在上文Linux内核编译一文中,提到了以下两个用于内核模块编译与安装的命令。这里的“模块”,指的就是Linux内核模块。本文将通过较短的篇幅,带你快速了解Linux内核模块的核心概念。
先用一句话概括:Linux内核模块是一种可以动态加载到内核中的代码,用于扩展或修改内核功能。
make modules # 编译内核模块
make modules_install # 安装内核模块
在正式介绍内核模块之前,我们有必要简要回顾两个核心架构概念:宏内核 (Monolithic Kernel) 和微内核 (Microkernel)。
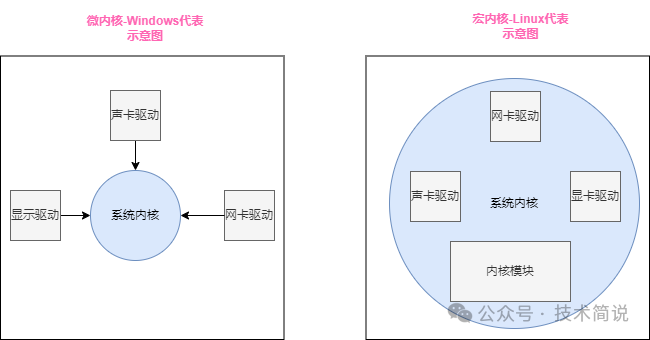
如下图所示,微内核的设计哲学是将最基础的功能(如进程调度、内存管理)保留在内核态,而将驱动等其他功能作为用户态程序实现。这种设计的优势在于,即便某个驱动出现致命错误,也不易导致整个系统崩溃。
而宏内核则将驱动、文件系统、网络协议栈、进程管理、内存管理等所有功能都集成在系统内核内部,运行在内核空间。Linux就是宏内核的典型代表。不过,Linux也吸收了许多微内核的设计思想,内核模块(Loadable Kernel Module, LKM) 便是其中之一。它允许用户根据需要开发和动态插入代码,从而灵活扩展内核功能。
从严谨的视角来看下图的Linux宏内核代表,实际上,Linux内核中的各种驱动,基本上都是以内核模块的形式来实现的。
在Linux内核中,内核模块的存在与加载方式主要分为两种:
- Build-in(内置):编译时直接链接进内核镜像。
- 动态加载:编译为独立模块,在需要时才加载到内核。
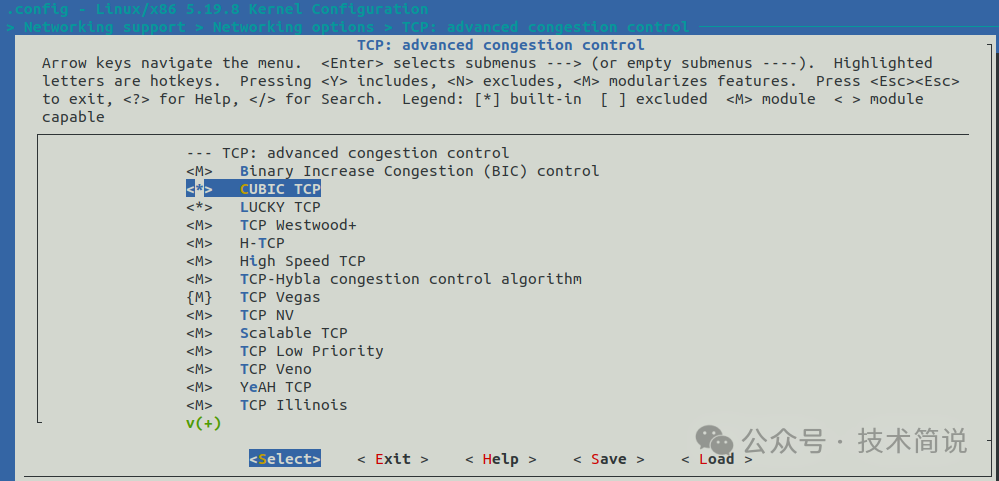
下图是通过 make menuconfig 命令看到的一个网络拥塞控制算法配置界面。注意选项前的符号:有的显示 <M>,有的显示 <*>。这两种符号正对应了上述两种存在方式。
<*> 表示该功能将以 build-in 方式编译,即在内核编译时,该模块的代码会被直接编译并链接到最终的内核映像(如 vmlinux)中,成为内核不可分割的一部分。<M> 则表示该功能将被单独编译成模块,不会链接到 vmlinux 中,后续可以在需要时动态加载。
*需要强调的是,这里的 <M> 或 `<>` 仅是编译内核时的配置选项。即便我们使用一个已经编译好并运行的内核,也仍然可以编写新的内核模块,单独编译并动态插入内核,以实现特定功能。这正是内核模块灵活性的体现。**
Build-in 与动态加载的优劣势对比
了解两种方式后,我们来分析一下它们各自的优缺点。
Build-in 方式的优势与劣势
- 优势:由于模块代码直接集成在内核镜像里,系统启动后即可直接使用其功能,这对于系统启动强依赖的模块(如根文件系统驱动)至关重要。
- 劣势:会导致内核镜像体积臃肿,增加编译时间。而且,一旦需要修改该模块的功能,就必须重新编译整个内核,这在开发和调试阶段效率较低。
动态加载方式的优势与劣势
- 优势:模块独立编译,不增大内核镜像体积;可以按需动态加载和卸载,灵活性极高;功能迭代时只需重新编译模块本身,大大降低了开发和测试成本;不需要时可以卸载,节省系统资源。
- 劣势:带来了额外的复杂性问题,例如模块依赖管理。更重要的是,动态加载也可能引入安全与稳定风险——在稳定运行的系统上插入一个有缺陷甚至恶意的模块,可能导致系统崩溃。
扩展思考:动态模块的编写与管理
那么,动态加载的内核模块具体如何编写和加载?在内核编译过程中已经编译好的模块,又是在何时、以何种方式被自动加载到运行中的内核的呢?系统启动过程中如何确保重要驱动被自动加载?模块间的依赖关系又如何解决?
本文将作为Linux内核模块的入门简介,主要厘清其基本概念与两种存在方式。上述更深入的问题,我们将在后续的文章中继续探讨。欢迎在云栈社区交流你的想法与疑问。 |  发表于 2026-4-4 10:39:24
|
查看: 168|
回复: 0
发表于 2026-4-4 10:39:24
|
查看: 168|
回复: 0
