微软近期开源了VibeVoice项目,但这不仅仅意味着又增加了一个新的语音大模型。更值得关注的是,它试图将长音频识别、长文本语音合成以及实时流式语音这三条不同的技术路线,整合到一个统一的架构家族中。你所看到的不仅是一个演示,更是一套逐渐具备系统层能力的Voice AI拼图。
项目简介
VibeVoice开源了什么?
目前,VibeVoice公开的核心技术路线有三条:
- VibeVoice-ASR:支持单次处理长达60分钟的音频进行识别,输出结果直接包含说话人身份、时间戳和文本内容。
- VibeVoice-TTS:最初主打为最长约90分钟、最多包含4个说话人的长文本生成语音。
- VibeVoice-Realtime-0.5B:一个更轻量级的实时语音合成版本,根据文档,其生成首个可听语音的延迟大约在200ms。
关键洞察:聚焦“长上下文语音”
VibeVoice的技术文档反复强调了一个核心设计:连续语音分词器(Tokenizer)以及7.5 Hz的超低帧率。这一点至关重要,因为无论是长音频、长对话还是长文本配音,最终都会面临同一个挑战:序列长度增加会导致Token数量和计算成本急剧膨胀。
因此,这个项目的真正价值不在于某个单项性能指标的突破,而在于它尝试用统一的“长上下文”设计思路,将ASR、长文本TTS和实时TTS串联成一套连贯的技术体系。
为什么建议开发者先关注ASR?
如果你是一名开发者,我建议优先考察VibeVoice-ASR。因为它已经更接近“可以集成到实际系统”的状态。仓库中关于这条线的描述非常明确:
这意味着它旨在解决的,不仅仅是“将语音转成文字”的基础问题,还试图将长音频场景中最棘手的后处理工作(如说话人分割、时间对齐)一并纳入统一的推理输出中。
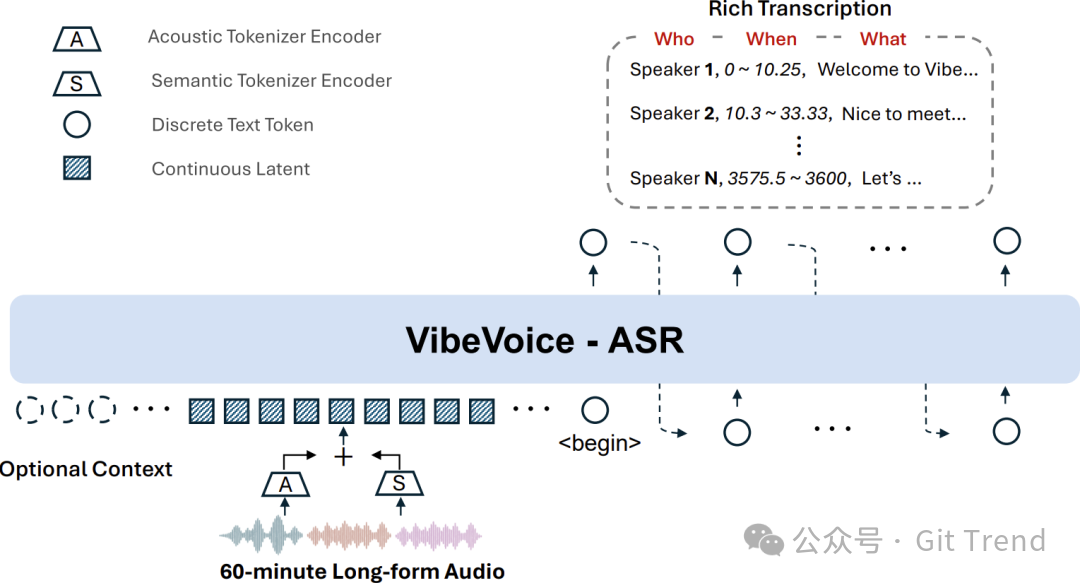
ASR文档中的架构图,重点在于阐释其如何将长音频识别、说话人区分和时间对齐尽可能地统一在一次推理过程中。
向“系统级组件”演进
项目仓库专门提供了 docs/vibevoice-vllm-asr.md 文档和 vllm_plugin/ 目录,将 OpenAI兼容接口、Docker部署、多GPU扩展 这些工程化层面的能力也铺设出来。
更具体地,在 start_server.py 脚本中,当设置 dp > 1 时,它会直接启动多个vLLM工作进程,并通过nginx进行负载均衡。这个细节表明,项目团队关心的已经不再是“模型能否运行”,而是“当海量长音频请求涌入时,服务如何有效承载”。
一个现实的信号:能力增强与开放边界的权衡
README的更新时间线里有一条关键记录:开发团队在2025年9月说明,由于发现了一些不符合项目初衷的使用方式,已将VibeVoice-TTS的完整代码从主仓库中移除。
这件事深刻地反映了当前语音AI领域的现状:高质量的TTS技术已不再是“能否实现”的问题,而是“开源到何种程度、相关风险如何控制”的平衡问题。
最终判断
VibeVoice最值得关注的地方,并非其某个单项指标刷新了纪录,而是微软正在将语音技术从“构建一个孤立的模型”,推进到“围绕长上下文核心,打造一套能识别、能生成、且易于部署的系统级拼图”。
如果你对这类整合了前沿研究与工程实践的人工智能项目感兴趣,欢迎来到云栈社区与更多开发者交流探讨。 |  发表于 2026-4-2 06:21:45
|
查看: 133|
回复: 0
发表于 2026-4-2 06:21:45
|
查看: 133|
回复: 0
