原文链接: https://claude.com/blog/harnessing-claudes-intelligence
作者: Lance Martin
译者: 倔强青铜三
Anthropic的联合创始人之一Chris Olah曾表示,像Claude这样的生成式AI系统更像是“生长”出来的,而非“构建”出来的。研究人员通过设定条件引导其生长,但最终涌现的能力或结构并不总是可预测的。
这就给基于Claude的开发带来了一个挑战:Agent harnesses(代理框架) 通常编码了关于Claude无法独立完成某些任务的假设。但随着Claude本身能力的飞速进化,这些假设可能会很快过时。即使是本文将要分享的经验,也需要被开发者们经常性地重新审视。
下面,我们将介绍三种实用的设计模式,它们可以帮助开发团队构建出既能跟上Claude智能进化步伐,又能在延迟和成本之间取得平衡的应用程序。这三种模式的核心在于:利用Claude已知的知识、不断追问“我可以停止做什么?”,以及谨慎地为Agent harness设置边界。
1. 使用Claude已知的知识
我们建议优先使用Claude已经熟练掌握的工具来构建应用程序。
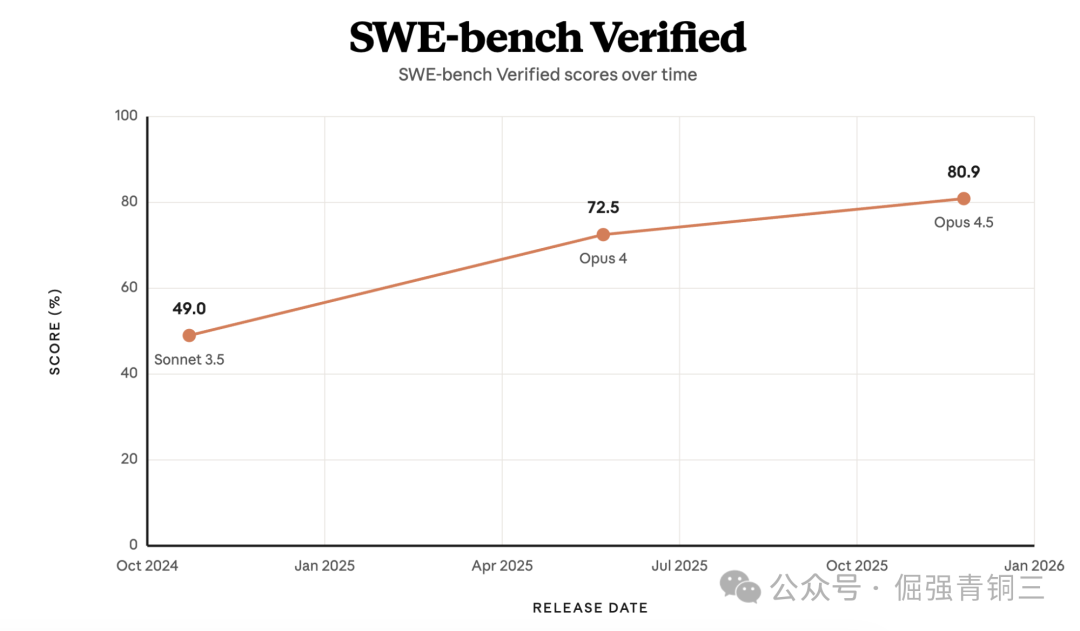
一个有力的证据是:在2024年末,Claude 3.5 Sonnet仅凭bash tool和text editor tool(用于查看、创建和编辑文件),就在SWE-bench Verified基准测试中达到了49%的得分,这在当时是最佳水平。Claude Code正是构建在这些相同的基础工具之上。Bash本身并非为构建Agent而设计,但它是一个Claude知道如何使用,并且会随着时间的推移越来越擅长的通用工具。
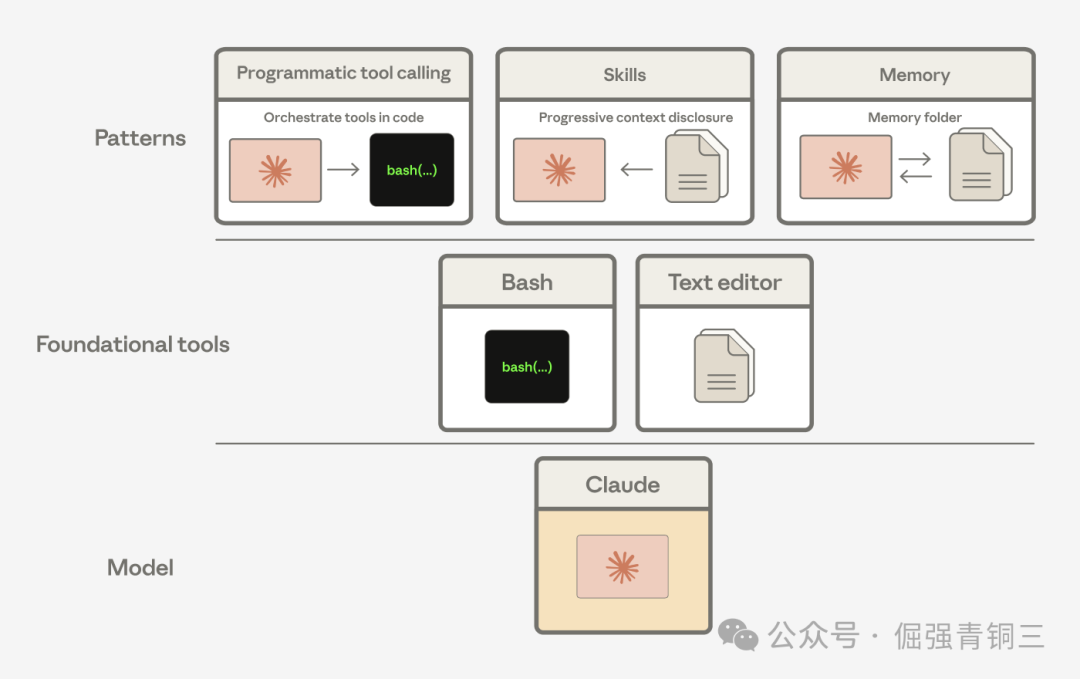
我们已经观察到Claude能够将这些通用工具组合起来,形成解决特定问题的模式。例如,Agent Skills、程序化工具调用和记忆工具,本质上都是由bash和text editor这两种基础工具构建而成的。
2. 询问“我可以停止做什么?”
Agent harness通常编码了关于Claude能力的假设。随着Claude变得更强大,我们应该重新测试这些假设,将更多的自主权交还给模型。
让Claude自主编排其行动
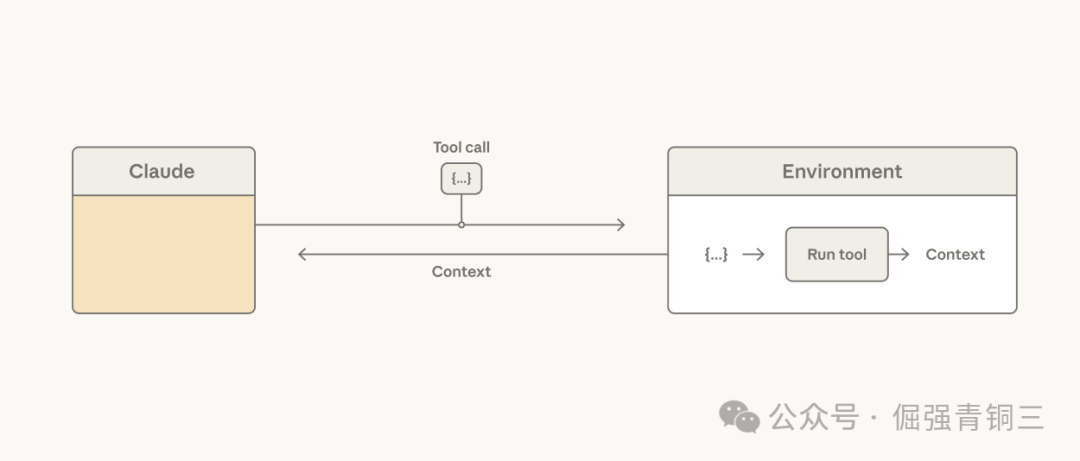
一个常见的假设是:每个工具的执行结果都应该流经Claude的上下文窗口,以决定下一个动作。这种做法在Token成本上可能很昂贵,并且如果结果只需要传递给下一个工具,或者Claude只关心输出的一小部分,那就显得没有必要。
考虑一个场景:需要读取一张大表来对某一列进行推理。传统方式下,整张表都会进入上下文,Claude需要为每一行不必要的数据支付Token成本。虽然可以通过硬编码过滤器的工具设计来解决,但这并没有触及问题的核心——Agent harness正在替Claude做出本应由它自己做出的编排决策。
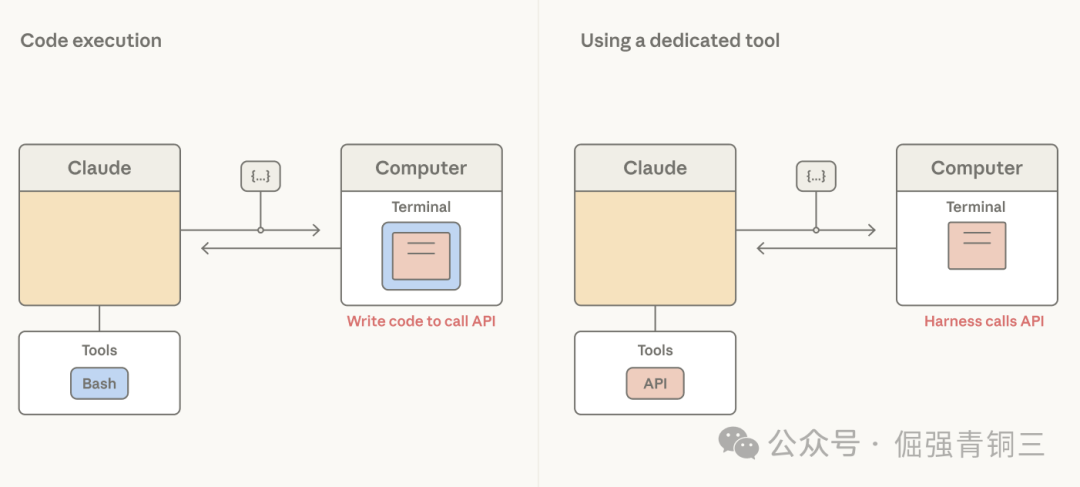
提供一个代码执行工具(如bash tool或特定语言的REPL)可以很好地解决这个问题。它允许Claude编写代码来表达工具调用之间的逻辑。Agent harness不再决定每个工具结果都必须以Token形式处理,而是让Claude自己决定哪些结果需要传递、过滤或管道传输到下一个调用,而无需经过上下文窗口。只有代码执行的最终输出才会进入Claude的上下文。
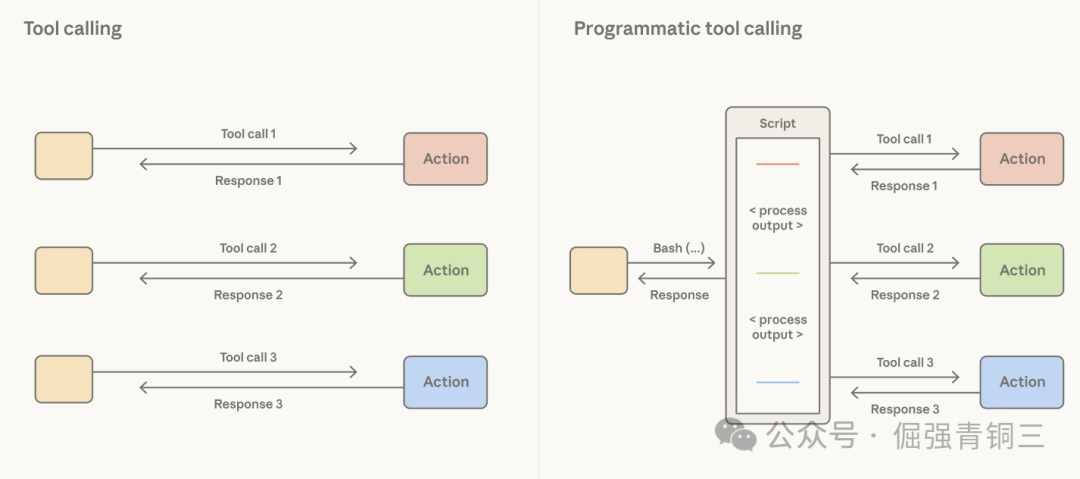
这样一来,编排决策就从harness转移到了模型。由于代码是Claude编排行动的通用方式,一个强大的编码模型也就成为了一个强大的通用代理。Claude利用这种模式在非编码评估中也表现出色:在BrowseComp(一个测试Agent网页浏览能力的基准)上,赋予Opus 4.6过滤自身工具输出的能力,将其准确率从45.3%提升到了61.6%。
让Claude管理自己的上下文
另一个常见的假设是:系统提示应该被手工制作成包含所有任务特定指令。问题在于,预先加载大量提示指令难以扩展——添加的每个Token都会消耗Claude的注意力预算,而预先加载很少用到的指令是一种浪费。
赋予Claude访问Skills的能力可以解决此问题。每个Skill的YAML frontmatter是一个简短描述,会被预加载到上下文窗口中,提供Skill内容的概览。如果任务需要,Claude可以通过调用read file tool来逐步披露完整的Skill内容。
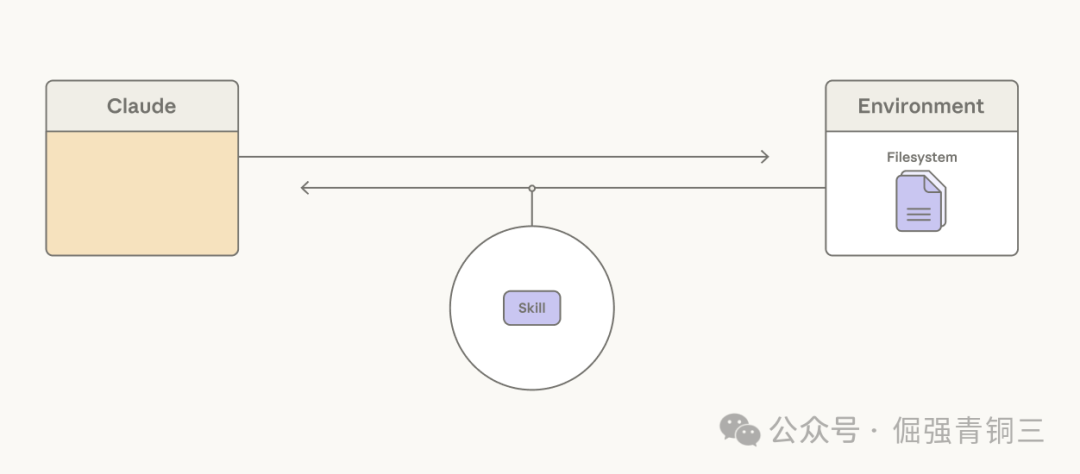
虽然Skills让Claude可以自由组合自己的上下文窗口,但上下文编辑则提供了相反的操作——选择性地删除那些已经过时或无关的上下文,例如旧的工具结果或思考过程。
此外,通过子代理(subagents),Claude在判断何时分叉到新的上下文窗口以隔离特定任务方面也变得越来越好。在Opus 4.6中,生成子代理的能力将BrowseComp的结果比最佳单代理运行提高了2.8%。
让Claude持久化自己的上下文
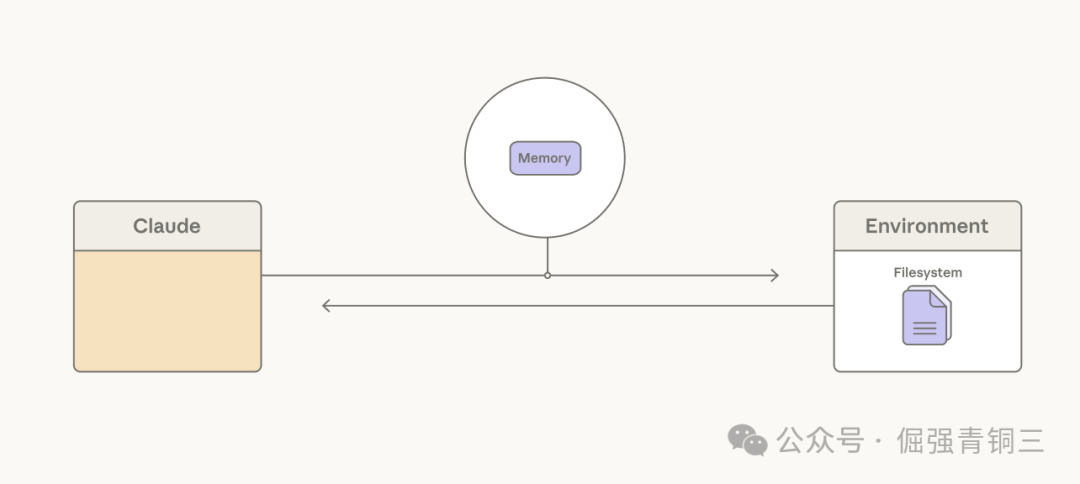
长时间运行的Agent可能会超出单个上下文窗口的限制。常见的假设是依赖模型外部的检索基础设施来构建记忆系统。而我们的许多工作则聚焦于为Claude提供简单的方法,让它自己选择要持久化哪些内容。
例如,Compaction让Claude能够总结其过去的上下文,以便在长期任务中保持连续性。在几个模型版本迭代中,Claude在选择记住什么方面变得越来越好。在BrowseComp上,Sonnet 4.5无论给予多少压缩预算,准确率都保持在43%。然而Opus 4.5提升到了68%,而Opus 4.6在相同设置下达到了84%。
Memory folder是另一种方法,它允许Claude将上下文写入文件,然后在需要时读取。我们看到Claude将此用于Agent式搜索。在BrowseComp-Plus上,为Sonnet 4.5提供一个memory folder将其准确率从60.4%提高到了67.2%。
长期运行的场景,例如玩《宝可梦》游戏,是Claude改进使用memory folder能力的一个有趣例子。Sonnet 3.5将记忆视为“转录本”,记录非玩家角色说的话,而非真正重要的事情。在14,000步之后,它创建了31个文件——包括两个关于毛毛虫宝可梦的近乎重复的文件——并且仍然停留在第二个城镇:
caterpie_weedle_info:
- Caterpie和Weedle都是毛毛虫宝可梦。
- Caterpie是没有毒的毛毛虫宝可梦。
- Weedle是有毒的毛毛虫宝可梦。
- 此信息对未来的遭遇和战斗至关重要。
- 如果我们的宝可梦中毒了,我们应该尽快前往宝可梦中心治疗。
而后续的模型则学会了编写战术笔记。Opus 4.6在相同的步数下,只有10个被组织到目录中的文件,获得了三个道馆徽章,并且有一个从自己失败中提炼的学习文件:
/gameplay/learnings.md:
- Bellsprout Sleep+Wrap combo:在Sleep Powder落地前用BITE快速KO。不要让它设置!
- Gen 1 Bag Limit: 最多20个物品。在地牢前丢弃不需要的TMs。
- Spin tile mazes: 不同的入口y位置会通向不同的目的地。尝试所有入口并穿过多个口袋。
- B1F y=16 wall 在所有x=9-28处确认坚固(步骤14557)
这种从记录琐事到提炼策略的转变,清晰地展示了模型在自主上下文管理能力上的进化。关于如何设计高效的Skills,可以参考云栈社区的技术文档板块,那里有更多关于架构设计和最佳实践的讨论。
3. 谨慎设置边界
Agent harness提供了围绕Claude的结构,用以强制执行用户体验、成本控制或安全策略。
设计上下文以最大化缓存命中
Claude Messages API是无状态的。Claude无法看到前几轮的对话历史。这意味着Agent harness需要在每一轮中将新的上下文与所有过去的行动、工具描述和指令一起打包发送给Claude。
提示可以基于设置的断点进行缓存。换句话说,Claude API将上下文写入缓存直到断点,并检查该上下文是否匹配任何先前的缓存条目。
由于缓存的Token成本仅为原始输入Token的10%,以下是在Agent harness中帮助最大化缓存命中率的一些原则:
| 原则 |
描述 |
| 静态优先,动态在后 |
对请求内容进行排序,将稳定的内容(系统提示、工具描述)放在前面。 |
| 使用消息进行更新 |
在消息中附加 <system-reminder> 标签来更新提示,而不是直接编辑原始提示。 |
| 不要切换模型 |
避免在会话期间切换模型。缓存是模型特定的;切换会使其失效。如果需要更便宜的模型,请使用子代理。 |
| 仔细管理工具 |
工具位于缓存的前缀中。添加或删除工具会使缓存失效。对于动态工具发现,使用 tool search,它可以在不破坏缓存的情况下追加工具。 |
| 更新断点 |
对于多轮应用程序(如Agent),将断点移动到最新的消息以保持缓存新鲜度。使用 auto-caching 功能来实现这一点。 |
为UX、可观察性或安全边界使用声明式工具
Claude不一定知晓应用程序的安全边界或UX设计。Claude发出工具调用,由harness来处理。Bash tool赋予Claude广泛的编程杠杆来执行操作,但它只给harness返回一个命令字符串——每个操作的“形状”都相同。
将操作提升为专用工具,则给了harness一个特定于该操作的钩子,它具有类型化的参数,可以用于拦截、门控、渲染或审计。
需要安全边界的操作是专用工具的自然候选者。可逆性通常是一个好的判断标准:难以逆转的操作(如调用外部API)可以通过用户确认来加以控制。写入工具(如edit)可以包含陈旧性检查,以防止Claude覆盖自上次读取以来已更改的文件。
当操作需要呈现给用户时,工具也很有用。例如,它们可以呈现为对话框,向用户清晰展示问题、提供多个选项,或者阻止Agent循环直到用户提供反馈。
最后,工具对于可观察性很有价值。当操作是类型化的工具时,harness获得了可以记录、跟踪和重放的结构化参数。
当然,是否将某个操作提升为工具的决定应该不断重新评估。例如,Claude Code的“auto-mode”(在发布时处于研究模式)为bash tool本身提供了一个安全边界:它使用第二个Claude实例来读取命令字符串并判断其安全性。这种模式可以减少对专用工具的需求,并且只应用于用户总体信任Agent方向的任务。专用工具仍然在某些高风险操作中占有一席之地。
展望未来
Claude智能的前沿始终在快速变化。关于Claude“无法”做什么的假设,需要在其能力的每一次阶梯式提升中被重新测试。
我们看到这种模式在不断重演。在我们为长期任务构建的Agent中,Sonnet 4.5在感知到上下文限制接近时会过早结束任务。我们当时添加了“上下文重置”功能来清除上下文窗口,以解决这种“上下文焦虑”。而在Opus 4.5中,这种行为消失了。我们为补偿而构建的上下文重置功能,反而成了Agent harness中的“死重”。
及时删除这些“死重”至关重要,因为它们可能成为Claude性能的瓶颈。随着时间推移,我们应用程序中的结构或边界都应该围绕这个问题进行修剪:我可以停止做什么?
要实践本文讨论的所有工具和模式,可以参考Anthropic官方的claude-api skill。
Claude等人工智能模型的快速进化,要求开发者的框架设计思路也必须保持灵活和前瞻。在不断将更多自主权交还给模型的同时,审慎地设置那些真正必要的安全与用户体验边界,是构建下一代AI应用的关键。如果你想了解更多前沿的AI开发实践,欢迎来云栈社区与更多开发者交流。
 发表于 2026-4-5 01:41:37
|
查看: 113|
回复: 0
发表于 2026-4-5 01:41:37
|
查看: 113|
回复: 0
