智普人工智能(Z.ai)于2026年4月1日正式推出GLM-5V-Turbo。这款面向高容量智能体工作流优化的原生多模态视觉编码模型(VLM),在视觉语言模型领域迈出了关键一步。它旨在弥合视觉感知与逻辑代码执行之间的鸿沟,直接解决传统模型在图像理解与编程逻辑转换上常见的性能权衡问题。
原生多模态融合:视觉到代码的直接映射
GLM-5V-Turbo的核心创新在于原生多模态融合。与早期系统将视觉与文本处理分离的做法不同,该模型在训练阶段就将图像、视频、设计草图和复杂文档布局等多模态输入直接纳入理解过程。这意味着无需中间文本描述,即可实现“视觉到代码”的直通操作,从而大幅提升模型在复杂界面和多模态场景下的应用能力。
模型的两大技术支撑值得关注:
- CogViT 视觉编码器:负责处理视觉输入,保留空间层次结构和细粒度的视觉细节。这使得模型能够精确理解界面元素、文档布局及图像中的关键信息。
- MTP(多标记预测)架构:优化了推理效率,支持模型在输出长代码序列或导航复杂 GUI 环境时保持高性能。
结合这两项设计,GLM-5V-Turbo 支持200K 上下文窗口,足以处理大量技术文档或长时间的视频录制,同时保持高吞吐量输出。
30+ 任务联合强化学习:平衡视觉与逻辑能力
视觉语言模型常面临一个挑战:“跷跷板”效应——提升视觉识别能力往往会削弱编程逻辑能力。GLM-5V-Turbo 如何解决这一问题?答案是采用30 多个任务的联合强化学习(RL),在训练中同步优化多任务性能。这套方法覆盖了以下几个关键领域:
- STEM 推理:保持坚实的逻辑和数学基础,确保模型能够生成高质量、可执行的代码。
- 视觉落地(Visual Grounding):精准识别界面元素的坐标和属性,为 GUI 操作提供基础。
- 视频分析:理解时间序列变化,便于调试动画或解析用户操作流程。
- 工具使用:允许模型调用外部软件工具和 API,实现更自主的操作。
通过联合强化学习,模型在保持严格编程逻辑能力的同时,显著增强了视觉感知和交互能力。这尤其适用于 GUI 智能体场景,即模型需要“看见”图形界面并生成代码或指令与之交互。
与 OpenClaw 和 Claude Code 的深度集成
GLM-5V-Turbo 并非通用模型,而是针对特定智能体生态进行了深度优化:
- OpenClaw 工作流优化:OpenClaw 是一个用于构建操作图形界面的智能体的开源框架。GLM-5V-Turbo 能够处理设计草图、文档布局,自动化软件环境的部署和操作,实现“感知 → 计划 → 执行”的闭环。
- Claude Code 可视化编码:在 ‘Claw 场景’ 中,开发者只需提供界面截图或功能原型,模型即可基于视觉信息生成代码,确保输出与视觉布局严格匹配。
这种原生多模态理解能力,让模型能够在实际工程工作流中直接应用,从而大幅提升 GUI 代理的智能化水平。
高性能架构与长上下文支持
GLM-5V-Turbo 的技术设计充分考虑了大规模智能体工作流的需求:
- MTP 架构:多标记预测架构优化了推理效率,即便在处理长文档或复杂界面时仍能保持高吞吐量。
- 长上下文窗口:支持 200K 上下文标记和高达 128K 输出标记,适应代码库级任务和长时间视频分析需求。
- 可扩展性:模型能够在复杂环境中执行多步骤任务,同时维持视觉与逻辑能力的平衡。
这些特点确保了 GLM-5V-Turbo 在执行任务时兼具精度、效率与稳定性。
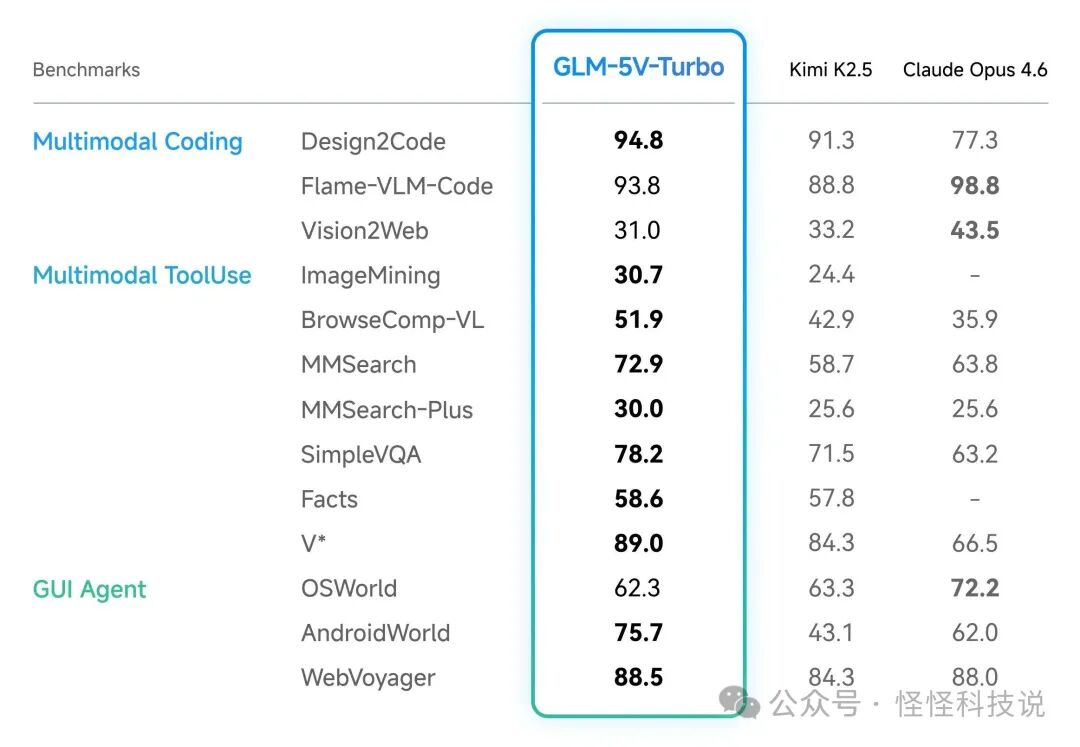
基准测试与应用价值
GLM-5V-Turbo 在多模态编码和工具使用方面经过了严格的基准测试。核心评估指标包括:
| 基准 |
技术聚焦 |
| CC-Bench-V2 |
多模态编码能力,包括前端、后端和代码库任务 |
| ZClawBench |
OpenClaw 智能体场景下的代理交互性能 |
| ClawEval |
多步骤执行与环境操作能力 |
测试结果表明,GLM-5V-Turbo 在处理高精度文档布局和复杂界面操作时,性能达到了当前最先进水平,为企业级应用提供了可靠的技术基础。
应用场景与未来发展
GLM-5V-Turbo 的能力使其适用于多种实际场景:
- 软件开发与测试:自动化生成界面代码、修复 Bug、调试动画。
- 企业文档分析:处理复杂文档布局,提取结构化信息。
- 智能体工作流优化:在 OpenClaw 与 Claude Code 生态中,实现全流程自动化操作。
- 教育与科研:辅助教学、实验操作以及 STEM 领域应用。
未来,多模态视觉编码模型将继续推动智能体从“观察者”向“自主操作者”转变。这将使 AI 不仅能理解视觉信息,还能直接执行高逻辑、高精度的任务,实现真正的跨模态智能。
总结
GLM-5V-Turbo 通过原生多模态融合、联合强化学习、OpenClaw 与 Claude Code 集成,实现了视觉理解与逻辑推理的高效统一。这标志着视觉语言模型在智能体工作流优化上取得了重大突破。
在多模态 AI 发展的大趋势下,原生视觉编码模型将成为未来企业级智能体和自动化工作流的核心支撑,为整个系统带来更高的效率、可靠性和自主性。随着技术不断迭代,类似 GLM-5V-Turbo 的模型将成为连接视觉认知、逻辑推理与代码生成的关键桥梁,推动 AI 在实际工程和生产环境中更广泛地落地。
对多模态AI和智能体技术感兴趣?欢迎来云栈社区交流探讨,获取更多前沿资讯与技术干货。 |  发表于 2026-4-4 05:14:54
|
查看: 228|
回复: 0
发表于 2026-4-4 05:14:54
|
查看: 228|
回复: 0
