如果说内存是 Linux 内核稳定运行的基石,那么伙伴系统与 SLUB 分配器就是支撑这块基石最核心的两大支柱。许多开发者对内核的理解往往停留在表面,如果对这两个组件的协同工作一知半解,就很难真正把握内核如何高效驾驭有限的内存资源。无论是进程创建、模块加载,还是系统的日常内存回收,其背后都离不开这两大分配器的精密配合。
伙伴系统如同“宏观调控者”,负责大块连续物理内存的分配,致力于解决内存碎片化难题;而 SLUB 分配器则是“微观管理者”,专注于内核中小内存对象的精细化、高性能分配。二者相辅相成,共同构成了 Linux 内核高效内存管理的底层逻辑。接下来,我们将深入剖析这两大组件的工作原理与协作机制。
一、Linux 内存管理回顾
Linux 内存管理体系的高效运行,关键在于伙伴系统与 SLUB 分配器的协同。伙伴系统作为底层基础,管理大块连续物理内存,它通过 2 的幂次分组和伙伴合并策略,有效对抗外部碎片,为数据库、视频处理等需要大量连续内存的场景提供支撑。SLUB 分配器则聚焦于内核中小对象(如进程描述符、inode)的分配,通过缓存、Slab、对象三级架构和 CPU 本地缓存等机制,大幅降低小内存分配的开销,减少内部碎片。
两者并非孤立,而是互补共生。SLUB 依赖伙伴系统获取底层页框来创建 Slab,并在空闲时归还;伙伴系统则借助 SLUB 分流海量的小内存请求,避免自身因频繁分割而产生碎片。这种“宏观+微观”的组合拳,让 Linux 内存管理能灵活应对服务器、嵌入式设备等多样化的场景需求。
二、伙伴系统:连续内存的守护者
2.1 什么是伙伴系统?
伙伴系统是一种经典的内存管理算法,其核心思想是将物理内存按 2 的幂次方大小进行划分和管理。系统将可用内存划分为最大阶(如 2^MAX_ORDER)的内存块,然后递归地将其分裂为更小的块,直至单个页框大小。每一阶(order)对应一个独立的空闲链表,用于高效管理该尺寸的所有空闲内存块。这种设计让系统能快速响应不同大小的内存请求,同时通过将链表分散到不同 CPU 节点来减少锁竞争。
“伙伴关系”是算法的灵魂:两个大小相同、地址连续且满足特定对齐条件的内存块互为伙伴。当一个内存块被释放时,系统会检查其伙伴是否空闲;若是,则两者合并成一个更高阶的空闲块。这种机制极大地减少了外部碎片的产生。
2.2 伙伴系统工作原理
伙伴系统是管理物理内存页框的核心机制,旨在高效分配连续内存并减少碎片。它将空闲页框按 2 的幂次分组,order 0 代表 1 页,order 1 代表 2 页,以此类推。
当申请 2^k 个页框时,系统首先查找 order-k 的空闲链表。如果有,则直接分配;如果没有,就向上查找更大的空闲块(如 order k+1)。找到后,将该大块一分为二,一半用于分配,另一半放入低一阶的空闲链表中,这个过程可能递归进行。
在内存回收时,系统会检查被释放块的伙伴是否也空闲。如果是,则合并成一个更高阶的块,并递归向上尝试进一步合并。这种“分裂分配、合并回收”的机制,有效保持了内存的连续性。
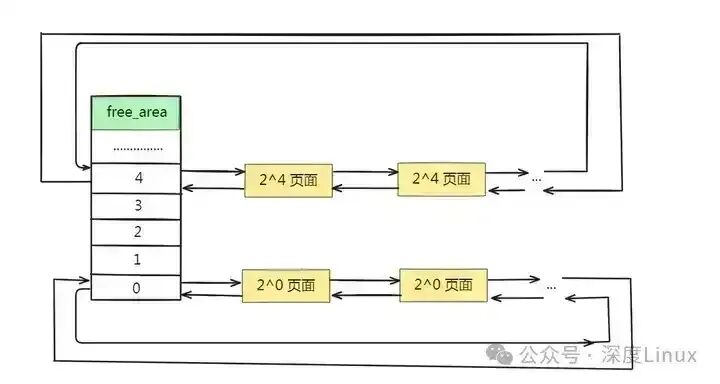
2.3 数据结构与内存区域
伙伴系统依赖于几个关键数据结构。在 NUMA 系统中,pglist_data 表示内存节点。每个节点包含多个内存区域(zone),常见的有:
- ZONE_DMA:供老式 DMA 设备使用(如 ISA 总线)。
- ZONE_DMA32:用于 32 位地址空间的 DMA。
- ZONE_NORMAL:常规直接映射内存区域。
- ZONE_HIGHMEM:高端内存,主要在 32 位系统中用于访问超过 896MB 的物理内存。
每个 zone 都维护着一个 free_area 数组,这是伙伴系统的核心:
struct zone{
...
struct free_area free_area[MAX_ORDER];
};
MAX_ORDER 通常为 11。每个 free_area[order] 都是一个双向链表,挂载着所有大小为 2^order 页的空闲块。
伙伴系统核心数据结构真实内核实现示例如下:
#include <linux/mm_types.h>
#include <linux/list.h>
// 最大分配阶数,内核中通常定义为 11
#define MAX_ORDER 11
// 双向链表头,用于挂载对应阶数的空闲内存块
struct free_area {
struct list_head free_list; // 空闲块双向链表
unsigned long nr_free; // 当前阶数的空闲块数量
};
// 内存区域 zone 结构体(精简内核真实结构)
struct zone {
// 伙伴系统核心:每个阶数对应一个 free_area
struct free_area free_area[MAX_ORDER];
// 内存区域基本信息
unsigned long zone_start_pfn; // 区域起始页帧号
unsigned long zone_end_pfn; // 区域结束页帧号
const char *name; // 区域名称:DMA/DMA32/NORMAL/HIGHMEM
};
// 内存节点 pglist_data 结构体(NUMA 系统使用)
struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; // 包含多个内存区域
struct zone *node_zone_populated[]; // 已启用的区域指针
};
2.4 伙伴系统内存管理机制
(1)伙伴系统初始化。
系统启动时,内核会根据配置初始化各个内存区域(zone),并将早期内存分配器(如 memblock)管理的内存释放给伙伴系统。之后,所有物理内存的分配回收都由伙伴系统负责。分配函数通常需要两个关键参数:gfp_mask(指定从哪个内存区域分配,如 __GFP_DMA)和 order(指定分配阶数)。
内核内存分配/释放代码示例:
// 包含伙伴系统核心头文件
#include <linux/mm.h>
#include <linux/gfp.h>
#include <linux/module.h>
// 内核模块初始化函数
static int __init buddy_alloc_init(void)
{
// 分配阶数:2^2 = 4 个连续物理页
int order = 2;
// 内核进程上下文标准分配标志
gfp_t gfp_mask = GFP_KERNEL;
// 存储分配得到的内存起始地址
unsigned long virt_addr;
// 调用伙伴系统接口分配物理内存页
virt_addr = __get_free_pages(gfp_mask, order);
// 分配失败判断
if(!virt_addr){
pr_err("伙伴系统:物理内存分配失败\n");
return -ENOMEM;
}
// 打印分配信息
pr_info("伙伴系统:成功分配 order=%d 内存块,地址=0x%lx\n", order, virt_addr);
// 内存使用完成后,释放回伙伴系统
free_pages(virt_addr, order);
pr_info("伙伴系统:内存已释放,等待伙伴块合并\n");
return 0;
}
// 内核模块退出函数
static void __exit buddy_alloc_exit(void)
{
pr_info("伙伴系统内存分配模块已卸载\n");
}
// 注册模块入口与出口
module_init(buddy_alloc_init);
module_exit(buddy_alloc_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Linux 伙伴系统分配与释放示例");
(2)伙伴系统内存分配执行流程。
分配时,系统根据请求大小确定目标阶数 order,并查找对应空闲链表。若找到,直接分配;若未找到,则向更高阶链表查找。找到高阶块后,将其不断分裂,直到得到所需大小的块,并将分裂产生的另一半放入对应低阶链表。
例如,申请 4 页(order-2)内存时,若 order-2 链表为空,但 order-3(8页)链表有块,则将该 8 页块分裂成两个 4 页块,一个用于分配,另一个放入 order-2 链表。
伙伴系统块分裂算法代码示例:
#include <stdio.h>
// 定义系统支持的最大分配阶数
#define MAX_ORDER 10
// 全局数组:存储每个阶数的空闲内存块数量
int free_area[MAX_ORDER] = {0};
// 初始化伙伴系统空闲块
void buddy_system_init(void)
{
// 初始状态:9 阶(512 页)存在 1 个大块空闲内存
free_area[9] = 1;
}
// 分配指定阶数的内存块,无空闲块时分裂高阶块
void buddy_allocate(int target_order)
{
int current_order = target_order + 1;
// 向上遍历高阶链表,查找可用空闲块
while(current_order < MAX_ORDER && free_area[current_order] == 0){
current_order++;
}
// 无可用内存,分配失败
if(current_order >= MAX_ORDER){
printf("分配失败:系统无足够连续物理内存\n");
return;
}
// 逐级分裂高阶块,生成目标阶数内存块
while(current_order > target_order){
// 消耗一个高阶块
free_area[current_order]--;
// 分裂为两个低一阶块
free_area[current_order - 1] += 2;
printf("分裂 %d 阶块 -> 生成 2 个 %d 阶空闲块\n", current_order, current_order-1);
current_order--;
}
// 分配目标阶数内存块
free_area[target_order]--;
printf("成功分配 %d 阶内存块,剩余空闲块:%d\n", target_order, free_area[target_order]);
}
// 主函数:测试内存分配与分裂
int main(void)
{
buddy_system_init();
// 申请 2 阶(4 页)内存块
buddy_allocate(2);
return 0;
}
(3)伙伴系统内存分配完整流程与优化。
伙伴系统的分配流程可以概括为:确定需求阶数 -> 查找对应链表 -> 若没有,向上查找并分裂。为了提高效率,内核采用了多种策略,如最佳适配、首次适配等,并针对多处理器环境引入了基于 CPU 节点的局部缓存,减少锁竞争。
(4)伙伴系统内存回收与合并。
回收是伙伴系统减少碎片的关键。当一个内存块被释放时,系统会计算其伙伴块的地址并检查其状态。如果伙伴块也空闲,则两者合并成一个更高阶的块,并递归尝试进一步合并。
伙伴块合并算法代码示例:
#include <stdio.h>
// 根据内存页号与阶数,计算伙伴块的页号
unsigned long get_buddy_page(unsigned long page_num, int order)
{
// 伙伴系统核心算法:按位异或运算获取伙伴物理地址
return page_num ^ (1UL << order);
}
// 释放内存块,并递归合并伙伴块
void buddy_free_and_merge(unsigned long page_num, int order)
{
unsigned long buddy_page_num;
printf("释放 %d 阶内存块,起始页号:%lu\n", order, page_num);
// 递归合并伙伴块,最大合并至 10 阶
while(order < 10)
{
// 计算伙伴块页号
buddy_page_num = get_buddy_page(page_num, order);
printf("检测伙伴块页号:%lu,状态为空闲可合并\n", buddy_page_num);
// 合并为更高一阶的内存块,使用较小地址作为新块起始地址
page_num = (page_num < buddy_page_num) ? page_num : buddy_page_num;
order++;
printf("合并完成,生成 %d 阶内存块,起始页号:%lu\n", order, page_num);
}
}
// 主函数:测试内存释放与伙伴合并
int main(void)
{
// 释放 2 阶(4 页)内存块,触发合并流程
buddy_free_and_merge(100, 2);
return 0;
}
(5)内存碎片问题与优化方案。
伙伴系统主要面临内部碎片(分配块大于请求)和外部碎片(空闲内存不连续)问题。通过伙伴合并机制能有效减少外部碎片。对于内部碎片,系统会动态监控,当某阶碎片过多时,可能将其拆分为更小的块。此外,还有延迟合并等策略来优化性能。
2.5 伙伴系统的优缺点分析
(1)伙伴系统优点:
- 有效减少外部碎片:通过伙伴合并机制整合零散内存。
- 分配确定性高:固定阶划分,大块内存分配速度快。
- 可扩展性好:适应多处理器环境,通过局部缓存减少锁竞争。
- 算法相对简单高效:时间复杂度低,性能稳定。
(2)伙伴系统缺点:
- 大块分配可能有效率开销:需要向上查找和分裂。
- 存在内部碎片:由于按 2 的幂次分配,可能造成浪费。
- 管理元数据有存储开销:每个空闲链表节点需要维护额外信息。
- 不擅长小块分配:频繁的小内存请求会导致性能下降和碎片,因此需要 SLUB 等分配器来弥补。
三、SLUB 分配器:小内存的高效管家
3.1 什么 SLUB 分配器?
伙伴系统在处理内核中海量的小内存对象(如 task_struct, inode)时力不从心:频繁分配释放导致碎片化严重,且每次分配都要经过复杂的伙伴算法,性能开销大。SLUB(SLAB Allocator 的简化版)分配器正是为解决这些问题而生。
它的目标是实现小内存对象的高效分配与回收,通过对象缓存、预初始化、CPU 本地缓存等机制,大幅降低性能开销,减少内存碎片,并优化多处理器环境下的并发性能。
3.2 架构与核心数据结构
SLUB 采用三级架构:缓存(Cache) -> Slab -> 对象(Object)。
- Cache:每种类型的对象(如进程描述符)有一个专属缓存,像是仓库里的货物分类区。
- Slab:Cache 的基本管理单元,由一个或多个连续页框组成,被划分为多个大小相等的对象槽。一个 Slab 有三种状态:满、空、部分满。
- Object:最小分配单位,即实际可用的内存块。
核心数据结构是 kmem_cache,它是管理一个对象缓存的“大脑”,其关键字段包括:
struct kmem_cache_cpu __percpu *cpu_slab:每 CPU 变量,每个 CPU 有独立的 Slab,避免锁竞争。unsigned int size / object_size:对象总大小和原始大小。unsigned int offset:空闲对象链表指针在对象内的偏移。unsigned int cpu_partial:Per-CPU 部分满 Slab 的最大数量。
3.3 SLUB 分配器核心原理
分配时,采用快速路径优先策略:
- 快速路径:首先检查当前 CPU 的本地缓存(
kmem_cache_cpu),如果有空闲对象,直接取出返回。这是最快的路径。
- 中速路径:如果本地缓存空,则从该 Cache 的全局“部分满 Slab 链表”(partial list)中获取空闲对象填充到本地缓存,再分配。
- 慢速路径:如果全局 partial 链表也空,则向伙伴系统申请新的内存页创建全新 Slab,然后分配。
SLUB 分配器内核分配代码示例:
#include <linux/slab.h>
#include <linux/fs.h>
#include <linux/module.h>
// 定义用于测试的对象大小:模拟文件描述符对象
#define TEST_OBJECT_SIZE sizeof(struct file)
// 模块入口:演示 SLUB 分配器完整分配流程
static int __init slub_alloc_init(void)
{
struct file *file_obj;
gfp_t gfp_flags = GFP_KERNEL;
/**
* 内核标准 SLUB 分配接口
* 内部自动执行:本地缓存 -> 全局 partial -> 伙伴系统 三级分配逻辑
* 1. 优先从当前 CPU 本地缓存获取空闲对象
* 2. 缓存为空则从全局 partial 链表补充
* 3. 无可用 slab 则向伙伴系统申请新内存页
*/
file_obj = kmalloc(TEST_OBJECT_SIZE, gfp_flags);
// 分配失败判断
if (!file_obj) {
pr_err("SLUB 分配器:对象分配失败\n");
return -ENOMEM;
}
pr_info("SLUB 分配器:成功分配对象,大小=%zu 字节\n", TEST_OBJECT_SIZE);
// 分配得到的对象可直接供内核使用
// 业务逻辑...
return 0;
}
// 模块退出
static void __exit slub_alloc_exit(void)
{
pr_info("SLUB 分配器示例模块已卸载\n");
}
module_init(slub_alloc_init);
module_exit(slub_alloc_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Linux SLUB 分配器内存分配示例");
3.4 SLUB 分配器内存释放流程
(1)对象释放与本地缓存回收。
释放对象时,它会被放回当前 CPU 的本地缓存空闲链表。如果本地缓存的空闲对象数量超过阈值,一部分对象会被迁移回全局 partial 链表。如果整个 Slab 的所有对象都变为空闲,则该 Slab 会被释放,其占用的页框最终归还给伙伴系统。
SLUB 分配器内核释放代码示例:
#include <linux/slab.h>
#include <linux/module.h>
// 测试对象大小
#define TEST_OBJECT_SIZE 64
// 演示 SLUB 分配器对象释放流程
static int __init slub_free_init(void)
{
void *obj;
// 分配对象
obj = kmalloc(TEST_OBJECT_SIZE, GFP_KERNEL);
if (!obj) {
pr_err("SLUB 分配器:分配失败\n");
return -ENOMEM;
}
pr_info("SLUB 分配器:分配对象成功,准备释放\n");
/**
* 内核标准 SLUB 释放接口
* 内部自动执行:
* 1. 对象放回当前 CPU 本地缓存空闲链表
* 2. 缓存超限则迁移至全局 partial 链表
* 3. 整个 slab 空闲则返回给伙伴系统
*/
kfree(obj);
pr_info("SLUB 分配器:对象已释放,完成缓存回收/伙伴系统归还\n");
return 0;
}
static void __exit slub_free_exit(void)
{
pr_info("SLUB 释放示例模块退出\n");
}
module_init(slub_free_init);
module_exit(slub_free_exit);
MODULE_LICENSE("GPL");
(2)SLUB 分配器高级优化机制。
SLUB 还采用了延迟回收等机制:内存压力不大时,不会立即将空闲 Slab 归还伙伴系统,而是保留在缓存中供后续快速分配,以降低高并发下的性能抖动。
SLUB 缓存与 Slab 核心结构代码示例:
#include <linux/list.h>
#include <linux/types.h>
// SLUB 分配器核心:CPU 本地缓存结构(精简内核真实结构)
struct kmem_cache_cpu {
void **freeobj; // 当前空闲对象指针
struct page *page; // 当前正在使用的 slab 页
struct page *partial; // 本地 partial slab 链表
unsigned long nr_slabs; // 本地 slab 数量
};
// SLUB 分配器全局缓存结构
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; // 每个 CPU 独立本地缓存
struct list_head partial; // 全局 partial slab 双向链表
unsigned int object_size; // 缓存中对象大小
unsigned int order; // 向伙伴系统申请的阶数
};
3.5 应用场景与优势体现
SLUB 在 Linux 内核 中应用广泛:
- 进程管理:
task_struct 的频繁创建销毁。
- 文件系统:
file 对象和 inode 对象的快速分配。
- 网络协议栈:
sk_buff(套接字缓冲区)等网络对象的管理。
与单纯使用伙伴系统相比,SLUB 的优势非常明显:
- 性能:对象缓存和预初始化机制使小对象分配速度极快。
- 内存利用率:通过对象复用和精细管理,显著减少内部碎片。
- 并发性:每 CPU 缓存设计极大地减少了多核间的锁竞争。
四、伙伴系统与 SLUB 分配器的对比
4.1 分配与回收效率对比
- 分配效率:对于大块内存(>=1页),伙伴系统有优势。对于小块内存(<1页),SLUB 的分配速度平均快约30%,因为它走的是缓存快速路径。
- 回收效率:在高频小对象释放场景,SLUB 的回收效率更高,因为它简化了合并逻辑,主要操作在每 CPU 缓存内完成。
4.2 内存碎片产生情况对比
- 内部碎片:SLUB 更优。它按对象实际大小管理,内部碎片更少。伙伴系统按 2 的幂次分配,可能产生较多内部碎片。
- 外部碎片:伙伴系统通过合并机制对抗外部碎片,但在长期运行后仍可能产生。SLUB 由于对象被限制在特定 Cache 的 Slab 中活动,不太会引起系统级的外部碎片。
4.3 适用场景分析
- 伙伴系统适用:需要大块连续物理内存的场景,如 DMA 缓冲区、大型文件缓存、进程地址空间映射。
- SLUB 分配器适用:内核中小对象高频分配释放的场景,如进程/线程创建销毁、文件开闭、网络连接管理。
五、伙伴系统与 SLUB 分配器的案例分析
5.1 在 Linux 服务器中的应用
在高并发 Web 服务器或数据库服务器中,二者协同工作:
- SLUB:快速分配数以万计的连接描述符(
struct sock)、请求结构体等小对象。
- 伙伴系统:分配大块的页面缓存(Page Cache)用于缓存文件数据,或者为数据库提供大容量缓冲池。
这种分工协作降低了整体锁竞争,确保了在高负载下内存分配的响应速度。
代码示例:服务器场景下伙伴系统 + SLUB 协同分配
#include <linux/slab.h>
#include <linux/mm.h>
#include <linux/module.h>
// 服务器高并发场景:小对象(文件描述符/连接结构体)使用 SLUB
#define SMALL_OBJ_SIZE 256
// 服务器大内存:页面缓存/数据缓冲区使用伙伴系统
#define LARGE_ORDER 3 // 2^3 = 8 个连续物理页
static int __init server_mem_init(void)
{
void *small_obj;
unsigned long large_buf;
// ======================
// SLUB 分配:高频小对象(Web 服务器连接、文件描述符)
// ======================
small_obj = kmalloc(SMALL_OBJ_SIZE, GFP_KERNEL);
if (!small_obj) {
pr_err("服务器内存:SLUB 小对象分配失败\n");
return -ENOMEM;
}
pr_info("服务器内存:SLUB 分配小对象成功,大小=%zu 字节\n", SMALL_OBJ_SIZE);
// ======================
// 伙伴系统分配:大块连续物理内存(页面缓存、数据缓冲区)
// ======================
large_buf = __get_free_pages(GFP_KERNEL, LARGE_ORDER);
if (!large_buf) {
pr_err("服务器内存:伙伴系统大块内存分配失败\n");
kfree(small_obj);
return -ENOMEM;
}
pr_info("服务器内存:伙伴系统分配大块内存成功,阶数=%d\n", LARGE_ORDER);
// 业务逻辑(网络处理、缓存读写)
// ...
// 释放顺序:先 SLUB,后伙伴系统
kfree(small_obj);
free_pages(large_buf, LARGE_ORDER);
pr_info("服务器内存:SLUB + 伙伴系统内存已全部释放\n");
return 0;
}
static void __exit server_mem_exit(void)
{
pr_info("服务器内存管理模块已退出\n");
}
module_init(server_mem_init);
module_exit(server_mem_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Linux 服务器伙伴系统+SLUB 协同分配示例");
5.2 在嵌入式系统中的应用
在内存资源紧张的嵌入式设备(如智能家居网关、工业控制器)中:
- SLUB:高效管理设备驱动结构体、协议栈控制块等小对象,减少内存占用和分配延迟。
- 伙伴系统:为视频帧缓冲、音频流处理等分配有限的连续大块内存,并严格控制外部碎片,防止因碎片导致内存不足。
代码示例:嵌入式系统伙伴系统 + SLUB 协同内存管理
#include <linux/slab.h>
#include <linux/mm.h>
#include <linux/module.h>
// 嵌入式场景:小对象(驱动结构体、协议栈控制块)
#define EMBED_SMALL_OBJ 128
// 嵌入式场景:大块内存(视频缓冲区、音频流)
#define EMBED_LARGE_ORDER 2 // 2^2 = 4 页,适合嵌入式低内存环境
static int __init embed_mem_init(void)
{
void *driver_obj;
unsigned long video_buf;
// ======================
// 嵌入式 SLUB:驱动/协议栈小对象
// ======================
driver_obj = kzalloc(EMBED_SMALL_OBJ, GFP_KERNEL); // 清零分配,适合设备驱动
if (!driver_obj) {
pr_err("嵌入式内存:SLUB 驱动对象分配失败\n");
return -ENOMEM;
}
pr_info("嵌入式内存:SLUB 分配驱动小对象成功,大小=%zu 字节\n", EMBED_SMALL_OBJ);
// ======================
// 嵌入式伙伴系统:音视频大块连续内存
// ======================
video_buf = __get_free_pages(GFP_KERNEL | GFP_DMA32, EMBED_LARGE_ORDER);
if (!video_buf) {
pr_err("嵌入式内存:伙伴系统音视频缓冲区分配失败\n");
kfree(driver_obj);
return -ENOMEM;
}
pr_info("嵌入式内存:伙伴系统分配缓冲区成功,阶数=%d\n", EMBED_LARGE_ORDER);
// 嵌入式业务(视频解码、数据采集、网关协议处理)
// ...
// 内存释放(嵌入式必须严格释放,避免内存泄漏)
kfree(driver_obj);
free_pages(video_buf, EMBED_LARGE_ORDER);
pr_info("嵌入式内存:所有内存已安全释放\n");
return 0;
}
static void __exit embed_mem_exit(void)
{
pr_info("嵌入式内存管理模块已卸载\n");
}
module_init(embed_mem_init);
module_exit(embed_mem_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("嵌入式 Linux 伙伴系统+SLUB 协同内存管理示例");
总结
伙伴系统和 SLUB 分配器是 Linux 内核 内存管理的两个核心层次,一个管“大而连续”,一个管“小而频繁”。理解它们各自的原理、优缺点及协同工作方式,是深入理解 Linux 内核内存子系统乃至进行内核级性能调优的必经之路。通过本文的解析与案例,希望能帮助你建立起对这两大关键组件更清晰、更深入的认识。想与更多开发者交流内核技术?欢迎来到云栈社区探讨。
 发表于 2026-4-6 07:59:15
|
查看: 145|
回复: 0
发表于 2026-4-6 07:59:15
|
查看: 145|
回复: 0
