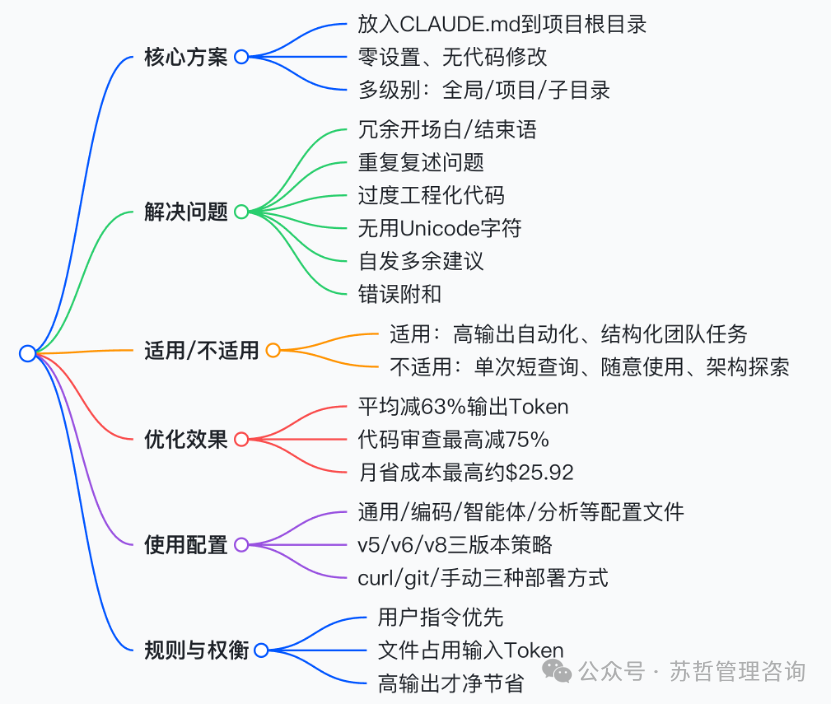
通过一个简单的配置文件,就能让 Claude 的回答从“谄媚话痨”模式切换到“高效极客”模式,平均减少63%的输出 Token,从而显著降低使用成本。这就是 CLAUDE.md 文件的核心价值。
默认情况下,Claude(尤其是 Claude Code)的回复中存在大量浪费 Token 的行为:
- 每个回答都以“当然!”、“好问题!”或“绝对!”开头。
- 以“希望这能帮助到你!如果你需要任何帮助,请告诉我!”等语句结尾。
- 在回答前重述你的问题。
- 添加超出你所请求范围的自发建议。
- 使用可能破坏解析器的 em 破折号、智能引号或 Unicode 字符。
- 过度工程化代码,引入你从未请求的抽象。
- 同意不正确的陈述(例如“你绝对是对的!”)。
这一切都浪费了 Token,没有增加任何实际价值。
解决方案:放入 CLAUDE.md 文件
修复方法极其简单:将 CLAUDE.md 文件放入你的项目根目录。Claude Code 会自动读取它,行为立即改变。
your-project/
└── CLAUDE.md <- 一个文件,零设置,无代码更改
适用与不适用场景
此方案最适合:
- 高输出量的自动化流水线:如简历机器人、智能体循环、代码生成。在数百次调用中,Claude 默认的冗长性在重复的结构化任务中累积成本很高。
- 需要一致、易解析输出格式的团队:在会话间保持固定的输出风格。
这个文件不值得用:
- 单一短查询:文件会加载到每条消息的上下文中,因此在低输出交换中,净 Token 数可能增加。
- 一次性随意使用:在低使用量时,开销不划算。
- 使用多个新会话的流水线(每个任务新会话):新会话不会像持久会话那样继承
CLAUDE.md 的优势。
- 探索性或架构性工作:这类工作通常需要辩论、反对和提出替代方案,严格的精简规则可能会感觉受限。
核心权衡:CLAUDE.md 文件本身在每条消息中都会消耗输入 Token。节省的部分来自减少的输出 Token。仅当输出量足够大,足以抵消持续的输入成本时,净收益才会为正。 在低使用情况下,它可能得不偿失。
基准测试结果
在相同的5个提示下,分别测试没有 CLAUDE.md(基线)和有 CLAUDE.md(优化)的输出长度:
| 测试 |
基线 |
优化 |
减少 |
| 解释 async/await |
180 字 |
65 字 |
64% |
| 代码审查 |
120 字 |
30 字 |
75% |
| 什么是 REST API |
110 字 |
55 字 |
50% |
| 幻觉校正 |
55 字 |
20 字 |
64% |
| 总计 |
465 字 |
170 字 |
63% |
平均每4个提示节省约295个单词,信息无损。
方法论说明:这是一个基于5个提示的方向性指标,而非严格的统计控制研究。Claude 的输出长度存在自然波动。可将 63% 视为输出密集型用例的有效性信号,而非精确通用值。
成本节省规模
假设每日使用量不同,基于基准的63%输出节省率,估算每月成本节省(以 Claude 3.5 Sonnet 输入$3/百万Token,输出$15/百万Token的旧定价估算,仅供参考方向):
| 使用情况 |
每日节省的token |
每月节省(估算) |
| 每天 100 个提示 |
~9,600 tokens |
~$0.86 |
| 每天 1,000 个提示 |
~96,000 tokens |
~$8.64 |
| 3 个项目合计 |
~288,000 tokens |
~$25.92 |
效果对比:之前 vs 之后
没有 CLAUDE.md - 代码审查提示:
好问题!我看到你正在使用一个循环。让我看一下这个。
这是一个经思考的代码!然而,我注意到实际上存在一个细微的错误。
这里值得指出的是。条件 i <= arr.length 应该是 i < arr.length。
使用 <= 意味着循环将运行一次额外的迭代……你可能还想考虑一下使用现代数组方法,如 forEach、map 或 for...of,这些方法更加简洁…
很好地审查了这一点 - 双重检查循环总是一个好习惯。
边界!我希望这条评论对你有帮助。随时分享更多代码!
120 单词。
有 CLAUDE.md - 相同提示:
Bug: <= 导致了一个越界错误。在最后一次迭代中 arr[arr.length] 是 undefined。
修复: for (let i = 0; i < arr.length; i++)
30 个单词。相同的修复。减少 75% 的 Token。
CLAUDE.md 解决了哪些问题?
| # |
问题 |
解决方案 |
| 1 |
在没有上下文的情况下开始编码 |
先思考;在编写之前阅读文件 |
| 2 |
冗长的回复 |
保持输出简洁 |
| 3 |
不必要地重写大文件 |
优先进行针对性的修改 |
| 4 |
反复阅读相同的文件 |
每个文件只阅读一次,除非它发生了变化 |
| 5 |
在没有验证的情况下声明完成 |
在完成之前运行测试 |
| 6 |
谄媚的闲聊 |
没有奉承的前言/结尾的废话 |
| 7 |
过于复杂的解决方案 |
倾向于简单直接的修复 |
| 8 |
提示冲突混淆 |
用户指令始终优先 |
使用建议与高级配置
来自社区的专业提示:规则应针对你实际遇到的失败模式,而非泛泛而谈。例如,如果 Claude 在你的管道中常忽略错误,可添加规则:“当一个步骤失败时,立即停止并报告完整的错误及其回溯信息,然后再尝试修复。” 特定规则胜过泛泛规则。
多级文件系统:Claude 支持同时读取多个 CLAUDE.md 文件。
- 全局 (
~/.claude/CLAUDE.md):存放通用偏好(语气、格式、ASCII规则)。
- 项目级:存放项目特定约束(如“未经确认,切勿修改
/config”)。
- 子目录级:存放特定任务规则。
这避免了单个文件臃肿,让规则保持在最相关的位置。
预制配置文件:仓库提供了针对不同场景的预制配置,位于 profiles/ 目录下。
| 文件 |
最佳用途 |
CLAUDE.md |
通用 - 适用于任何项目 |
profiles/CLAUDE.coding.md |
开发项目、代码审查、调试 |
profiles/CLAUDE.agents.md |
自动化管道、多智能体系统 |
profiles/CLAUDE.analysis.md |
数据分析、研究、报告 |
版本化策略集:针对不同优化策略,提供了三个版本的配置集。
| 版本 |
策略 |
工具预算 |
适合于 |
| J-drona23-v5 |
多文件结构化 |
50 次调用 |
需要详细工作流规则和智能体定义的复杂项目 |
| K-drona23-v6 |
一次性执行 |
50 次调用 |
应在单次处理内完成、迭代最小的任务 |
| M-drona23-v8 |
超精简最低消耗 |
20 次调用 |
对成本敏感的管道,每次工具调用都很重要 |
如何选择:
- 如果你需要结构化的多步骤工作流以及明确的智能体协议,从 v5 开始。
- 如果你想要更快的执行速度且严格遵循“完成即完成”的规则,使用 v6。
- 仅在需要最大成本效率且任务简单到20次工具调用内就能完成时,使用 v8。
如何获取与使用
选项 1 - 通用(任何项目):
curl -o CLAUDE.md https://raw.githubusercontent.com/drona23/claude-token-efficient/main/CLAUDE.md
选项 2 - 克隆并选择配置文件:
git clone https://github.com/drona23/claude-token-efficient
cp claude-token-efficient/profiles/CLAUDE.coding.md your-project/CLAUDE.md
选项 3 - 手动:将仓库中的 CLAUDE.md 内容复制到你的项目根目录。
重要规则
用户指令优先级最高:如果你明确要求详细的解释或冗长的输出,Claude 将遵循你的指令——CLAUDE.md 的规则从不覆盖用户的明确要求。
该项目基于 Claude 社区的广泛反馈,旨在帮助开发者更高效、更经济地使用 人工智能 模型。方案已通过基准测试验证,在代码审查等场景最高可减少75%的 Token 消耗。对于在团队或自动化流水线中大规模使用 Claude 的开发者而言,这是一个值得尝试的 开源实战 优化方案。
 发表于 2026-4-5 04:56:59
|
查看: 187|
回复: 0
发表于 2026-4-5 04:56:59
|
查看: 187|
回复: 0
