内联函数是C语言从C++中引入的特性,合理地使用它可以有效提升程序的执行效率。这听起来不错,但具体是怎么做到的呢?我们这篇文章就来深入探讨一下。
在正式讲解内联函数之前,我们有必要先理解普通函数调用的机制,特别是其中涉及的开销问题。
一、理解函数调用的开销
当一个函数执行时,如果需要调用另一个函数,系统需要进行一系列“保护现场”的操作。想象一下这个场景:函数A正在执行,它对一些数据进行了处理,并将中间结果暂存在某个寄存器(比如R0)中。接着它需要调用函数B,而函数B很可能也会使用R0寄存器(例如用于保存自己的返回值)。如果不做任何处理,函数A保存在R0中的值就会被函数B覆盖,这显然会导致错误。
为了解决这个问题,现代计算机系统会在执行函数B之前,先将R0等关键寄存器的值“保存现场”,压入堆栈中。等函数B执行完毕,再“恢复现场”,将堆栈中的值重新加载回R0寄存器,这样函数A才能继续正确执行。
然而,这些保存与恢复现场的操作是需要时间的,通常相当于执行一两条额外指令的耗时。这,就是函数调用本身带来的性能开销。
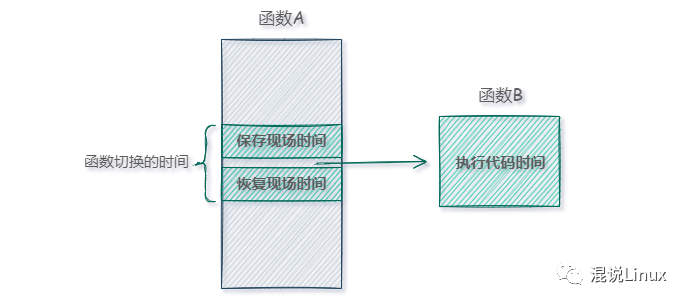
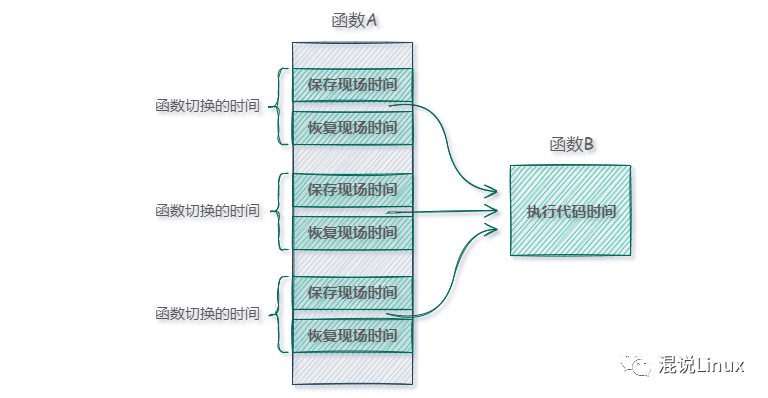
现在假设函数B的代码逻辑非常简单,只有一两行。从上图可以看出,真正执行我们所需功能(即“执行代码时间”)的占比可能并不高,而“函数切换的时间”(保存/恢复现场)却成了无法忽视的额外负担。如果函数A内部多次调用这样的函数B,累积起来的开销就更可观了。
二、内联函数如何工作
当一个函数体很小,却又被频繁调用时,调用它的切换开销可能比它自身执行代码的时间还长,这无疑是不划算的。这时,我们就可以考虑使用内联函数。
在函数声明前加上 inline 关键字,就是告诉编译器一个建议:尝试将这个函数的代码直接“内联”展开到每一个调用它的地方。这有点像宏替换,但在C/C++的语境下,它更安全、更可控。
具体来说,编译器在编译时,会将内联函数的实现复制一份“副本”,嵌入到每个调用点。这样一来,函数调用变成了顺序执行的代码,完全省去了保护现场和恢复现场的开销。
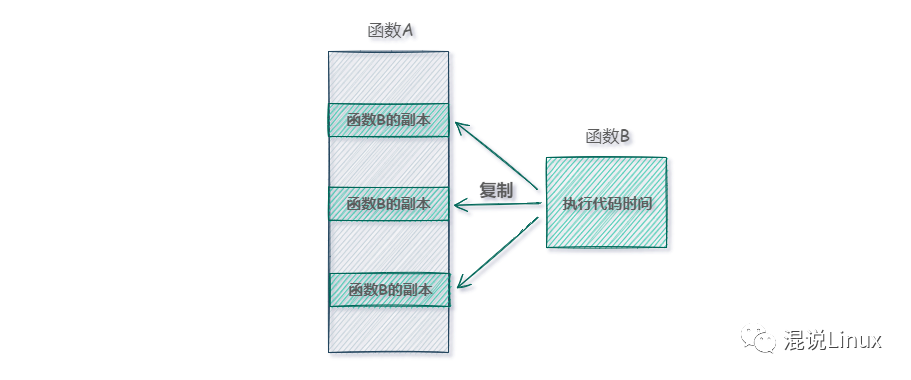
当然,并非所有函数都适合内联。通常内联函数应满足以下条件:
- 函数体积小,代码通常在5行以内。
- 被频繁调用。
- 函数内部没有复杂的控制结构,如循环、大量的
switch分支或递归。
- 函数内不包含静态(static)变量。
来看一个简单的例子:
#include <stdio.h>
// 将函数 max_value 声明为 inline
inline int max_value(int x, int y)
{
return (x>y) ? x:y;
}
int main()
{
int a = 1, b = 2;
int m;
m = max_value(a, b);
return 0;
}
经过编译器内联处理后,main函数中的代码在逻辑上会变成这样:
int main()
{
int a = 1, b = 2;
int m;
m = (1>2) ? 1:2; // 函数调用被替换为函数体
return 0;
}
内联函数在调用点被直接展开了。值得注意的是,在C++中,定义在类内部的成员函数默认就是内联的。
另外需要强调一点:inline关键字只是给编译器的一个建议。如果函数过于复杂,编译器会忽略这个建议,将其作为普通函数处理。
三、为什么用内联函数而非宏?
前面提到内联函数类似于宏函数,那么为什么不直接用宏#define呢?内联函数的存在,恰恰是为了弥补宏的诸多缺陷:
- 参数类型检查:宏在预处理阶段进行简单的文本替换,不进行任何类型检查。而内联函数本质仍是函数,编译器会对其参数进行严格的类型检查,安全性更高。
- 易于调试:宏展开后的代码难以调试,错误信息可能指向被替换后的复杂代码。内联函数支持断点、单步调试等所有常规调试手段。
- 避免副作用:对于宏
#define SQUARE(x) (x)*(x),调用 SQUARE(a++) 会导致a被递增两次,这是经典的宏副作用问题。内联函数则完全避免了这种不确定性。
- 封装性:内联函数可以封装为一个清晰的接口,而宏只是代码片段。
四、总结与权衡
引入内联函数的核心目的,是解决频繁调用的小函数所带来的额外时间开销问题。它是一种典型的“以空间换时间”的策略:通过增加最终可执行文件的代码体积(因为同一份函数体会被复制多份),来换取运行时函数调用开销的消除,从而提高执行效率。
但这并不意味着滥用内联就是好事。过度使用内联会导致编译后代码膨胀,可能降低CPU指令缓存的命中率,反而影响性能,同时也会增加编译时间。因此,关键就在于“适当”二字——识别出那些体积小、调用频繁的热点函数,谨慎地使用 inline 关键字进行优化。
希望这篇关于C语言内联函数的解析,能帮助你更好地理解和使用这一特性,写出更高效的代码。对这类底层优化技巧感兴趣的朋友,也欢迎在云栈社区的C/C++板块与大家深入交流。
 发表于 2026-4-2 03:00:50
|
查看: 207|
回复: 0
发表于 2026-4-2 03:00:50
|
查看: 207|
回复: 0
