GIC 硬件原理
GIC,Generic Interrupt Controller。是 ARM 公司提供的一个通用的中断控制器。主要作用为:接受硬件中断信号,并经过一定处理后,分发给对应的 CPU 进行处理。
当前 GIC 有四个版本,GIC v1~v4,本文主要介绍 GIC v3 控制器。
GIC v3中断类别
GICv3定义了以下中断类型:
- SGI (Software Generated Interrupt):软件触发的中断。软件可以通过写 GICD_SGIR 寄存器来触发一个中断事件,一般用于核间通信,内核中的 IPI:inter-processor interrupts 就是基于 SGI。
- PPI (Private Peripheral Interrupt):私有外设中断。这是每个核心私有的中断。PPI会送达到指定的 CPU 上,应用场景有 CPU 本地时钟。
- SPI (Shared Peripheral Interrupt):公用的外部设备中断,也定义为共享中断。中断产生后,可以分发到某一个 CPU 上。比如按键触发一个中断,手机触摸屏触发的中断。
- LPI (Locality-specific Peripheral Interrupt):LPI 是 GICv3 中的新特性,它们在很多方面与其他类型的中断不同。LPI 始终是基于消息的中断,它们的配置保存在表中而不是寄存器。比如 PCIe 的 MSI/MSI-x 中断。
| 中断类型 |
硬件中断号 |
| SGI |
0-15 |
| PPI |
16-31 |
| SPI |
32-1019 |
| reserved |
...... |
| LPI |
8192-MAX |
GIC v3 组成
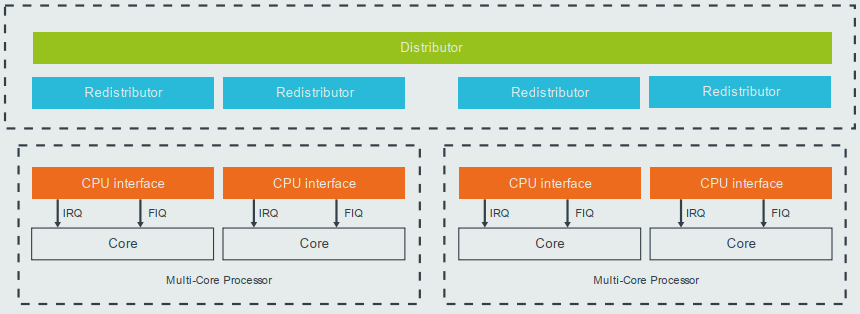
GICv3 控制器由以下三部分组成:
- Distributor:SPI 中断的管理,将中断发送给 Redistributor
- 打开或关闭每个中断。Distributor对中断的控制分成两个级别。一个是全局中断的控制(GIC_DIST_CTRL)。一旦关闭了全局的中断,那么任何的中断源产生的中断事件都不会被传递到 CPU interface。另外一个级别是对针对各个中断源进行控制(GIC_DIST_ENABLE_CLEAR),关闭某一个中断源会导致该中断事件不会分发到 CPU interface,但不影响其他中断源产生中断事件的分发。
- 控制将当前优先级最高的中断事件分发到一个或者一组 CPU interface。当一个中断事件分发到多个 CPU interface 的时候,GIC 的内部逻辑应该保证只 assert 一个CPU。
- 优先级控制。
- interrupt属性设定。设置每个外设中断的触发方式:电平触发、边缘触发;
- interrupt group的设定。设置每个中断的 Group,其中 Group0 用于安全中断,支持 FIQ 和 IRQ,Group1 用于非安全中断,只支持 IRQ;
- Redistributor:SGI,PPI,LPI 中断的管理,将中断发送给 CPU interface
- 启用和禁用 SGI 和 PPI。
- 设置 SGI 和 PPI 的优先级。
- 将每个 PPI 设置为电平触发或边缘触发。
- 将每个 SGI 和 PPI 分配给中断组。
- 控制 SGI 和 PPI 的状态。
- 内存中数据结构的基址控制,支持 LPI 的相关中断属性和挂起状态。
- 电源管理支持。
- CPU interface:传输中断给 Core
- 打开或关闭 CPU interface 向连接的 CPU assert 中断事件。对于 ARM,CPU interface 和 CPU 之间的中断信号线是 nIRQCPU 和 nFIQCPU。如果关闭了中断,即便是 Distributor 分发了一个中断事件到 CPU interface,也不会 assert 指定的 nIRQ 或者 nFIQ 通知 Core。
- 中断的确认。Core 会向 CPU interface 应答中断(应答当前优先级最高的那个中断),中断一旦被应答,Distributor 就会把该中断的状态从 pending 修改成 active 或者 pending and active(这是和该中断源的信号有关,例如如果是电平中断并且保持了该 asserted 电平,那么就是 pending and active)。ack 了中断之后,CPU interface 就会 deassert nIRQCPU 和 nFIQCPU 信号线。
- 中断处理完毕的通知。当 interrupt handler 处理完了一个中断的时候,会向写 CPU interface 的寄存器通知 GIC CPU 已经处理完该中断。做这个动作一方面是通知 Distributor 将中断状态修改为 deactive,另外一方面,CPU interface 会 priority drop,从而允许其他的 pending 的中断向 CPU 提交。
- 为 CPU 设置中断优先级掩码。通过 priority mask,可以 mask 掉一些优先级比较低的中断,这些中断不会通知到 CPU。
- 设置 CPU 的中断抢占(preemption)策略。
- 在多个中断事件同时到来的时候,选择一个优先级最高的通知 CPU。
GICv3 控制器内部模块和各中断类型的关系如下图所示:
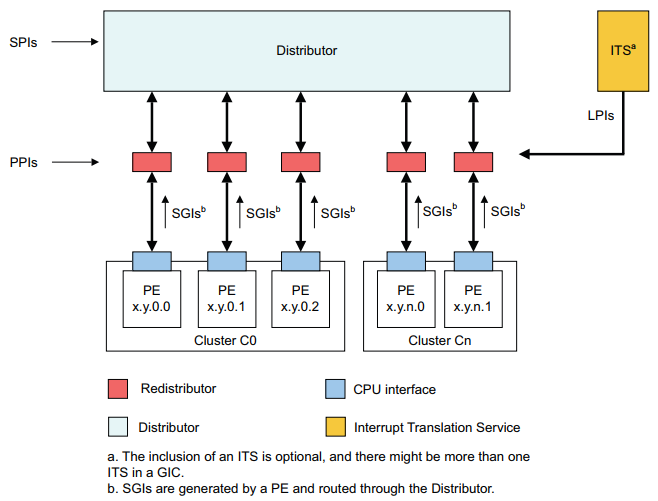
中断路由
GICv3 使用 hierarchy 来标识一个具体的 core, 如下图是一个四层的结构(aarch64):
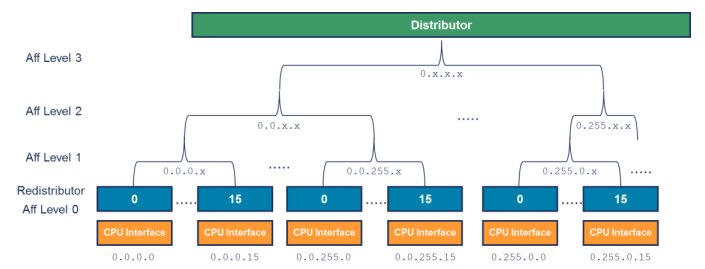
用 <affinity level 3>.<affinity level 2>.<affinity level 1>.<affinity level 0> 的形式组成一个 PE 的路由。每一个 core 的 affnity 值可以通过 MPDIR_EL1 寄存器获取, 每一个 affinity 占用 8bit。配置对应 core 的 MPIDR 值,可以将中断路由到该 core 上。
各个 affinity 的定义是根据 SOC 自己的定义,比如:
<group of groups>. <group of processors>.<processor>.<core>
<group of processors>.<processor>.<core>.<thread>
中断亲和性的设置的通用函数为 irq_set_affinity,后面会做详细介绍。
中断状态机
中断处理的状态机如下图:
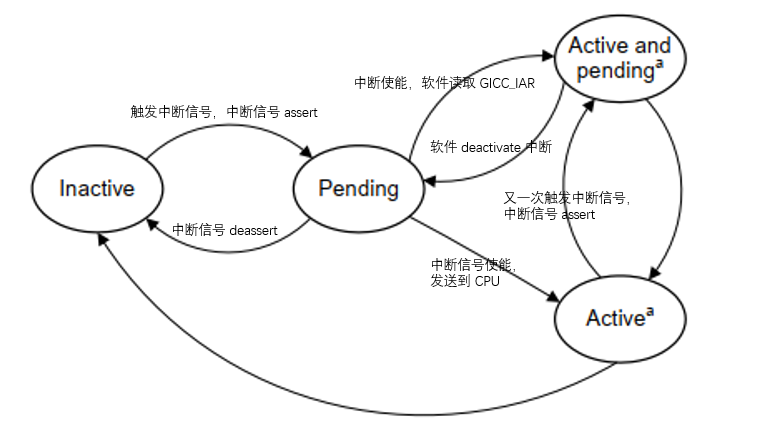
- Inactive:无中断状态,即没有 Pending 也没有 Active。
- Pending:硬件或软件触发了中断,该中断事件已经通过硬件信号通知到 GIC,等待 GIC 分配的那个 CPU 进行处理,在电平触发模式下,产生中断的同时保持 Pending 状态。
- Active:CPU 已经应答(acknowledge)了该中断请求,并且正在处理中。
- Active and pending:当一个中断源处于 Active 状态的时候,同一中断源又触发了中断,进入 pending 状态。
中断处理流程
- 外设发起中断,发送给 Distributor
- Distributor 将该中断,分发给合适的 Redistributor
- Redistributor 将中断信息,发送给 CPU interface
- CPU interface 产生合适的中断异常给处理器
- 处理器接收该异常,并且软件处理该中断
GIC 驱动
这里主要分析 linux kernel 中 GIC v3 中断控制器的代码(drivers/irqchip/irq-gic-v3.c)。
设备树
先来看下一个中断控制器的设备树信息:
gic: interrupt-controller@<span>51</span>a00000 {
compatible = <span>"arm,gic-v3"</span>;
reg = <<span>0x0</span> <span>0x51a00000</span> <span>0</span> <span>0x10000</span>>, <span>/* GIC Dist */</span>
<<span>0x0</span> <span>0x51b00000</span> <span>0</span> <span>0xC0000</span>>, <span>/* GICR */</span>
<<span>0x0</span> <span>0x52000000</span> <span>0</span> <span>0x2000</span>>, <span>/* GICC */</span>
<<span>0x0</span> <span>0x52010000</span> <span>0</span> <span>0x1000</span>>, <span>/* GICH */</span>
<<span>0x0</span> <span>0x52020000</span> <span>0</span> <span>0x20000</span>>; <span>/* GICV */</span>
<span>#interrupt-cells = <span><3>;</span></span>
interrupt-controller;
interrupts = <GIC_PPI <span>9</span>
(GIC_CPU_MASK_SIMPLE(<span>6</span>) | IRQ_TYPE_LEVEL_HIGH)>;
interrupt-parent = <&gic>;
};
- compatible:用于匹配 GICv3 驱动
- reg:GIC 的物理基地址,分别对应 GICD, GICR, GICC...
- #interrupt-cells:这是一个中断控制器节点的属性。它声明了该中断控制器的中断指示符(interrupts)中 cell 的个数
- interrupt-controller:表示该节点是一个中断控制器
- interrupts:分别代表中断类型,中断号,中断类型, PPI 中断亲和, 保留字段
关于设备数的各个字段含义,详细可以参考 Documentation/devicetree/bindings 下的对应信息。
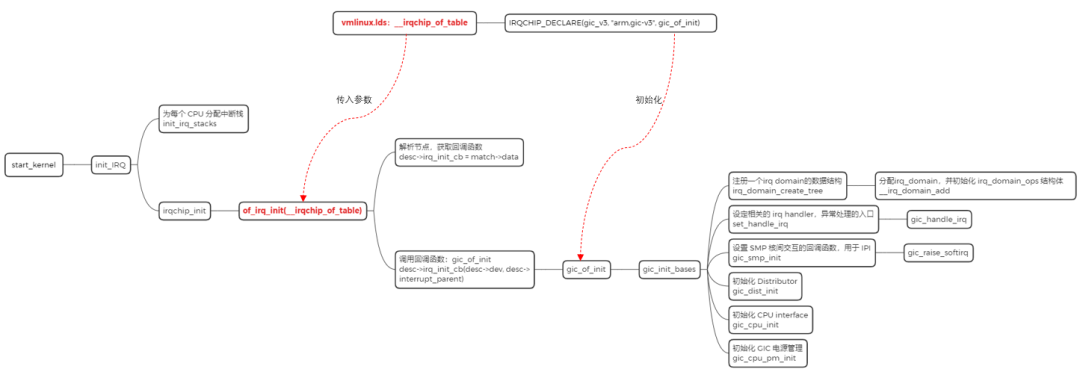
初始化
1. irq chip driver 的声明:
IRQCHIP_DECLARE(gic_v3, <span>"arm,gic-v3"</span>, gic_of_init);
定义 IRQCHIP_DECLARE 之后,相应的内容会保存到 __irqchip_of_table 里边:
<span>#<span>define</span> IRQCHIP_DECLARE(name, compat, fn) OF_DECLARE_2(irqchip, name, compat, fn)</span>
<span>#<span>define</span> OF_DECLARE_2(table, name, compat, fn) \ </span>
_OF_DECLARE(table, name, compat, fn, of_init_fn_2)
<span>#<span>define</span> _OF_DECLARE(table, name, compat, fn, fn_type) \ </span>
<span>static</span> <span>const</span> <span><span>struct</span> <span>of_device_id</span> __<span>of_table_</span>##<span>name</span> \
__<span>used</span> __<span>section</span>(__##<span>table</span>##_<span>of_table</span>) \
= {</span> .compatible = compat, \
.data = (fn == (fn_type)<span>NULL</span>) ? fn : fn }
__irqchip_of_table 在链接脚本 vmlinux.lds 里,被放到了 __irqchip_begin 和 __irqchip_of_end 之间,该段用于存放中断控制器信息:
<span>#<span>ifdef</span> CONFIG_IRQCHIP</span>
<span>#<span>define</span> IRQCHIP_OF_MATCH_TABLE() \<br> . = ALIGN(8); \<br> VMLINUX_SYMBOL(__irqchip_begin) = .; \<br> *(__irqchip_of_table) \<br> *(__irqchip_of_end)</span>
<span>#<span>endif</span></span>
在内核启动初始化中断的函数中,of_irq_init 函数会去查找设备节点信息,该函数的传入参数就是 __irqchip_of_table 段,由于 IRQCHIP_DECLARE 已经将信息填充好了,of_irq_init 函数会根据 “arm,gic-v3” 去查找对应的设备节点,并获取设备的信息。or_irq_init 函数中,最终会回调 IRQCHIP_DECLARE 声明的回调函数,也就是 gic_of_init,而这个函数就是 GIC 驱动的初始化入口。
2. gic_of_init 流程:
<span><span>static</span> <span>int</span> __init <span>gic_of_init</span><span>(struct device_node *node, struct device_node *parent)</span>
</span>{
......
dist_base = of_iomap(node, <span>0</span>); ------(<span>1</span>)
<span>if</span> (!dist_base) {
pr_err(<span>"%pOF: unable to map gic dist registers\n"</span>, node);
<span>return</span> -ENXIO;
}
err = gic_validate_dist_version(dist_base); ------(<span>2</span>)
<span>if</span> (err) {
pr_err(<span>"%pOF: no distributor detected, giving up\n"</span>, node);
<span>goto</span> out_unmap_dist;
}
<span>if</span> (of_property_read_u32(node, <span>"#redistributor-regions"</span>, &nr_redist_regions)) ------(<span>3</span>)
nr_redist_regions = <span>1</span>;
rdist_regs = kzalloc(<span>sizeof</span>(*rdist_regs) * nr_redist_regions, GFP_KERNEL);
<span>if</span> (!rdist_regs) {
err = -ENOMEM;
<span>goto</span> out_unmap_dist;
}
<span>for</span> (i = <span>0</span>; i < nr_redist_regions; i++) { ------(<span>4</span>)
<span><span>struct</span> <span>resource</span> <span>res</span>;</span>
<span>int</span> ret;
ret = of_address_to_resource(node, <span>1</span> + i, &res);
rdist_regs[i].redist_base = of_iomap(node, <span>1</span> + i);
<span>if</span> (ret || !rdist_regs[i].redist_base) {
pr_err(<span>"%pOF: couldn't map region %d\n"</span>, node, i);
err = -ENODEV;
<span>goto</span> out_unmap_rdist;
}
rdist_regs[i].phys_base = res.start;
}
<span>if</span> (of_property_read_u64(node, <span>"redistributor-stride"</span>, &redist_stride)) ------(<span>5</span>)
redist_stride = <span>0</span>;
err = gic_init_bases(dist_base, rdist_regs, nr_redist_regions, ------(<span>6</span>)
redist_stride, &node->fwnode);
<span>if</span> (err)
<span>goto</span> out_unmap_rdist;
gic_populate_ppi_partitions(node); ------(<span>7</span>)
gic_of_setup_kvm_info(node);
<span>return</span> <span>0</span>;
......
<span>return</span> err;
}
- 映射 GICD 的寄存器地址空间。
- 验证 GICD 的版本是 GICv3 还是 GICv4(主要通过读 GICD_PIDR2 寄存器 bit[7:4]。0x1 代表 GICv1, 0x2 代表 GICv2...以此类推)。
- 通过 DTS 读取 redistributor-regions 的值。
- 为一个 GICR 域分配基地址。
- 通过 DTS 读取 redistributor-stride 的值。
- 下面详细介绍。
- 设置一组 PPI 的亲和性。
<span><span>static</span> <span>int</span> __init <span>gic_init_bases</span><span>(<span>void</span> __iomem *dist_base,
struct redist_region *rdist_regs,
u32 nr_redist_regions,
u64 redist_stride,
struct fwnode_handle *handle)</span>
</span>{
......
typer = readl_relaxed(gic_data.dist_base + GICD_TYPER); ------(<span>1</span>)
gic_data.rdists.id_bits = GICD_TYPER_ID_BITS(typer);
gic_irqs = GICD_TYPER_IRQS(typer);
<span>if</span> (gic_irqs > <span>1020</span>)
gic_irqs = <span>1020</span>;
gic_data.irq_nr = gic_irqs;
gic_data.domain = irq_domain_create_tree(handle, &gic_irq_domain_ops, ------(<span>2</span>)
&gic_data);
gic_data.rdists.rdist = alloc_percpu(typeof(*gic_data.rdists.rdist));
gic_data.rdists.has_vlpis = <span>true</span>;
gic_data.rdists.has_direct_lpi = <span>true</span>;
......
set_handle_irq(gic_handle_irq); ------(<span>3</span>)
gic_update_vlpi_properties(); ------(<span>4</span>)
<span>if</span> (IS_ENABLED(CONFIG_ARM_GIC_V3_ITS) && gic_dist_supports_lpis())
its_init(handle, &gic_data.rdists, gic_data.domain); ------(<span>5</span>)
gic_smp_init(); ------(<span>6</span>)
gic_dist_init(); ------(<span>7</span>)
gic_cpu_init(); ------(<span>8</span>)
gic_cpu_pm_init(); ------(<span>9</span>)
<span>return</span> <span>0</span>;
......
}
- 确认支持 SPI 中断号最大的值为多少。
- 向系统中注册一个
irq_domain 的数据结构,irq_domain 主要作用是将硬件中断号映射到 irq number,后面会做详细的介绍。
- 设定 arch 相关的 irq handler。
gic_irq_handle 是内核 gic 中断处理的入口函数,后面会做详细的介绍。
- gic 虚拟化相关的内容。
- 初始化 ITS。
- 设置 SMP 核间交互的回调函数,用于 IPI,回到函数为
gic_raise_softir。
- 初始化 Distributor。
- 初始化 CPU interface。
- 初始化 GIC 电源管理。
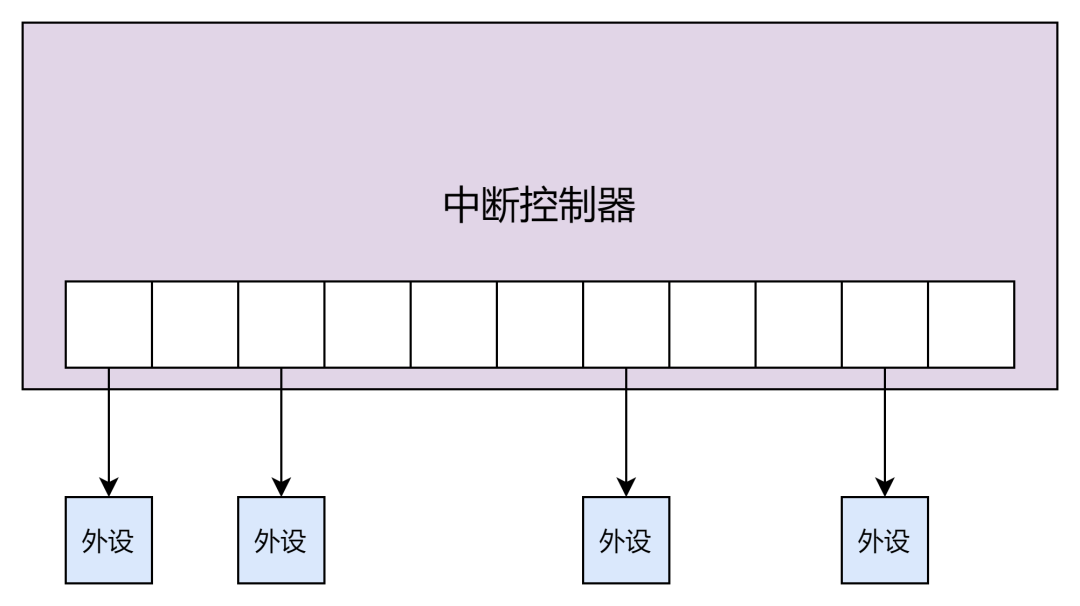
中断的映射
当早期的系统只存在一个中断控制器,而且中断数目也不多的时候,一个很简单的做法就是一个中断号对应到中断控制器的一个号,可以说是简单的线性映射:
但当一个系统中有多个中断控制器,而且中断号也逐渐增加的时候。Linux 内核为了应对此问题,引入了 irq_domain 的概念。
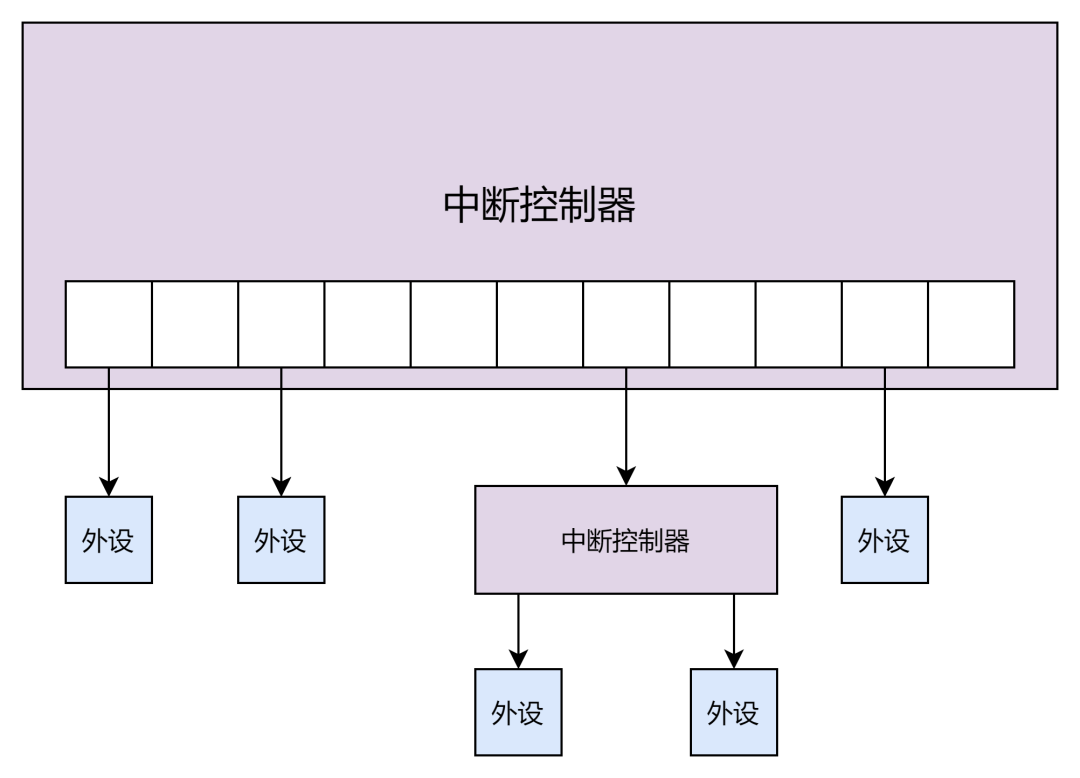
irq_domain 的引入相当于一个中断控制器就是一个 irq_domain。这样一来所有的中断控制器就会出现级联的布局。利用树状的结构可以充分的利用 irq 数目,而且每一个 irq_domain 区域可以自己去管理自己 interrupt 的特性。
每一个中断控制器对应多个中断号,而硬件中断号在不同的中断控制器上是会重复编码的,这时仅仅用硬中断号已经不能唯一标识一个外设中断,因此 Linux kernel 提供了一个虚拟中断号的概念。
接下来我们看下硬件中断号是如何映射到虚拟中断号的。
数据结构
在看硬件中断号映射到虚拟中断号之前,先来看下几个比较重要的数据结构。
struct irq_desc 描述一个外设的中断,称之中断描述符。
<span><span>struct</span> <span>irq_desc</span> {
</span> <span><span>struct</span> <span>irq_common_data</span> <span>irq_common_data</span>;</span>
<span><span>struct</span> <span>irq_data</span> <span>irq_data</span>;</span>
<span>unsigned</span> <span>int</span> __percpu *kstat_irqs;
<span>irq_flow_handler_t</span> handle_irq;
......
<span><span>struct</span> <span>irqaction</span> *<span>action</span>;</span>
......
} ____cacheline_internodealigned_in_smp;
irq_data:中断控制器的硬件数据handle_irq:中断控制器驱动的处理函数,指向一个 struct irqaction 的链表,一个中断源可以多个设备共享,所以一个 irq_desc 可以挂载多个 action,由链表结构组织起来action:设备驱动的处理函数
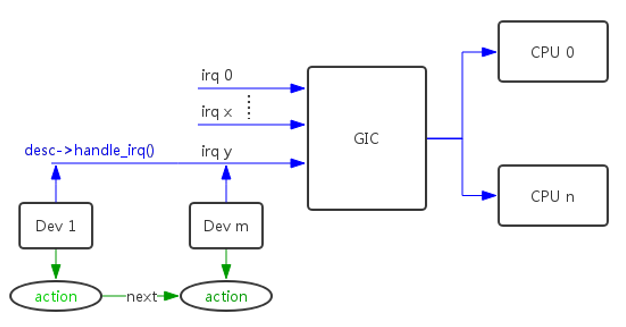
struct irq_data 包含中断控制器的硬件数据。
<span><span>struct</span> <span>irq_data</span> {
</span> u32 mask;
<span>unsigned</span> <span>int</span> irq;
<span>unsigned</span> <span>long</span> hwirq;
<span><span>struct</span> <span>irq_common_data</span> *<span>common</span>;</span>
<span><span>struct</span> <span>irq_chip</span> *<span>chip</span>;</span>
<span><span>struct</span> <span>irq_domain</span> *<span>domain</span>;</span>
<span>#<span>ifdef</span> CONFIG_IRQ_DOMAIN_HIERARCHY</span>
<span><span>struct</span> <span>irq_data</span> *<span>parent_data</span>;</span>
<span>#<span>endif</span></span>
<span>void</span> *chip_data;
};
irq:虚拟中断号hwirq:硬件中断号chip:对应的 irq_chip 数据结构domain:对应的 irq_domain 数据结构
struct irq_chip 用于对中断控制器的硬件操作。
<span><span>struct</span> <span>irq_chip</span> {
</span> <span><span>struct</span> <span>device</span> *<span>parent_device</span>;</span>
<span>const</span> <span>char</span> *name;
<span><span>unsigned</span> <span>int</span> <span>(*irq_startup)</span><span>(struct irq_data *data)</span></span>;
<span>void</span> (*irq_shutdown)(struct irq_data *data);
<span>void</span> (*irq_enable)(struct irq_data *data);
<span>void</span> (*irq_disable)(struct irq_data *data);
<span>void</span> (*irq_ack)(struct irq_data *data);
<span>void</span> (*irq_mask)(struct irq_data *data);
<span>void</span> (*irq_mask_ack)(struct irq_data *data);
<span>void</span> (*irq_unmask)(struct irq_data *data);
<span>void</span> (*irq_eoi)(struct irq_data *data);
<span>int</span> (*irq_set_affinity)(struct irq_data *data, <span>const</span> struct cpumask *dest, <span>bool</span> force);
<span>int</span> (*irq_retrigger)(struct irq_data *data);
<span>int</span> (*irq_set_type)(struct irq_data *data, <span>unsigned</span> <span>int</span> flow_type);
<span>int</span> (*irq_set_wake)(struct irq_data *data, <span>unsigned</span> <span>int</span> on);
<span>void</span> (*irq_bus_lock)(struct irq_data *data);
<span>void</span> (*irq_bus_sync_unlock)(struct irq_data *data);
......
};
parent_device:指向父设备name:/proc/interrupts 中显示的名字irq_startup:启动中断,如果设置成 NULL,则默认为 enableirq_shutdown:关闭中断,如果设置成 NULL,则默认为 disableirq_enable:中断使能,如果设置成 NULL,则默认为 chip->unmaskirq_disable:中断禁止irq_ack:开始新的中断irq_mask:中断源屏蔽irq_mask_ack:应答并屏蔽中断irq_unmask:解除中断屏蔽irq_eoi:中断处理结束后调用irq_set_affinity:在 SMP 中设置 CPU 亲和力irq_retrigger:重新发送中断到 CPUirq_set_type:设置中断触发类型irq_set_wake:使能/禁止电源管理中的唤醒功能irq_bus_lock:慢速芯片总线上的锁irq_bus_sync_unlock:同步释放慢速总线芯片的锁
struct irq_domain 与中断控制器对应,完成硬件中断号 hwirq 到 virq 的映射。
<span><span>struct</span> <span>irq_domain</span> {
</span> <span><span>struct</span> <span>list_head</span> <span>link</span>;</span>
<span>const</span> <span>char</span> *name;
<span>const</span> <span><span>struct</span> <span>irq_domain_ops</span> *<span>ops</span>;</span>
<span>void</span> *host_data;
<span>unsigned</span> <span>int</span> flags;
<span>unsigned</span> <span>int</span> mapcount;
<span>/* Optional data */</span>
<span><span>struct</span> <span>fwnode_handle</span> *<span>fwnode</span>;</span>
<span>enum</span> irq_domain_bus_token bus_token;
<span><span>struct</span> <span>irq_domain_chip_generic</span> *<span>gc</span>;</span>
<span>#<span>ifdef</span> CONFIG_IRQ_DOMAIN_HIERARCHY</span>
<span><span>struct</span> <span>irq_domain</span> *<span>parent</span>;</span>
<span>#<span>endif</span></span>
<span>#<span>ifdef</span> CONFIG_GENERIC_IRQ_DEBUGFS</span>
<span><span>struct</span> <span>dentry</span> *<span>debugfs_file</span>;</span>
<span>#<span>endif</span></span>
<span>/* reverse map data. The linear map gets appended to the irq_domain */</span>
<span>irq_hw_number_t</span> hwirq_max;
<span>unsigned</span> <span>int</span> revmap_direct_max_irq;
<span>unsigned</span> <span>int</span> revmap_size;
<span><span>struct</span> <span>radix_tree_root</span> <span>revmap_tree</span>;</span>
<span>unsigned</span> <span>int</span> linear_revmap[];
};
link:用于将 irq_domain 连接到全局链表 irq_domain_list 中name:irq_domain 的名称ops:irq_domain 映射操作函数集mapcount:映射好的中断的数量fwnode:对应中断控制器的 device nodeparent:指向父级 irq_domain 的指针,用于支持级联 irq_domainhwirq_max:该 irq_domain 支持的中断最大数量linear_revmap[]:hwirq->virq 反向映射的线性表
struct irq_domain_ops 是 irq_domain 映射操作函数集。
<span><span>struct</span> <span>irq_domain_ops</span> {
</span> <span>int</span> (*match)(struct irq_domain *d, struct device_node *node,
<span>enum</span> irq_domain_bus_token bus_token);
<span>int</span> (*select)(struct irq_domain *d, struct irq_fwspec *fwspec,
<span>enum</span> irq_domain_bus_token bus_token);
<span>int</span> (*<span>map</span>)(struct irq_domain *d, <span>unsigned</span> <span>int</span> virq, <span>irq_hw_number_t</span> hw);
<span>void</span> (*unmap)(struct irq_domain *d, <span>unsigned</span> <span>int</span> virq);
<span>int</span> (*xlate)(struct irq_domain *d, struct device_node *node,
<span>const</span> u32 *intspec, <span>unsigned</span> <span>int</span> intsize,
<span>unsigned</span> <span>long</span> *out_hwirq, <span>unsigned</span> <span>int</span> *out_type);
......
};
match:用于中断控制器设备与 irq_domain 的匹配map:用于硬件中断号与 Linux 中断号的映射xlate:通过 device_node,解析硬件中断号和触发方式
struct irqaction 主要是用来存设备驱动注册的中断处理函数。
<span><span>struct</span> <span>irqaction</span> {
</span> <span>irq_handler_t</span> handler;
<span>void</span> *dev_id;
......
<span>unsigned</span> <span>int</span> irq;
<span>unsigned</span> <span>int</span> flags;
......
<span>const</span> <span>char</span> *name;
<span><span>struct</span> <span>proc_dir_entry</span> *<span>dir</span>;</span>
} ____cacheline_internodealigned_in_smp;
handler:设备驱动里的中断处理函数dev_id:设备 idirq:中断号flags:中断标志,注册时设置,比如上升沿中断,下降沿中断等name:中断名称,产生中断的硬件的名字dir:指向 /proc/irq/ 相关的信息
这里,我们用一张图来汇总下上面的数据结构:
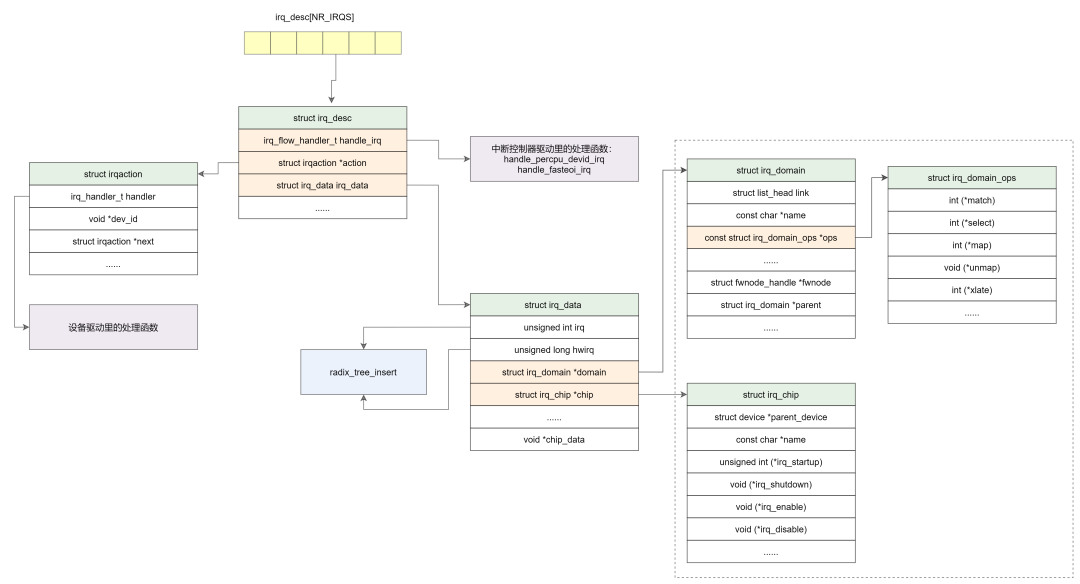
上面的结构体 struct irq_desc 是设备驱动加载的过程中完成的,让设备树中的中断能与具体的中断描述符 irq_desc 匹配,其中 struct irqaction 保存着设备的中断处理函数。右边框内的结构体主要是在中断控制器驱动加载的过程中完成的,其中 struct irq_chip 用于对中断控制器的硬件操作,struct irq_domain 用于硬件中断号到 Linux irq 的映射。
下面我们结合代码看下中断控制器驱动和设备驱动是如何创建这些结构体,并且硬中断和虚拟中断号是如何完成映射的。
中断控制器注册 irq_domain

通过 __irq_domain_add 初始化 irq_domain 数据结构,然后把 irq_domain 添加到全局的链表 irq_domain_list 中。
外设的驱动创建硬中断和虚拟中断号的映射关系
设备的驱动在初始化的时候可以调用 irq_of_parse_and_map 这个接口函数进行该 device node 中和中断相关的内容的解析,并建立映射关系。
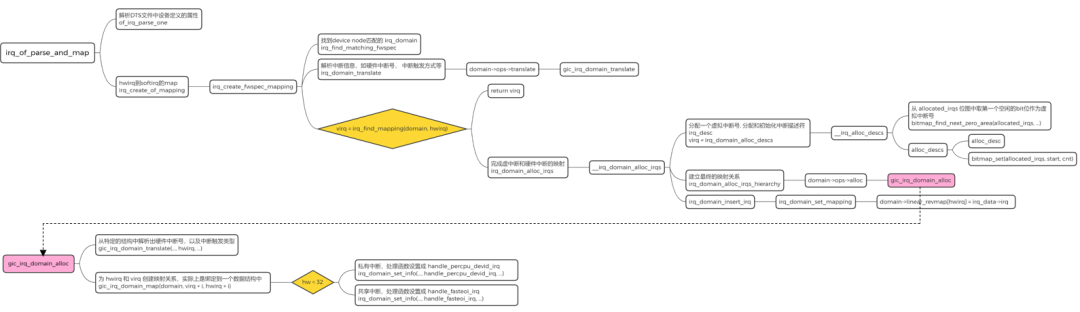
of_irq_parse_one 函数用于解析 DTS 文件中设备定义的属性,如 “reg”,“interrupt”irq_find_matching_fwspec 遍历 irq_domain_list 链表,找到 device node 匹配的 irq_domaingic_irq_domain_translate 解析出中断信息,比如硬件中断号 hwirq,中断触发方式irq_domain_alloc_descs 分配一个虚拟的中断号 virq,分配和初始化中断描述符 irq_descgic_irq_domain_alloc 为 hwirq 和 virq 创建映射关系。内部会通过 irq_domain_set_info 调用 irq_domain_set_hwirq_and_chip,然后通过 virq 获取 irq_data 结构体,并将 hwirq 设置到 irq_data->hwirq 中,最终完成 hwirq 到 virq 的映射irq_domain_set_info 根据硬件中断号的范围设置 irq_desc->handle_irq 的指针,共享中断入口为 handle_fasteoi_irq,私有中断入口为 handle_percpu_devid_irq
最后,我们可以通过 /proc/interrupts 下的值来看下它们的关系:
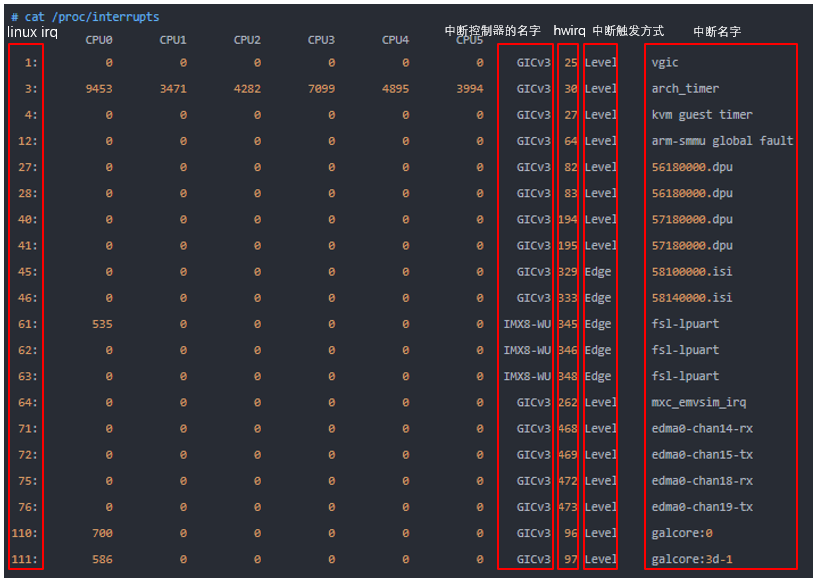
现在,我们已经知道内核为硬件中断号与 Linux 中断号做了映射,相关数据结构的绑定及初始化,并且设置了中断处理函数执行的入口。接下来我们再看下设备的中断是怎么来注册的?
中断的注册
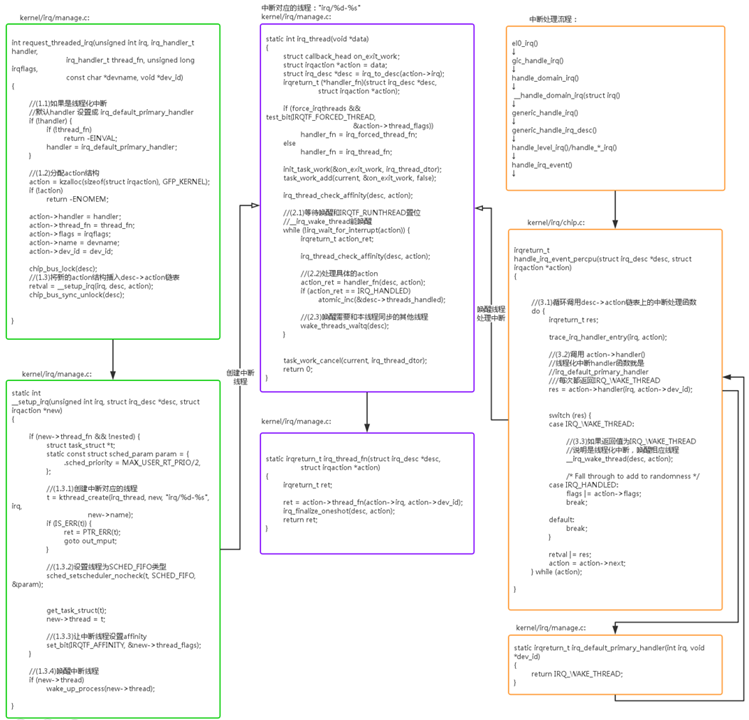
设备驱动中,获取到了 irq 中断号后,通常就会采用 request_irq/request_threaded_irq 来注册中断,其中 request_irq 用于注册普通处理的中断。request_threaded_irq 用于注册线程化处理的中断,线程化中断的主要目的把中断上下文的任务迁移到线程中,减少系统关中断的时间,增强系统的实时性。
<span><span>static</span> <span>inline</span> <span>int</span> __must_check
<span>request_irq</span><span>(<span>unsigned</span> <span>int</span> irq, <span>irq_handler_t</span> handler, <span>unsigned</span> <span>long</span> flags,
<span>const</span> <span>char</span> *name, <span>void</span> *dev)</span>
</span>{
<span>return</span> request_threaded_irq(irq, handler, <span>NULL</span>, flags, name, dev);
}
其中 irq 是 linux 中断号,handler 是中断处理函数,flags 是中断标志位,name 是中断的名字。在讲具体的注册流程前,先看一下主要的中断标志位:
<span>#<span>define</span> IRQF_SHARED 0x00000080 <span>//多个设备共享一个中断号,需要外设硬件支持</span></span>
<span>#<span>define</span> IRQF_PROBE_SHARED 0x00000100 <span>//中断处理程序允许sharing mismatch发生</span></span>
<span>#<span>define</span> __IRQF_TIMER 0x00000200 <span>//时钟中断</span></span>
<span>#<span>define</span> IRQF_PERCPU 0x00000400 <span>//属于特定CPU的中断</span></span>
<span>#<span>define</span> IRQF_NOBALANCING 0x00000800 <span>//禁止在CPU之间进行中断均衡处理</span></span>
<span>#<span>define</span> IRQF_IRQPOLL 0x00001000 <span>//中断被用作轮训</span></span>
<span>#<span>define</span> IRQF_ONESHOT 0x00002000 <span>//一次性触发的中断,不能嵌套,1)在硬件中断处理完成后才能打开中断;2)在中断线程化中保持关闭状态,直到该中断源上的所有thread_fn函数都执行完</span></span>
<span>#<span>define</span> IRQF_NO_SUSPEND 0x00004000 <span>//系统休眠唤醒操作中,不关闭该中断</span></span>
<span>#<span>define</span> IRQF_FORCE_RESUME 0x00008000 <span>//系统唤醒过程中必须强制打开该中断</span></span>
<span>#<span>define</span> IRQF_NO_THREAD 0x00010000 <span>//禁止中断线程化</span></span>
<span>#<span>define</span> IRQF_EARLY_RESUME 0x00020000 <span>//系统唤醒过程中在syscore阶段resume,而不用等到设备resume阶段</span></span>
<span>#<span>define</span> IRQF_COND_SUSPEND 0x00040000 <span>//与NO_SUSPEND的用户共享中断时,执行本设备的中断处理函数</span></span>
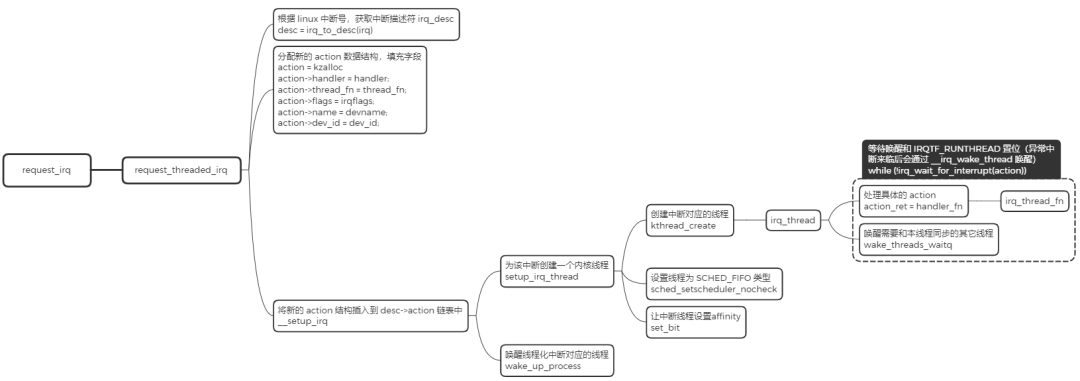
创建完成后,通过 ps 命令可以查看系统中的中断线程,注意这些线程是实时线程 SCHED_FIFO:
<span># ps -A | grep <span>"irq/"</span></span>
root <span>1749</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>433</span>-imx_drm]
root <span>1750</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>439</span>-imx_drm]
root <span>1751</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>445</span>-imx_drm]
root <span>1752</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>451</span>-imx_drm]
root <span>2044</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>279</span>-isl2902]
root <span>2192</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>114</span>-mmc0]
root <span>2199</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>115</span>-mmc1]
root <span>2203</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>322</span><span>-5b</span>02000]
root <span>2361</span> <span>2</span> <span>0</span> <span>0</span> irq_thread <span>0</span> S [irq/<span>294</span><span>-4</span><span>-0051</span>]
中断的处理
当完成中断的注册后,所有结构的组织关系都已经建立好,剩下的工作就是当信号来临时,进行中断的处理工作。这里我们站在前面知识点的基础上,把中断触发,中断处理等整个流程走一遍。
假设当前在 EL0 运行一个应用程序,触发了一个 EL0 的 irq 中断,则处理器会做如下的操作:
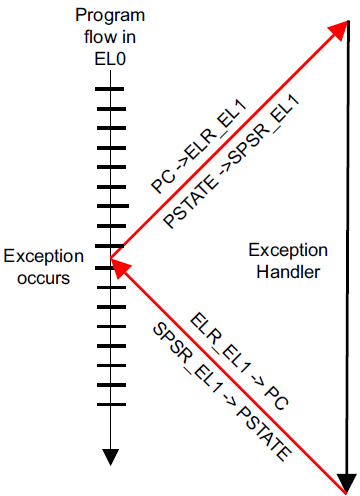
先会跳到 arm64 对应的异常向量表:
<span>/*
* Exception vectors.
*/</span>
.pushsection <span>".entry.text"</span>, <span>"ax"</span>
.align <span>11</span>
SYM_CODE_START(vectors)
......
kernel_ventry <span>1</span>, sync <span>// el1 下的同步异常,例如指令执行异常、缺页中断等</span>
kernel_ventry <span>1</span>, irq <span>// el1 下的异步异常,硬件中断。1代表异常等级</span>
kernel_ventry <span>1</span>, fiq_invalid <span>// FIQ EL1h</span>
kernel_ventry <span>1</span>, error <span>// Error EL1h</span>
kernel_ventry <span>0</span>, sync <span>// el0 下的同步异常,例如指令执行异常、缺页中断(跳转地址或者取地址)、系统调用等</span>
kernel_ventry <span>0</span>, irq <span>// el0 下的异步异常,硬件中断。0代表异常等级</span>
kernel_ventry <span>0</span>, fiq_invalid <span>// FIQ 64-bit EL0</span>
kernel_ventry <span>0</span>, error <span>// Error 64-bit EL0</span>
......
<span>#<span>endif</span></span>
SYM_CODE_END(vectors)
arm64 的异常向量表 vectors 中设置了各种异常的入口。kernel_ventry 展开后,可以看到有效的异常入口有两个同步异常 el0_sync,el1_sync 和两个异步异常 el0_irq,el1_irq,其他异常入口暂时都 invalid。中断属于异步异常。
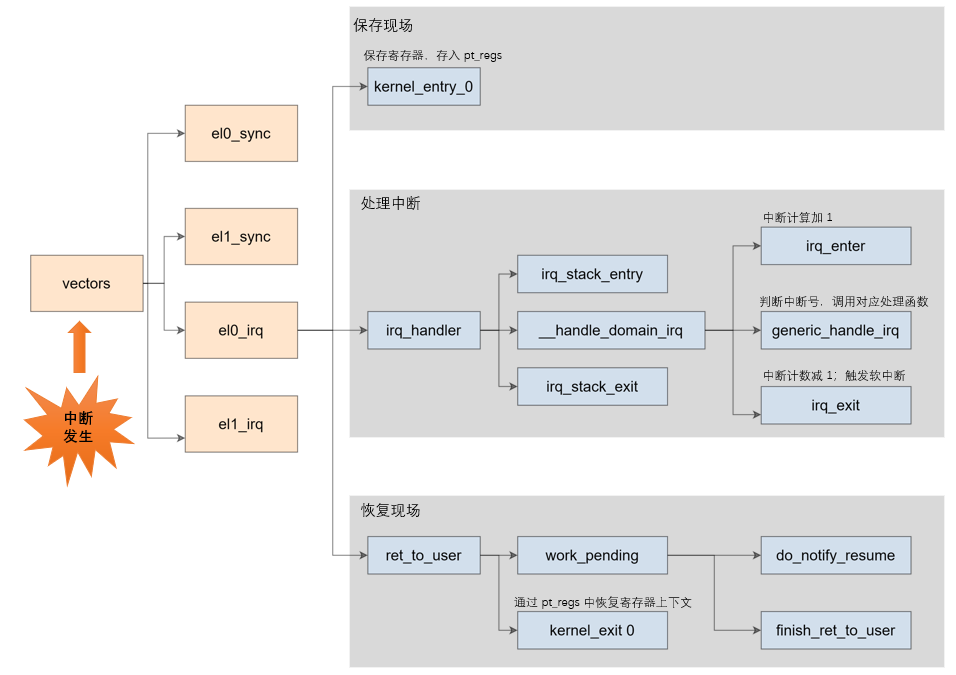
通过上图,我们可以看出中断的处理分为三个部分,保护现场,中断处理,恢复现场。其中 el0_irq 和 el1_irq 的具体实现略有不同,但处理流程大致是相同的。接下来我们以 el0_irq 为例对上面三个步骤进行梳理。
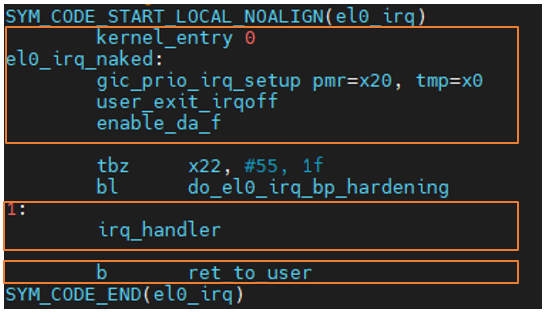
保护现场
kernel_entry 0,其中 kernel_entry 是一个宏,此宏会将 CPU 寄存器按照 pt_regs 结构体的定义将第一现场保存到栈上。
.macro kernel_entry, el, regsize = <span>64</span>
.<span>if</span> \regsize == <span>32</span>
mov w0, w0 <span>// zero upper 32 bits of x0</span>
.endif
stp x0, x1, [sp, #<span>16</span> * <span>0</span>]
stp x2, x3, [sp, #<span>16</span> * <span>1</span>]
stp x4, x5, [sp, #<span>16</span> * <span>2</span>]
stp x6, x7, [sp, #<span>16</span> * <span>3</span>]
stp x8, x9, [sp, #<span>16</span> * <span>4</span>]
stp x10, x11, [sp, #<span>16</span> * <span>5</span>]
stp x12, x13, [sp, #<span>16</span> * <span>6</span>]
stp x14, x15, [sp, #<span>16</span> * <span>7</span>]
stp x16, x17, [sp, #<span>16</span> * <span>8</span>]
stp x18, x19, [sp, #<span>16</span> * <span>9</span>]
stp x20, x21, [sp, #<span>16</span> * <span>10</span>]
stp x22, x23, [sp, #<span>16</span> * <span>11</span>]
stp x24, x25, [sp, #<span>16</span> * <span>12</span>]
stp x26, x27, [sp, #<span>16</span> * <span>13</span>]
stp x28, x29, [sp, #<span>16</span> * <span>14</span>]
.<span>if</span> \el == <span>0</span>
clear_gp_regs
mrs x21, sp_el0
ldr_this_cpu tsk, __entry_task, x20
msr sp_el0, tsk
enable_da_f 是关闭中断。
<span>/* IRQ is the lowest priority flag, unconditionally unmask the rest. */</span>
.macro enable_da_f
msr daifclr, #(<span>8</span> | <span>4</span> | <span>1</span>)
.endm
总之,保存现场主要是下面三个操作:
- 保存 PSTATE 到 SPSR_ELx 寄存器
- 将 PSTATE 中的 D A I F 全部屏蔽
- 保存 PC 寄存器的值到 ELR_ELx 寄存器
中断处理
保存过现场后,即将跳入中断处理 irq_handler。
<span>/*
* Interrupt handling.
*/</span>
.macro irq_handler
ldr_l x1, handle_arch_irq
mov x0, sp
irq_stack_entry <span>//进入中断栈</span>
blr x1 <span>//执行 handle_arch_irq</span>
irq_stack_exit <span>//退出中断栈</span>
.endm
这里主要做了三个动作:
- 进入中断栈
- 执行中断控制器的
handle_arch_irq
- 退出中断栈
中断栈用来保存中断的上下文,中断发生和退出的时候调用 irq_stack_entry 和 irq_stack_exit 来进入和退出中断栈。中断栈是在内核启动时就创建好的,内核在启动过程中会去为每个 CPU 创建一个 per cpu 的中断栈:start_kernel->init_IRQ->init_irq_stacks
那中断控制器的 handle_arch_irq 又指向哪里呢?其实上面我们有讲到,在内核启动过程中初始化中断控制器时,设置了具体的 handler,gic_init_bases->set_handle_irq 将 handle_arch_irq 指针指向 gic_handle_irq 函数。代码如下:
<span><span>void</span> __init <span>set_handle_irq</span><span>(<span>void</span> (*handle_irq)(struct pt_regs *))</span>
</span>{
<span>if</span> (handle_arch_irq)
<span>return</span>;
handle_arch_irq = handle_irq;
}
<span><span>static</span> <span>int</span> __init <span>gic_init_bases</span><span>(<span>void</span> __iomem *dist_base,
struct redist_region *rdist_regs,
u32 nr_redist_regions,
u64 redist_stride,
struct fwnode_handle *handle)</span>
</span>{
set_handle_irq(gic_handle_irq);
}
所以,中断处理最终会进入 gic_handle_irq:
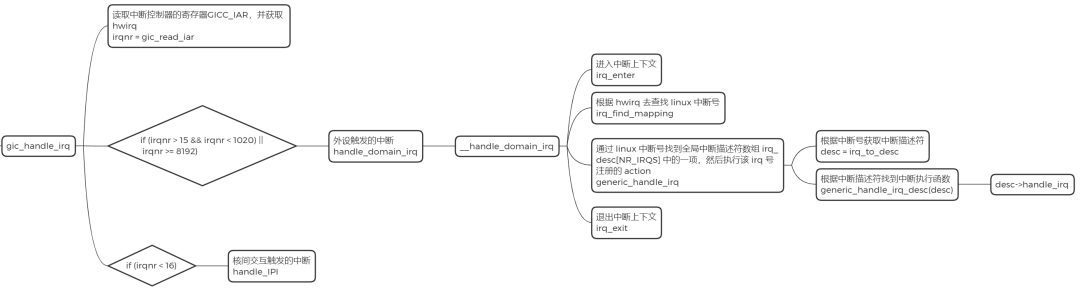
<span><span>static</span> asmlinkage <span>void</span> __exception_irq_entry <span>gic_handle_irq</span><span>(struct pt_regs *regs)</span>
</span>{
u32 irqnr;
<span>do</span> {
irqnr = gic_read_iar(); ------(<span>1</span>)
<span>if</span> (likely(irqnr > <span>15</span> && irqnr < <span>1020</span>) || irqnr >= <span>8192</span>) { ------(<span>2</span>)
<span>int</span> err;
<span>if</span> (static_key_true(&supports_deactivate))
gic_write_eoir(irqnr);
<span>else</span>
isb();
err = handle_domain_irq(gic_data.domain, irqnr, regs); ------(<span>3</span>)
<span>if</span> (err) {
WARN_ONCE(<span>true</span>, <span>"Unexpected interrupt received!\n"</span>);
<span>if</span> (static_key_true(&supports_deactivate)) {
<span>if</span> (irqnr < <span>8192</span>)
gic_write_dir(irqnr);
} <span>else</span> {
gic_write_eoir(irqnr);
}
}
<span>continue</span>;
}
<span>if</span> (irqnr < <span>16</span>) { ------(<span>4</span>)
gic_write_eoir(irqnr);
<span>if</span> (static_key_true(&supports_deactivate))
gic_write_dir(irqnr);
<span>#<span>ifdef</span> CONFIG_SMP</span>
<span>/*
* Unlike GICv2, we don't need an smp_rmb() here.
* The control dependency from gic_read_iar to
* the ISB in gic_write_eoir is enough to ensure
* that any shared data read by handle_IPI will
* be read after the ACK.
*/</span>
handle_IPI(irqnr, regs); ------(<span>5</span>)
<span>#<span>else</span></span>
WARN_ONCE(<span>true</span>, <span>"Unexpected SGI received!\n"</span>);
<span>#<span>endif</span></span>
<span>continue</span>;
}
} <span>while</span> (irqnr != ICC_IAR1_EL1_SPURIOUS);
}
- 读取中断控制器的寄存器 GICC_IAR,并获取
hwirq
- 外设触发的中断。硬件中断号 0-15 表示 SGI 类型的中断,15-1020 表示外设中断(SPI 或 PPI 类型),8192-MAX 表示 LPI 类型的中断
- 中断控制器中断处理的主体
- 软件触发的中断
- 核间交互触发的中断
中断控制器中断处理的主体,如下所示:
<span>int</span> __handle_domain_irq(struct irq_domain *domain, <span>unsigned</span> <span>int</span> hwirq,
<span>bool</span> lookup, struct pt_regs *regs)
{
<span><span>struct</span> <span>pt_regs</span> *<span>old_regs</span> = <span>set_irq_regs</span>(<span>regs</span>);
<span>unsigned</span> <span>int</span> irq = hwirq;
<span>int</span> ret = <span>0</span>;
irq_enter(); ------(<span>1</span>)
<span>#<span>ifdef</span> CONFIG_IRQ_DOMAIN</span>
<span>if</span> (lookup)
irq = irq_find_mapping(domain, hwirq); ------(<span>2</span>)
<span>#<span>endif</span></span>
<span>/*
* Some hardware gives randomly wrong interrupts. Rather
* than crashing, do something sensible.
*/</span>
<span>if</span> (unlikely(!irq || irq >= nr_irqs)) {
ack_bad_irq(irq);
ret = -EINVAL;
} <span>else</span> {
generic_handle_irq(irq); ------(<span>3</span>)
}
irq_exit(); ------(<span>4</span>)
set_irq_regs(old_regs);
<span>return</span> ret;
}
- 进入中断上下文
- 根据
hwirq 去查找 linux 中断号
- 通过中断号找到全局中断描述符数组
irq_desc[NR_IRQS] 中的一项,然后调用 generic_handle_irq_desc,执行该 irq 号注册的 action
- 退出中断上下文
<span><span>static</span> <span>inline</span> <span>void</span> <span>generic_handle_irq_desc</span><span>(struct irq_desc *desc)</span>
</span>{
desc->handle_irq(desc);
}
调用 desc->handle_irq 指向的回调函数。
irq_domain_set_info 根据硬件中断号的范围设置 irq_desc->handle_irq 的指针,共享中断入口为 handle_fasteoi_irq,私有中断入口为 handle_percpu_devid_irq。如下所示:
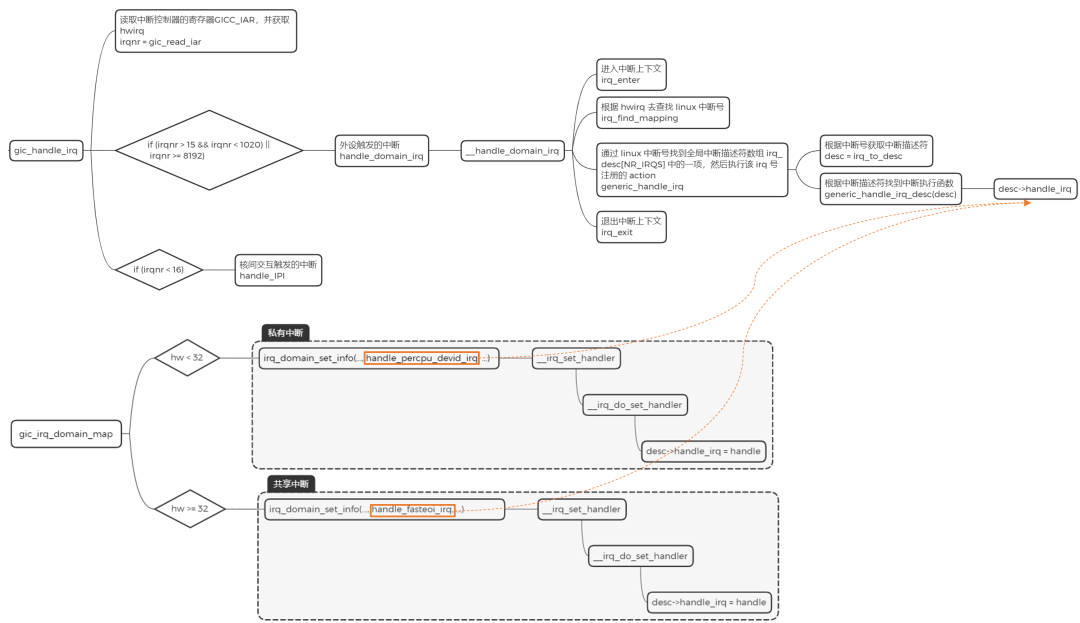
handle_percpu_devid_irq:处理私有中断处理,在这个过程中会分别调用中断控制器的处理函数进行硬件操作,该函数调用 action->handler() 来进行中断处理handle_fasteoi_irq:处理共享中断,并且遍历 irqaction 链表,逐个调用 action->handler() 函数,这个函数正是设备驱动程序调用 request_irq/request_threaded_irq 接口注册的中断处理函数,此外如果中断线程化处理的话,还会调用 __irq_wake_thread 唤醒内核线程。
恢复现场
SYM_CODE_START_LOCAL(ret_to_user)
disable_daif <span>//D A I F 分别为PSTAT中的四个异常屏蔽标志位,此处屏蔽这4中异常</span>
gic_prio_kentry_setup tmp=x3
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
ldr x19, [tsk, #TSK_TI_FLAGS] <span>//获取 thread_info 中的flags变量的值</span>
<span>and</span> x2, x19, #_TIF_WORK_MASK
cbnz x2, work_pending
finish_ret_to_user:
user_enter_irqoff
<span>/* Ignore asynchronous tag check faults in the uaccess routines */</span>
clear_mte_async_tcf
enable_step_tsk x19, x2
#ifdef CONFIG_GCC_PLUGIN_STACKLEAK
bl stackleak_erase
#endif
kernel_exit <span>0</span> <span>//恢复 pt_regs 中的寄存器上下文</span>
主要分三步:
- disable 中断
- 检查在退出中断前有没有需要处理事情,如调度、信号处理等
- 将之前压栈的
pt_regs 弹出,恢复现场
总结
上面讲了中断控制器和设备驱动的初始化。包括从设备树获取中断源信息的解析,硬件中断号到 Linux 中断号的映射关系,irq_desc 等各个结构的分配及初始化、中断的注册等等,总而言之,就是完成静态关系创建,为中断处理做好准备。
当外设触发中断信号时,中断控制器接收到信号并发送到处理器,此时处理器进行异常模式切换,如果涉及到中断线程化,则还需要进行中断内核线程的唤醒操作,最终完成中断处理函数的执行。
最后,用一张图来汇总中断控制器和设备驱动的来龙去脉:
中断下半部之 workqueue
workqueue 是除了 softirq 和 tasklet 以外最常用的下半部机制之一。workqueue 的本质是把 work 交给一个内核线程,在进程上下文调度的时候执行。因为这个特点,所以 workqueue 允许重新调度和睡眠,这种异步执行的进程上下文,能解决因为 softirq 和 tasklet 执行时间长而导致的系统实时性下降等问题。
当驱动程序在进程上下文中有异步执行的工作任务时,可以用 work 来描述工作任务。把 work 添加到一个链表 worklist 中,然后由一个内核线程 worker 遍历链表,串行地执行挂入 worklist 中的所有 work。如果 worklist 中没有 work,那么内核线程 worker 就会变成 IDLE 状态;如果有 work,则执行 work 中的回调函数。
workqueue 相关的数据结构
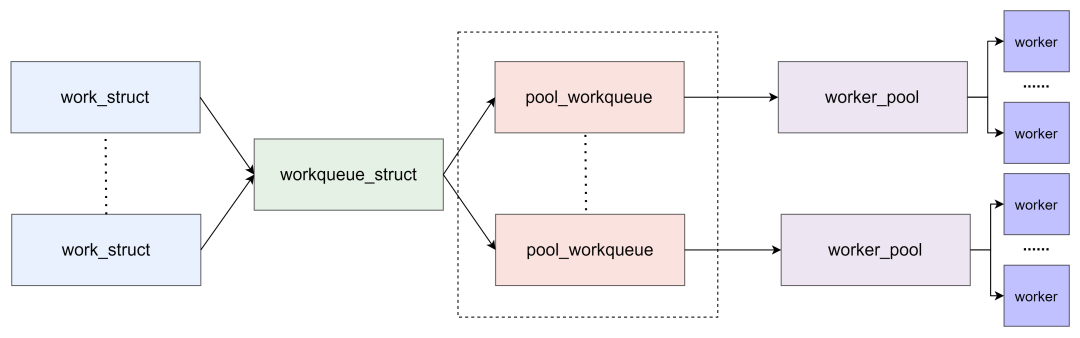
关于 workqueue 中几个概念都是 work 相关的数据结构非常容易混淆,大概可以这样来理解:
work_struct :
工作。初始化一个 work 并添加到工作队列后,将会将其传递到合适的内核线程来进行处理,它是用于调度的最小单位。
<span><span>struct</span> <span>work_struct</span> {
</span> <span>atomic_long_t</span> data;
<span><span>struct</span> <span>list_head</span> <span>entry</span>;</span>
<span>work_func_t</span> func;
<span>#<span>ifdef</span> CONFIG_LOCKDEP</span>
<span><span>struct</span> <span>lockdep_map</span> <span>lockdep_map</span>;</span>
<span>#<span>endif</span></span>
};
data:低比特存放状态位,高比特存放 worker_pool 的ID或者 pool_workqueue 的指针entry:用于添加到其他队列上func:工作任务的处理函数,在内核线程中回调
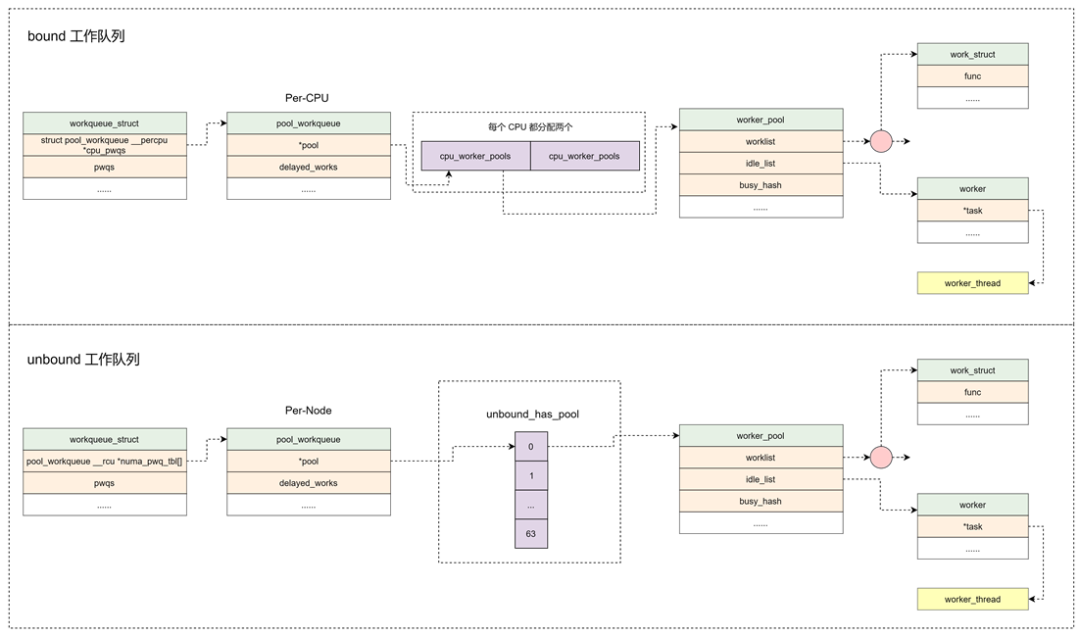
workqueue_struct :
工作的集合。workqueue 和 work 是一对多的关系。内核中工作队列分为两种:
- bound:绑定处理器的工作队列,每个
worker 创建的内核线程绑定到特定的 CPU 上运行。
- unbound:不绑定处理器的工作队列,创建的时候需要指定 WQ_UNBOUND 标志,内核线程可以在处理器间迁移。
<span><span>struct</span> <span>workqueue_struct</span> {
</span> <span><span>struct</span> <span>list_head</span> <span>pwqs</span>;</span> <span>/* WR: all pwqs of this wq */</span>
<span><span>struct</span> <span>list_head</span> <span>list</span>;</span> <span>/* PR: list of all workqueues */</span>
<span><span>struct</span> <span>list_head</span> <span>maydays</span>;</span> <span>/* MD: pwqs requesting rescue */</span>
<span><span>struct</span> <span>worker</span> *<span>rescuer</span>;</span> <span>/* I: rescue worker */</span>
<span><span>struct</span> <span>pool_workqueue</span> *<span>dfl_pwq</span>;</span> <span>/* PW: only for unbound wqs */</span>
<span>char</span> name[WQ_NAME_LEN]; <span>/* I: workqueue name */</span>
<span>/* hot fields used during command issue, aligned to cacheline */</span>
<span>unsigned</span> <span>int</span> flags ____cacheline_aligned; <span>/* WQ: WQ_* flags */</span>
<span><span>struct</span> <span>pool_workqueue</span> __<span>percpu</span> *<span>cpu_pwqs</span>;</span> <span>/* I: per-cpu pwqs */</span>
<span><span>struct</span> <span>pool_workqueue</span> __<span>rcu</span> *<span>numa_pwq_tbl</span>[];</span> <span>/* PWR: unbound pwqs indexed by node */</span> <span>//Per-Node创建pool_workqueue</span>
...
};
pwqs:所有的 pool_workqueue 都添加到本链表中list:用于将工作队列添加到全局链表 workqueues 中maydays:rescue 状态下的 pool_workqueue 添加到本链表中rescuer:rescuer 内核线程,用于处理内存紧张时创建工作线程失败的情况cpu_pwqs:Per-CPU 创建 pool_workqueuenuma_pwq_tbl[]:Per-Node 创建 pool_workqueue
pool_workqueue:
中间人 / 中介,负责建立起 workqueue 和 worker_pool 之间的关系。workqueue 和 pool_workqueue 是一对多的关系。
<span><span>struct</span> <span>pool_workqueue</span> {
</span> <span><span>struct</span> <span>worker_pool</span> *<span>pool</span>;</span> <span>/* I: the associated pool */</span>
<span><span>struct</span> <span>workqueue_struct</span> *<span>wq</span>;</span> <span>/* I: the owning workqueue */</span>
<span>int</span> nr_active; <span>/* L: nr of active works */</span>
<span>int</span> max_active; <span>/* L: max active works */</span>
<span><span>struct</span> <span>list_head</span> <span>delayed_works</span>;</span> <span>/* L: delayed works */</span>
<span><span>struct</span> <span>list_head</span> <span>pwqs_node</span>;</span> <span>/* WR: node on wq->pwqs */</span>
<span><span>struct</span> <span>list_head</span> <span>mayday_node</span>;</span> <span>/* MD: node on wq->maydays */</span> <span>//用于添加到workqueue链表中</span>
...
} __aligned(<span>1</span> << WORK_STRUCT_FLAG_BITS);
pool:指向 worker_poolwq:指向所属的 workqueuenr_active:活跃的 work 数量max_active:活跃的最大 work 数量delayed_works:延迟执行的 work 挂入本链表pwqs_node:用于添加到 workqueue 链表中mayday_node:用于添加到 workqueue 链表中
worker_pool:
工人的集合。pool_workqueue 和 worker_pool 是一对一的关系,worker_pool 和 worker 是一对多的关系。
- bound 类型的工作队列:
worker_pool 是 Per-CPU 创建,每个 CPU 都有两个 worker_pool,对应不同的优先级,nice 值分别为 0 和 -20。
- unbound 类型的工作队列:
worker_pool 创建后会添加到 unbound_pool_hash 哈希表中。
<span><span>struct</span> <span>worker_pool</span> {
</span> <span>spinlock_t</span> lock; <span>/* the pool lock */</span>
<span>int</span> cpu; <span>/* I: the associated cpu */</span>
<span>int</span> node; <span>/* I: the associated node ID */</span>
<span>int</span> id; <span>/* I: pool ID */</span>
<span>unsigned</span> <span>int</span> flags; <span>/* X: flags */</span>
<span>unsigned</span> <span>long</span> watchdog_ts; <span>/* L: watchdog timestamp */</span>
<span><span>struct</span> <span>list_head</span> <span>worklist</span>;</span> <span>/* L: list of pending works */</span>
<span>int</span> nr_workers; <span>/* L: total number of workers */</span>
<span>/* nr_idle includes the ones off idle_list for rebinding */</span>
<span>int</span> nr_idle; <span>/* L: currently idle ones */</span>
<span><span>struct</span> <span>list_head</span> <span>idle_list</span>;</span> <span>/* X: list of idle workers */</span>
<span><span>struct</span> <span>timer_list</span> <span>idle_timer</span>;</span> <span>/* L: worker idle timeout */</span>
<span><span>struct</span> <span>timer_list</span> <span>mayday_timer</span>;</span> <span>/* L: SOS timer for workers */</span>
<span>/* a workers is either on busy_hash or idle_list, or the manager */</span>
DECLARE_HASHTABLE(busy_hash, BUSY_WORKER_HASH_ORDER); <span>/* L: hash of busy workers */</span>
<span>/* see manage_workers() for details on the two manager mutexes */</span>
<span><span>struct</span> <span>worker</span> *<span>manager</span>;</span> <span>/* L: purely informational */</span>
<span><span>struct</span> <span>mutex</span> <span>attach_mutex</span>;</span> <span>/* attach/detach exclusion */</span>
<span><span>struct</span> <span>list_head</span> <span>workers</span>;</span> <span>/* A: attached workers */</span>
<span><span>struct</span> <span>completion</span> *<span>detach_completion</span>;</span> <span>/* all workers detached */</span>
<span><span>struct</span> <span>ida</span> <span>worker_ida</span>;</span> <span>/* worker IDs for task name */</span>
<span><span>struct</span> <span>workqueue_attrs</span> *<span>attrs</span>;</span> <span>/* I: worker attributes */</span>
<span><span>struct</span> <span>hlist_node</span> <span>hash_node</span>;</span> <span>/* PL: unbound_pool_hash node */</span>
...
} ____cacheline_aligned_in_smp;
cpu:绑定到 CPU 的 workqueue,代表 CPU IDnode:非绑定类型的 workqueue,代表内存 Node IDworklist:pending 状态的 work 添加到本链表nr_workers:worker 的数量idle_list:处于 IDLE 状态的 worker 添加到本链表busy_hash:工作状态的 worker 添加到本哈希表中workers:worker_pool 管理的 worker 添加到本链表中hash_node:用于添加到 unbound_pool_hash 中
worker :
工人。在代码中 worker 对应一个 work_thread() 内核线程。
<span><span>struct</span> <span>worker</span> {
</span> <span>/* on idle list while idle, on busy hash table while busy */</span>
<span>union</span> {
<span><span>struct</span> <span>list_head</span> <span>entry</span>;</span> <span>/* L: while idle */</span>
<span><span>struct</span> <span>hlist_node</span> <span>hentry</span>;</span> <span>/* L: while busy */</span>
};
<span><span>struct</span> <span>work_struct</span> *<span>current_work</span>;</span> <span>/* L: work being processed */</span>
<span>work_func_t</span> current_func; <span>/* L: current_work's fn */</span>
<span><span>struct</span> <span>pool_workqueue</span> *<span>current_pwq</span>;</span> <span>/* L: current_work's pwq */</span>
<span><span>struct</span> <span>list_head</span> <span>scheduled</span>;</span> <span>/* L: scheduled works */</span>
<span>/* 64 bytes boundary on 64bit, 32 on 32bit */</span>
<span><span>struct</span> <span>task_struct</span> *<span>task</span>;</span> <span>/* I: worker task */</span>
<span><span>struct</span> <span>worker_pool</span> *<span>pool</span>;</span> <span>/* I: the associated pool */</span>
<span>/* L: for rescuers */</span>
<span><span>struct</span> <span>list_head</span> <span>node</span>;</span> <span>/* A: anchored at pool->workers */</span> <span>//添加到worker_pool->workers链表中</span>
<span>/* A: runs through worker->node */</span>
...
};
entry:用于添加到 worker_pool 的空闲链表中hentry:用于添加到 worker_pool 的忙碌列表中current_work:当前正在处理的 workcurrent_func:当前正在执行的 work 回调函数current_pwq:指向当前 work 所属的 pool_workqueuescheduled:所有被调度执行的 work 都将添加到该链表中task:指向内核线程pool:该 worker 所属的 worker_poolnode:添加到 worker_pool->workers 链表中
可以用下图来总结:
workqueue 的初始化
内核在启动的时候会对 workqueue 做初始化,workqueue 的初始化包含两个阶段,分别是 workqueue_init_early 和 workqueue_init。
workqueue_init_early
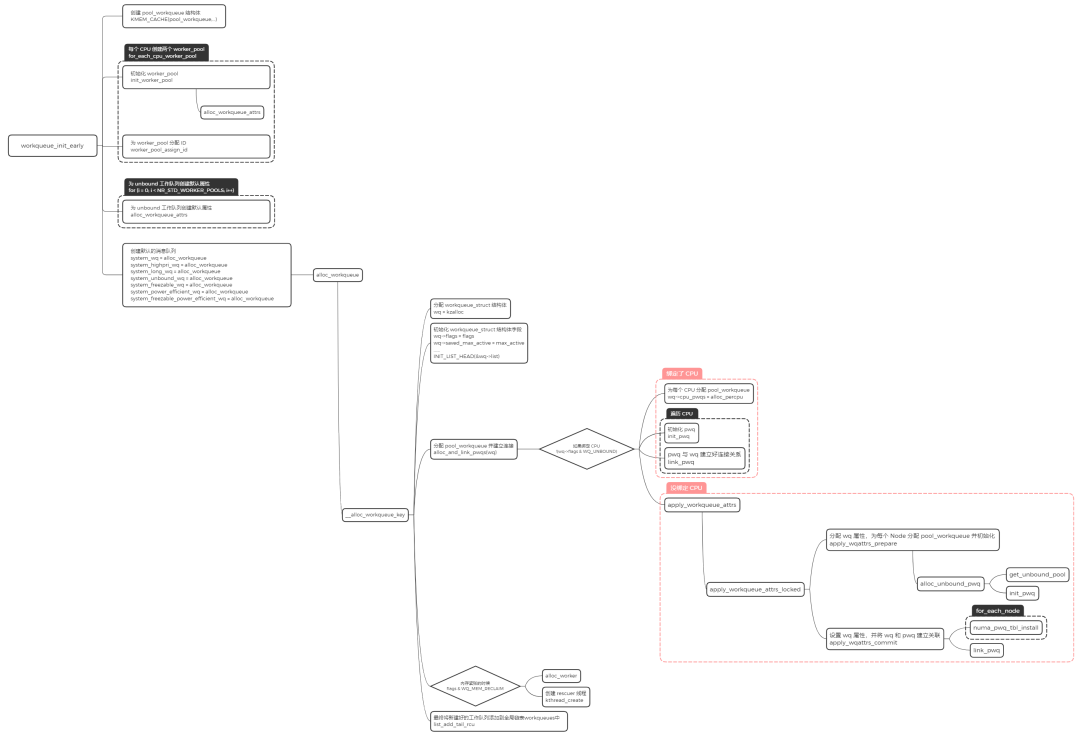
- 分配
worker_pool,并且对该结构中的字段进行初始化操作
- 分配
workqueue_struct,并且对该结构中的字段进行初始化操作
alloc_and_link_pwqs:分配 pool_workqueue,将 workqueue_struct 和 worker_pool 关联起来
workqueue_init
这里主要完成的工作是给之前创建好的 worker_pool,添加一个初始的 worker,然后利用函数 create_worker,创建名字为 kworker/XX:YY 或者 kworker/uXX:YY 的内核线程。其中 XX 表示 worker_pool 的编号,YY 表示 worker 的编号,u 表示 unbound。
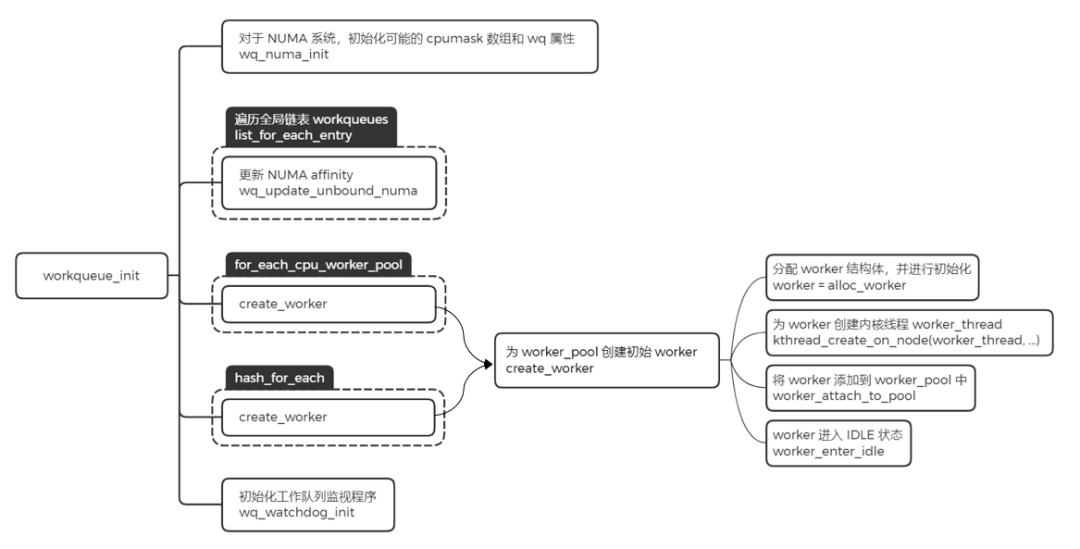
- 分配
worker,并且对该结构中的字段进行初始化操作
- 为
worker 创建内核线程 worker_thread
- 将
worker 添加到 worker_pool 中
worker 进入 IDLE 状态
经过上面两个阶段的初始化,workqueue 子系统基本就已经将数据结构的关联建立好了,当有 work 来进行调度的时候,就可以进行处理了。
使用 workqueue
内核推荐驱动开发者使用默认的 workqueue,而不是新建 workqueue。要使用系统默认的 workqueue,首先需要初始化 work,内核提供了相应的宏 INIT_WORK。
初始化 work
<span>#<span>define</span> INIT_WORK(_work, _func) \<br> __INIT_WORK((_work), (_func), 0)</span>
<span>#<span>define</span> __INIT_WORK(_work, _func, _onstack) \<br> do { \<br> __init_work((_work), _onstack); \<br> (_work)->data = (atomic_long_t) WORK_DATA_INIT(); \<br> INIT_LIST_HEAD(&(_work)->entry); \<br> (_work)->func = (_func); \<br> } while (0)</span>
初始化 work 后,就可以调用 shedule_work 函数把 work 挂入系统默认的 workqueue 中。
work 调度
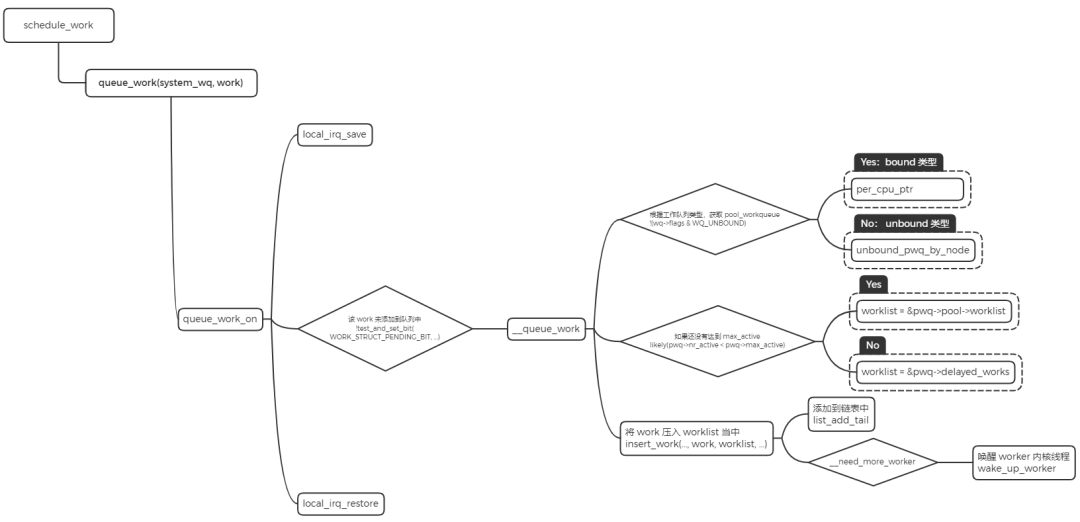
- 将
work 添加到系统的 system_wq 工作队列中。
- 判断 workqueue 的类型,如果是 bound 类型,根据 CPU 来获取
pool_workqueue。如果是 unbound 类型,通过 node 号来获取 pool_workqueue。
- 判断
pool_workqueue 活跃的 work 数量,少于最大限值则将 work 加入到 pool->worklist 中,否则加入到 pwq->delayed_works 链表中。
- 如果
__need_more_worker 判断没有 worker 在执行,则通过 wake_up_worker 唤醒 worker 内核线程。
worker_thread
worker 内核线程的执行函数是 worker_thread。
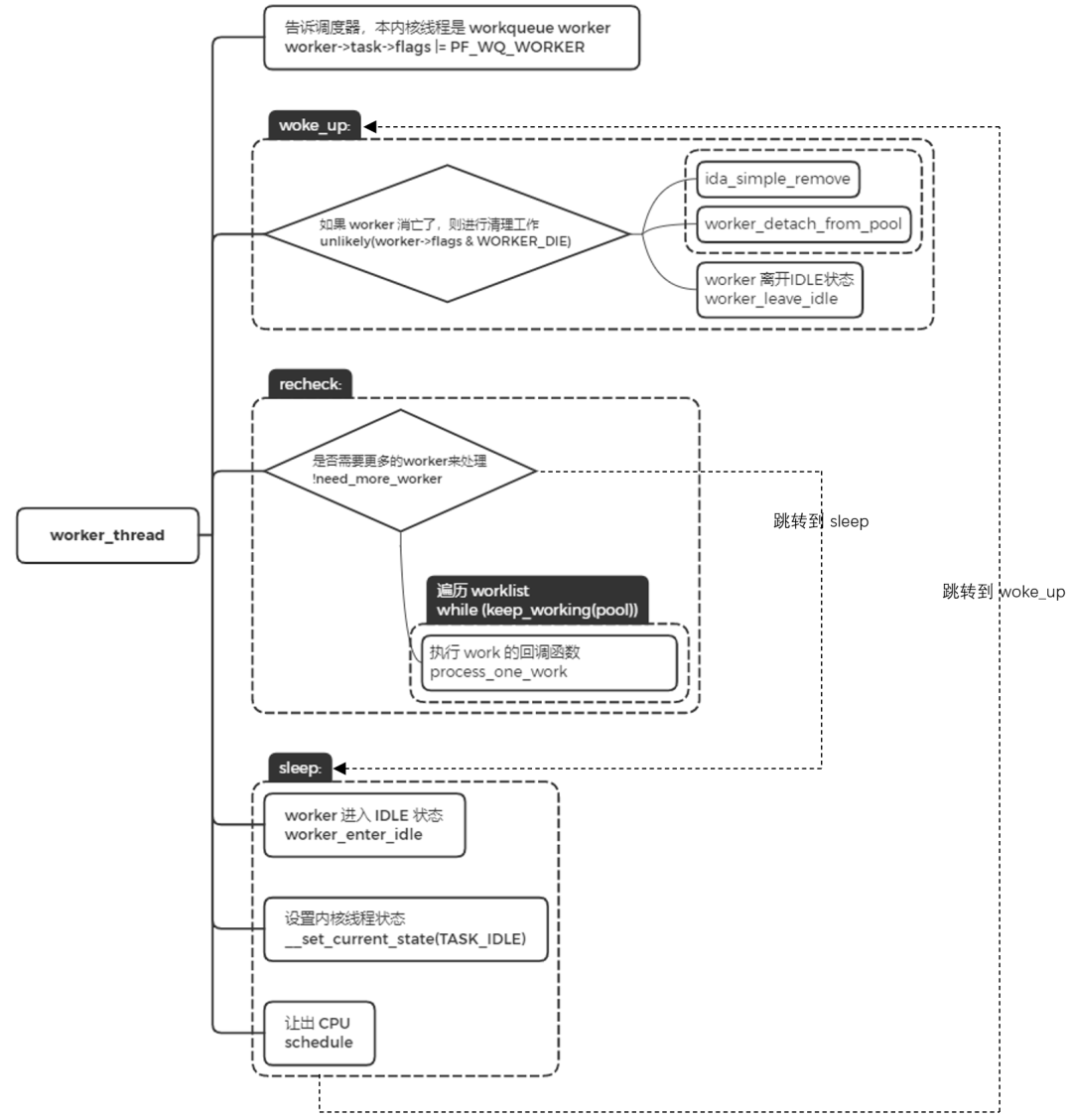
- 设置标志位
PF_WQ_WORKER,调度器在进行调度处理时会对 task 进行判断,针对 workerqueue worker 有特殊的处理。
worker 被唤醒的时候,跳转到 woke_up 执行。woke_up 中,如果此时 worker 是需要销毁的,那就进行清理工作并返回。否则,离开 IDLE 状态,并进入 recheck 模块执行。recheck 中,判断是否需要更多的 worker 来处理,如果没有任务处理,跳转到 sleep 地方进行睡眠。如果有任务需要处理时,遍历工作链表,对链表中的每个节点调用 process_one_work 来执行 work 的回调函数,即 INIT_WORK 里的回调函数。
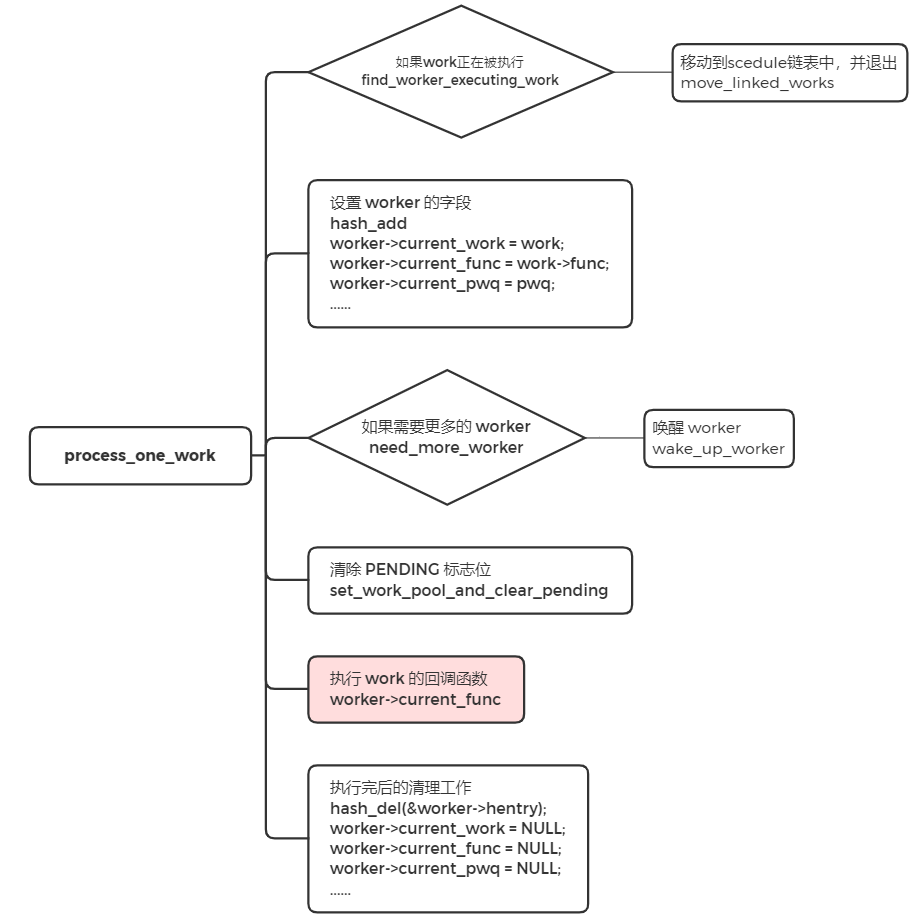
sleep 中,没有任务处理时,worker 进入空闲状态,并将当前的内核线程设置成睡眠状态,让出 CPU。
总结
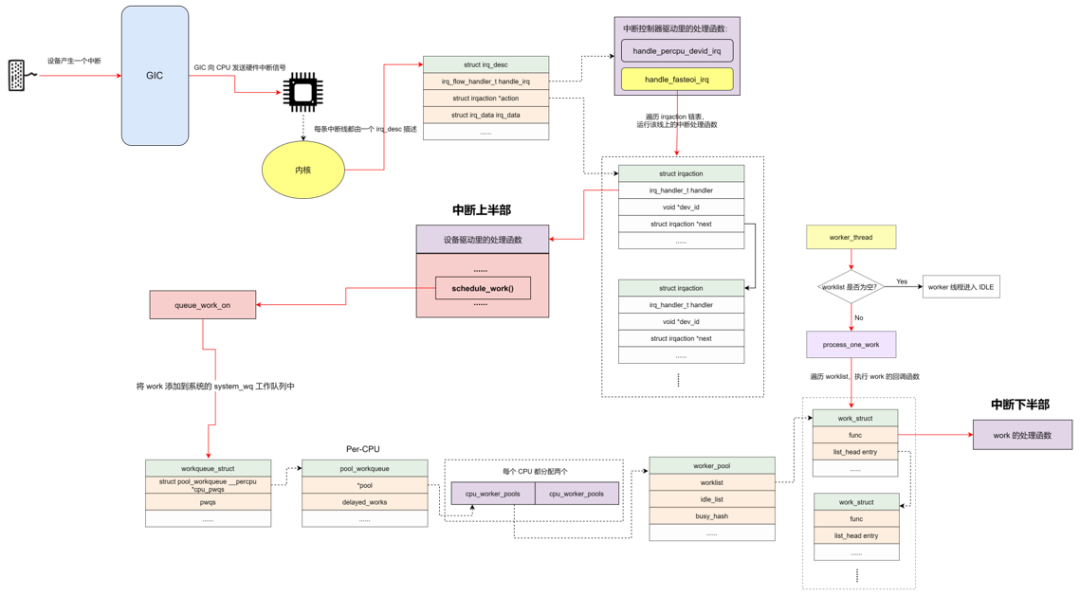
理解 Linux 中断机制和 workqueue 对于深入掌握操作系统内核至关重要。整个过程始于 ARM GICv3 硬件,它负责接收和分发中断信号。Linux 内核通过 irq_domain 等抽象层,将硬件中断号映射为虚拟中断号,并管理着 irq_desc、irqaction 等关键数据结构,最终在异常向量表和中断处理函数的协作下,完成从硬件信号到驱动程序处理函数的调用链。
而 workqueue 作为重要的下半部机制,则巧妙地将中断处理中可能耗时的任务转移到内核线程中异步执行,保证了系统的实时响应能力。它通过 work_struct、worker_pool、worker 等结构,构建了一套高效的任务调度体系。
从 GIC 硬件寄存器操作,到 Linux 内核数据结构的精巧设计,再到中断处理流程的步步为营,整个体系体现了 Linux 内核在应对复杂硬件和性能需求时的卓越设计。希望这篇深度解析能帮助你在云栈社区的交流中,或在自身的内核开发与调试工作中,更透彻地理解中断这一核心机制。
 发表于 2026-4-3 04:11:09
|
查看: 163|
回复: 0
发表于 2026-4-3 04:11:09
|
查看: 163|
回复: 0
