在 32 位系统中,总的虚拟地址空间大小是 2^32 = 4GB。这个空间会被划分为内核空间和用户空间。
在 Windows 系统下,默认会将高地址的 2GB 空间分配给内核(当然也可以配置为分配 1GB)。而在 Linux 系统下,默认则将高地址的 1GB 空间分配给内核。分配给操作系统内核使用的这部分区域被称为内核空间,而剩下的空间则供用户程序使用,被称为用户空间。
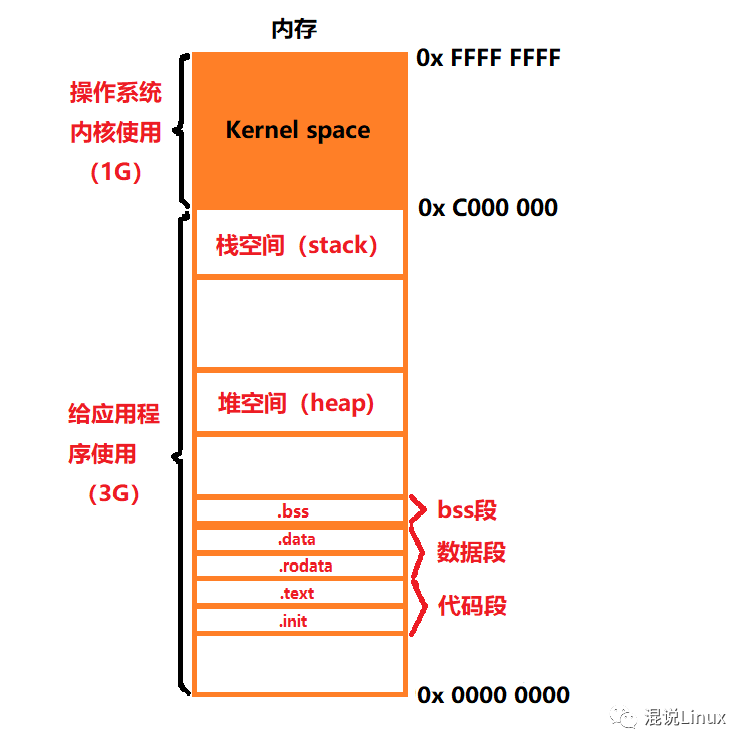
从上图可以看到,一个典型的 Linux 进程地址空间由多个不同的段(Segment)组成,从上到下依次是:
-
栈空间 (stack)
进程地址空间最顶部的段是栈。我们在代码中调用函数、定义局部变量(不包括用 static 修饰的变量)或创建类的实例时,都会使用栈空间。当一个函数执行完毕(即程序执行超出了该函数的作用范围时),操作系统会自动将该函数在栈中存放的数据“出栈”以释放内存,这个过程通常发生在函数 return 时。
然而,如果不断向栈中压入数据,直至超过其最大容量限制,就会发生栈溢出 (stack overflow)。栈溢出通常会导致程序崩溃并报出段错误 (Segmentation Fault)。
-
堆空间 (heap)
堆用于存储那些生命周期与特定函数调用无关的数据。我们通常使用 malloc(), calloc(), realloc(), new 等接口在堆上申请内存。
堆空间的一个关键特点是:申请空间后,如果不主动释放(使用 free(), delete 等),这块内存会一直存在。因此,动态申请的内存需要程序员自己负责分配和释放,这正是手动内存管理的核心。
-
bss 段
bss (Block Started by Symbol) 段,也叫未初始化数据段,是一块用于存放未初始化的全局变量或静态(全局/局部)变量的内存区域。
例如,如果你写下 static int a; 或者 int a;(作为全局变量),那么变量 a 就会被存放在 bss 段中。
-
数据段
数据段 (data segment) 和 bss 段都是用来存放全局变量或静态变量的内存区域。它们的核心区别在于:数据段存放的是已经显式初始化的全局/静态变量。
例如,如果你写下 static int a = 2; 或者 int a = 2;(作为全局变量),那么变量 a 就会存放在数据段中,并且初始值为 2。
另外,还有一个 rodata(只读数据)段,它是数据段的一部分,专门用来存放常量。
-
代码段
代码段 (code segment / text segment) 主要分为两部分:
.text: 用于存放程序的执行代码(机器指令)。.init: 用于存放系统在程序启动时用来执行初始化工作的一段代码。
一个可执行程序在内存中的映像,本质上就是由 bss 段、数据段和代码段这三个核心部分组成的。
理解了这些内存区域的区别,我们就能分析一些有趣的编程现象。来看下面两段 C 代码:
// 代码 1:
int arry[100000];
int main()
{
// ......
}
// 代码 2:
int arry[100000] = {1, 2, 3, 4, 5, 6};
int main()
{
// ......
}
使用 gcc 分别编译这两段代码后,生成的可执行文件大小对比如下:

可以清晰地看到,代码 1 编译出的可执行文件(9 KB)远比代码 2 的(399 KB)要小。这是为什么呢?
根本原因在于,代码 1 中定义的全局数组 arry 未被初始化,因此它位于 bss 段。而 bss 段有一个重要特性:它本身并不占用可执行文件的物理存储空间。bss 段中的数据内容(全零)是由操作系统在程序加载时统一初始化的。
相反,代码 2 中的 arry 被显式初始化了,因此它位于数据段。数据段的内容(包括初始值)必须原原本本地保存在可执行文件中,以便程序加载时能正确初始化变量。因此,一个包含 10 万个 int 类型初始值的数据段会显著增加可执行文件的大小。
这正是为什么我们常说:“定义未初始化的全局变量不会增加程序大小”。不过要注意,这只是指磁盘上的可执行文件大小。程序运行时,无论 bss 段还是 data 段,都会占用相应的内存(RAM)空间。掌握这些底层知识,对于理解程序行为、进行性能优化和调试都至关重要。如果想深入讨论更多技术细节,欢迎来 云栈社区 交流。 |  发表于 2026-4-2 02:55:21
|
查看: 208|
回复: 0
发表于 2026-4-2 02:55:21
|
查看: 208|
回复: 0
