过去一年,许多研究者和工程师都在探索SpeechLLM。然而,一个经常被忽视却至关重要的问题是:为什么离散语音Token这条技术路线,理论设计看起来很优雅,但在实际应用和训练中却常常表现出不稳定、难收敛和泛化能力差的问题?
近期一篇名为《StableToken》的论文给出了一个关键且颇具启发性的解释:问题的根源可能不完全在于下游模型的训练能力,而在于提供给模型的“语义Token”本身就缺乏稳定性。
更具体地说,研究人员发现:即使在语音信号中混入一些人耳几乎无法察觉的轻微噪声,经过语义分词器后得到的Token序列也会发生显著变化。这意味着,对于下游的大型语言模型(LLM)来说,它所接收到的“离散语义输入”并不稳定。同一句对人类而言语义清晰的话语,在模型看来却可能像是完全不同的编码序列。要求模型在这种不稳定的输入上实现鲁棒学习,其难度可想而知。
一、核心发现:语义Token对微扰极其敏感
论文首先指出了一个关键现象:在信噪比(SNR)仍然较高、语音内容对人类听感依然清晰可懂的条件下,许多主流语义分词器输出的Token序列已经发生了显著改变。这种变化并非由语义内容本身的变化引起,而仅仅源于微小的“声学扰动”。
为了量化这种不稳定性,论文引入了Unit Edit Distance(UED)指标:
- 对同一句语音,人为添加轻微噪声。
- 如果分词器足够稳定,它对原始语音和带噪语音应输出高度一致的Token序列(UED值低)。
- 反之,如果分词器很脆弱,其输出序列会发生频繁的、无规律的改写(UED值高)。
实验结果表明,许多现有方法在人类感知几乎不变的情况下,UED值依然很高。这清晰地将问题定位到了上游:离散Token路线难学好的一个核心原因,可能并不完全是下游Transformer模型的能力不足,而是作为其输入的Token表示本身就在“抖动”,这无形中破坏了训练数据的一致性。
二、根因剖析:单路径量化与训练目标的局限性
论文将Token不稳定的原因归结为两大结构性因素:
1. 单路径量化结构的内在脆弱性
传统的语义分词器通常采用单一路径进行编码和量化。这种结构对输入扰动非常敏感:一旦输入的连续特征发生微小变化,触及了量化边界的阈值,就会导致输出的离散Token ID发生跳变。离散化过程本身固有的“阈值效应”放大了这种脆弱性。
2. 训练目标忽略了中间表示的稳定性
大多数系统的优化目标主要集中于最终的语音重建或生成质量,缺乏对“中间层语义Token在轻微扰动下应保持一致性”的直接约束。因此,模型可能在整体评测指标上表现尚可,但在Token层面依然十分脆弱。
这也解释了工程实践中常见的困惑:波形听起来差不多,语义理解也没有大的偏差,但Token序列却像是在“随机改写”,导致下游模型训练过程充满不确定性。
三、StableToken的解决方案:将“共识”机制融入Token生成
论文最核心的贡献并非设计一个更庞大的编码器,而是引入了一种多分支+位级投票的共识机制。
其核心思想可以理解为:
- 摒弃单一决策路径,避免“一票否决”。
- 利用多条并行的表示分支各自独立地生成对Token的判断。
- 最终通过位级(bit-wise)多数投票机制,聚合出一个更稳定、更鲁棒的Token序列。
这非常类似于工程中的冗余与容错设计思路:当单个模块容易受到干扰时,就引入多个模块进行集体决策以抵抗噪声。
模型架构图
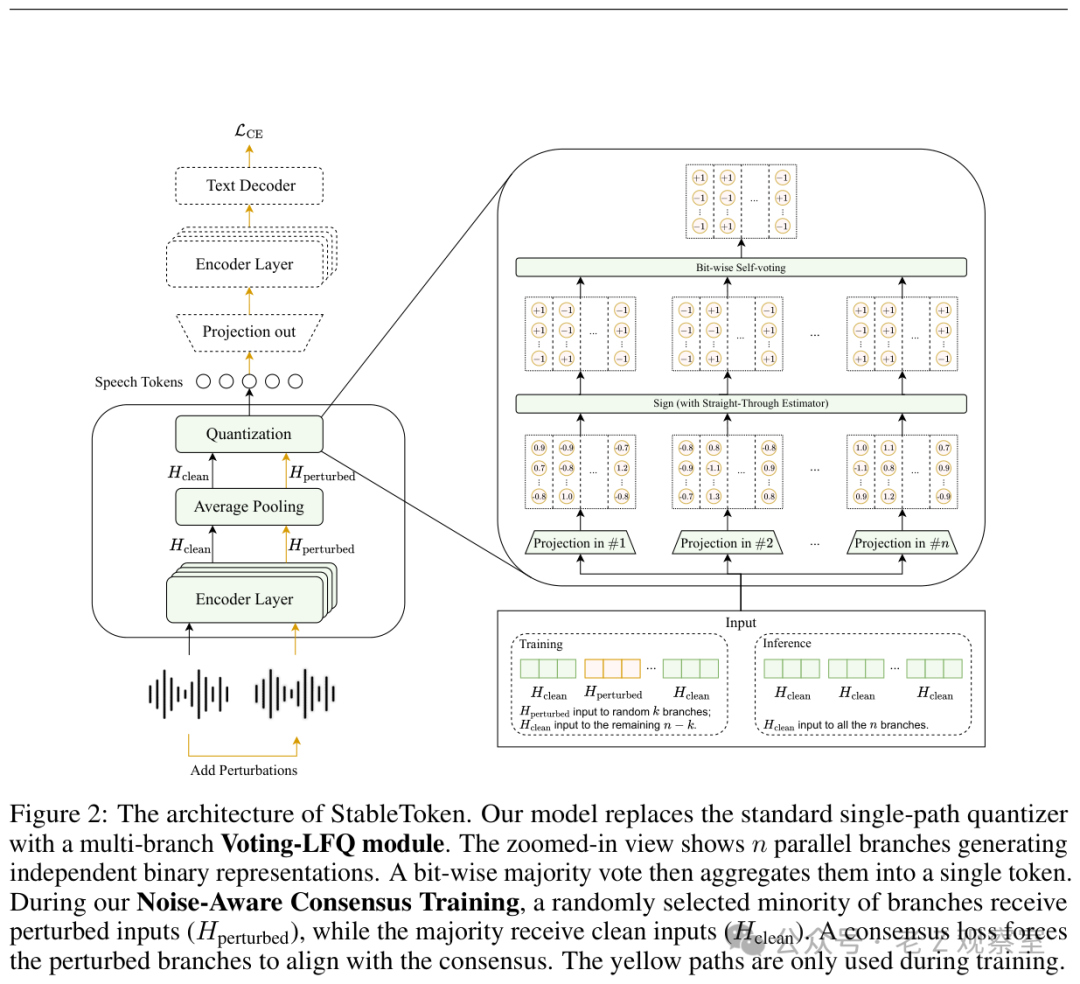
从方法论角度看,这个方向值得重视:它没有回避离散化过程的固有脆弱性,而是正视这一问题,并采用结构性冗余的设计思路来抵消其影响。相比寄希望于编码器自发地学会鲁棒性,这种方法更加可控和可解释。
四、实验结果验证了什么?
论文的实验设计思路清晰,层层递进:
- 首先比较不同分词器在噪声下的稳定性(UED指标)。
- 进而验证这种稳定性的提升是否能切实改善下游SpeechLLM任务的性能。
1. Token稳定性显著提升
在多种噪声类型(高斯、粉红、棕色噪声等)和不同强度下,StableToken的UED值均显著低于基线方法。这表明其在“将同一句话在轻微扰动下编码为相似Token序列”的能力上更强,离散数学中的编码稳定性得到了体现。
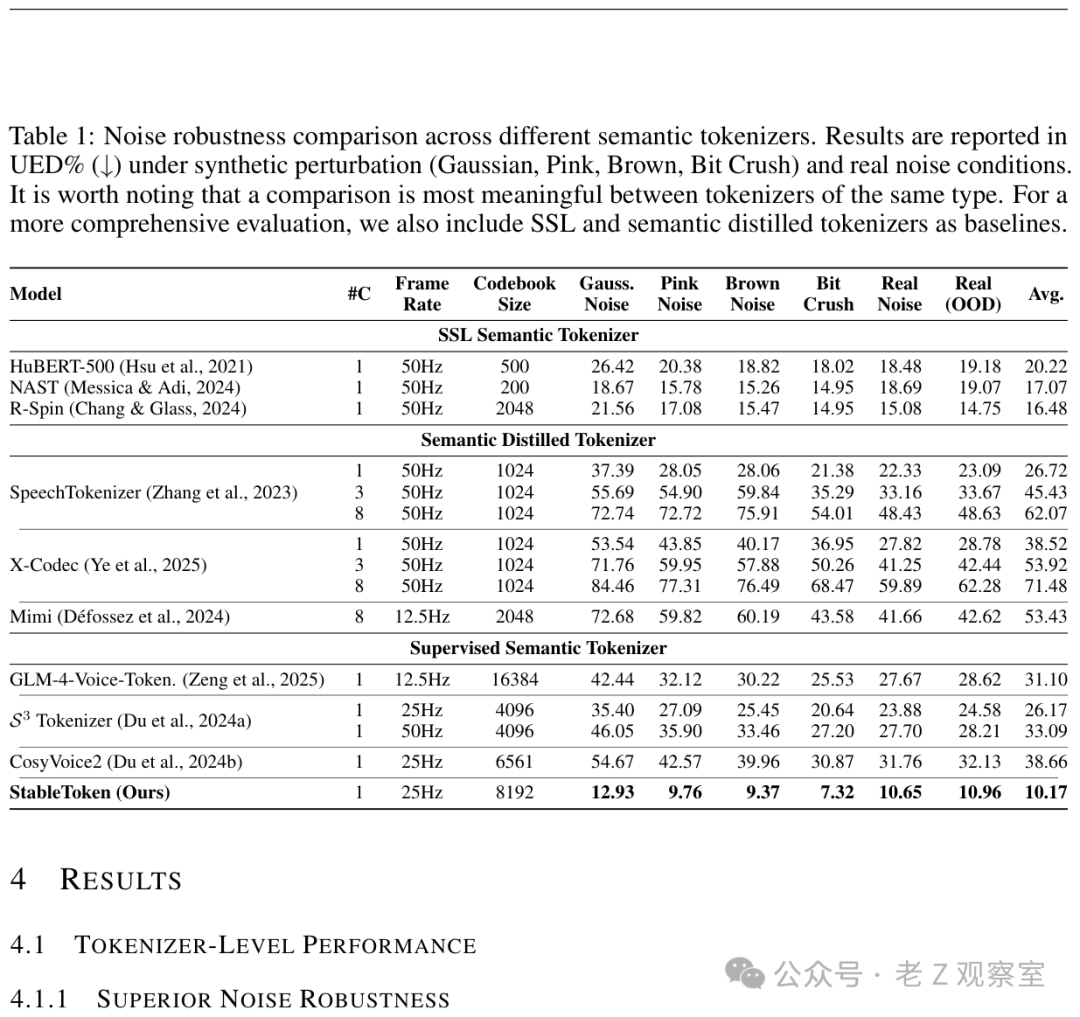
2. 下游任务鲁棒性同步改善
更重要的是,这种收益并非停留在分词器的“自嗨”指标上。论文在下游的语音理解和生成任务中也观察到了明显的性能提升:
- 在带噪环境下,语音识别、情感识别等任务的性能更稳定。
- 模型整体对输入扰动的敏感性显著降低。

这一发现至关重要,因为它证明了:Token的稳定性并非一个“好看但无用”的中间指标,它直接且显著地影响着终端应用的效果。
五、研究的深层价值:将“玄学”问题变为可优化工程
笔者认为,这篇论文最大的价值在于,它将一个长期困扰业界的、有些“玄学”色彩的现象,转变为了一个可测量、可解释、可系统化优化的问题:
- 过去,大家都知道离散Token经常不稳定,但难以精确定位和描述问题根源。
- 现在,可以利用UED这类指标直接量化“输入轻微扰动导致Token改写”的程度。
- 进而,可以围绕“提升稳定性”这一明确目标进行模型结构和训练目标的针对性设计。
这对整个SpeechLLM技术路线具有长期影响,因为它修正了一个潜在的默认假设:过去可能认为“只要语义表征足够强大,分词器就能用”;现在必须加上一条——“语义强大还不够,其输出的Token序列还必须具备足够的稳定性”。
六、回到根本问题:为什么离散Token难学好?
用这篇论文的结论可以概括为:离散特征路线学习困难,很多时候并非“LLM能力不行”,而是“前端Token生成模块抖动过于剧烈”。
你提供给模型的训练样本,在宏观数据分布上看似相同,但在微观的Token表示层已经发生了隐式漂移。模型被迫在一个不断“变形”的输入空间中进行学习,自然更难以收敛,泛化能力也更差。
这也解释了许多工程实践中的现象:在干净的实验室数据上表现良好,一旦部署到真实嘈杂场景中性能就大幅下降;长时间调参仿佛在“打补丁”,收效甚微。因为问题的根源在表示层,若不先解决Token的稳定性问题,下游模型再强大也始终在负重前行。
七、总结与展望:一个基础而关键的方向
这项工作至少有三层重要意义:
- 将经验性“玄学”转化为可量化指标(通过UED等度量)。
- 将“脆弱性”视为首要设计约束(而非附带问题)。
- 将鲁棒性要求前置到Token生成层(而非完全依赖下游LLM去适应)。
从产业落地的角度看,这类“基础稳定性修复”工作,可能比许多追求极致性能的复杂技巧更为关键。现实世界的语音输入天然伴随噪声、口音和设备差异。如果不先夯实离散语义编码这一基础步骤,后续所有“智能”处理都难免受到上游输入波动的干扰和拖累。
这篇论文最令人印象深刻的并非其达到的SOTA性能,而是它清晰回答了一个许多人遭遇过却难以言明的痛点。答案不仅仅是笼统的“离散化造成信息损失”,而是更具体的机制:
- 微小声学扰动会引发Token序列的级联式变化。
- 这会显著增加下游LLM的学习难度与负担。
- Token的稳定性本身就是影响下游性能的一阶关键变量。
如果你正在从事SpeechLLM或相关领域的工作,这篇论文值得深入研读。它提供的不仅是一个能在论文榜单上获胜的技巧,更是一条切实可行的工程化思路:先确保Token的稳定,再追求模型的强大。
论文信息
 发表于 2026-4-5 09:19:03
|
查看: 143|
回复: 0
发表于 2026-4-5 09:19:03
|
查看: 143|
回复: 0
