prefill: 2
decode: 2
roles:
- name: prefill
replicas: 4
# ... additional role configuration
- name: decode
replicas: 4
# ... additional role configuration
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: {modelserving-name}-{servinggroup-index}
namespace: {modelserving-namespace}
labels:
modelinfer.volcano.sh/name: {modelserving-name}-{servinggroup-index}
annotations:
scheduling.k8s.io/group-name: {modelserving-name}
spec:
minMember: 8
subGroupPolicy:
- labelSelector:
matchLabels:
modelserving.volcano.sh/name: sample
modelserving.volcano.sh/role: prefill
matchLabelKeys:
- modelserving.volcano.sh/role-id
minSubGroups: 2
name: prefill
subGroupSize: 2
- labelSelector:
matchLabels:
modelserving.volcano.sh/name: sample
modelserving.volcano.sh/role: decode
matchLabelKeys:
- modelserving.volcano.sh/role-id
minSubGroups: 2
name: decode
subGroupSize: 2
## ... another configuration ...
pod数量计算
- 如果未配置 MinRoleReplicas,minMember的值计算如下:
minMember = replicas × Σ(role.replicas × (1 + role.workerReplicas))
- 如果配置了 MinRoleReplicas,minMember的值计算变为:
minMember = replicas × Σ(minRoleReplicas[roleName] × (1 + role.workerReplicas))
其中:
replicas: ServingGroup 实例的数量role.replicas: 每个 ServingGroup 内角色实例的数量minRoleReplicas[roleName]: 配置的Role需要的最少Replicas1 + role.workerReplicas: 每个角色实例的 EntryPod + WorkerPods 数量
SubGroupSize计算
- 如果未配置
MinRoleReplicas,subGroupSize 的值生成逻辑如下:
- 针对
Spec.Template.Roles 中指定的每个 role
- 在podGroup中创建对应的subGroupPolicy
- 每个Role对应的SubGroupSize为
(1 + role.workerReplicas)
- 如果配置了
MinRoleReplicas,subGroupSize 的值生成逻辑变为:
- 针对
MinRoleReplicas map中指定的每个 role
- 在
Spec.Template.Roles当中找到对应的role
- 在PodGroup中创建对应的subGroupPolicy
- 每个minRoleReplicas中的role对应的SubGroupSize为
(1 + role.workerReplicas)
滚动更新
滚动更新是云服务实现零停机的一项关键运维策略。在 LLM 推理服务场景中,支持滚动更新对于降低服务不可用风险、保障业务连续性至关重要。目前,ModelServing 支持在 ServingGroup 级别进行滚动升级,允许用户配置 Partitions 控制滚动过程。
Partition:表示 ModelServing 更新时划分的分界序号。在滚动更新期间,序号大于或等于 Partition 的副本将被更新。序号小于 Partition 的副本将不会被更新。
以下为一个配置了 rollout 策略的 ModelServing示例:
spec:
rolloutStrategy:
type: ServingGroupRollingUpdate
rollingUpdateConfiguration:
partition: 0
接下来,我们将展示具有四个副本的 ModelServing 的滚动更新过程。这里模拟了三种副本状态:
- ✅ 副本已更新
- ❎ 副本未更新
- ⏳ 副本正在进行滚动更新
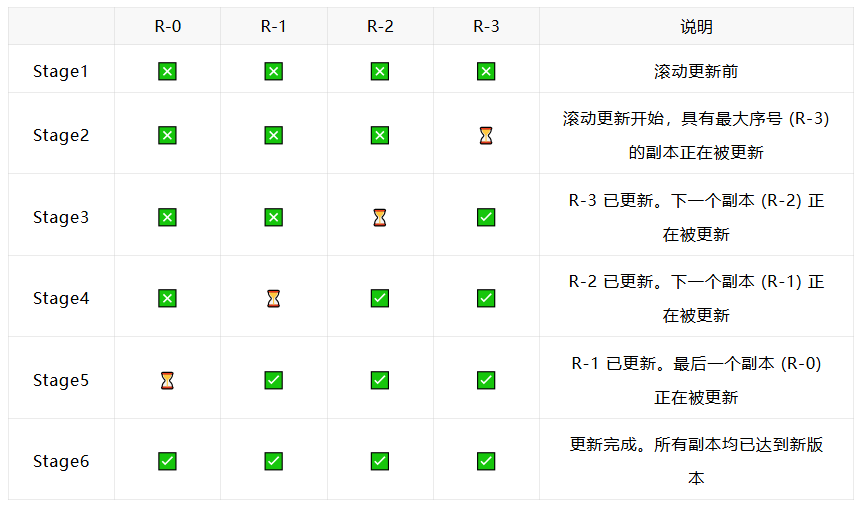
在滚动升级期间,控制器会删除并重建需要更新的副本中序列号最大的副本。直到新副本正常运行后,下一副本才会被更新。现阶段ModelServing已经支持设置maxUnavailable,能够设置在滚动更新的时候有多少新版本的servingGroup可以为不可用状态,控制滚动升级的速度。
扩缩容
在云原生基础设施项目中,弹性扩缩容在优化资源成本、提升系统可用性、增强响应能力以及简化运维管理等方面,发挥着至关重要的作用。在 ModelServing 中,我们支持 ServingGroup 和 Role 的两级扩缩容。ServingGroup 级别的扩缩容与滚动更新的处理过程类似,更新均在副本集中以逆序进行。Role 级别的扩缩容可以直接对每个角色的进行副本数细粒度的调整。在 PD 分离部署场景中,可以弹性调整 prefill 或 decode 副本,根据它们各自的工作负载优化 P/D 比例。例如:
- 长提示词,短输出场景:弹性增加 prefill 副本,以处理计算密集的提示词处理,同时保持较少的 decode 副本。
- 短提示词,长输出场景:弹性增加 decode 副本,以处理序列 token 的生成,同时保持较少的 prefill 副本。
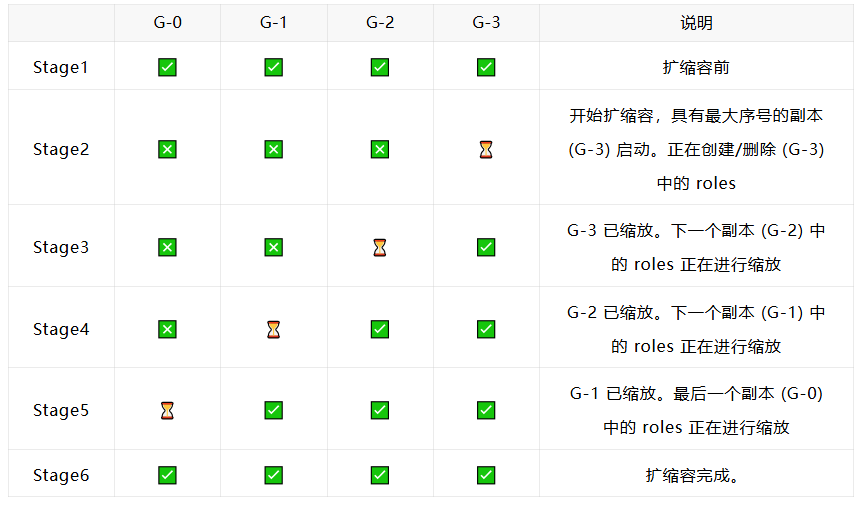
这种灵活的扩缩容能力确保了能够基于实际工作负载模式进行最佳的资源分配。通过修改 role.Replicas 触发角色粒度的弹性扩缩容,整个 ServingGroup 的状态将变为 scaling,随后执行 Pod 的创建或删除流程。当 Pod 副本数满足预期后,ServingGroup 的状态将基于所有 Pod 的状态更新。并且由于 Role 中的 Pod 带有顺序和标签,所有扩缩容操作都是从最后一个 Pod 开始处理的。
Role 扩缩容流程
重启策略
在 ModelServing 中,强调了将 Pod 分组的概念。因此,当组内的一个 Pod 发生错误时,通常会一起重启整个组。然而,在生产环境中,重启一整组 Pod 可能会消耗大量的资源和时间。为解决这个问题,ModelServing 也提供了支持单个 Role 重启的策略。
- ServingGroupRecreate:当组内 Pod 发生错误时,将重启整个servingGroup。
- RoleRecreate:当组内 Pod 发生错误时,servingGroup的状态将更新为 progressing 并且仅重启受影响的 Role。如果 serviceGroup 停留在 progressing 状态超过一定时间,则将删除并重新创建整个 ServingGroup。
展望
作为 Kthena 的核心组件,ModelServing 如今已能游刃有余地应对大模型工作负载的管理与调度,彰显了 Kthena 架构的优越性与前瞻性。尽管目前在 PD 分离场景的精细化操作(如实例平滑升级)上尚处于完善阶段,但在未来的发展蓝图中,我们势必会为 PD 分离等复杂部署模式注入更多专属的强大能力。
如果你对构建或使用此类高级的 人工智能 基础设施感兴趣,欢迎访问 Kthena 在 GitHub 的项目主页,参与到开源社区的讨论与建设中来。
 发表于 2026-4-1 04:13:02
|
查看: 205|
回复: 0
发表于 2026-4-1 04:13:02
|
查看: 205|
回复: 0
