上周,一个名为 “Gemma 4 on iPhone” 的帖子在 Hacker News 社区获得了 635 分的热度。这并非概念演示,而是真的有人在 iPhone 16 Pro 上跑起了多模态大模型。
点进去查看详情会发现——文本理解、图像识别甚至语音处理,全部在手机本地完成。推理速度达到每秒约 30 个 token,且整个过程无需网络连接,也不需要任何 API Key。
谷歌在 4 月 2 日正式发布了 Gemma 4 模型家族,采用完全开源的 Apache 2.0 许可证。但真正让这件事值得深入探讨的,并非模型本身,而是它成功地在你口袋里的移动设备上运行了起来。
本文将围绕三个核心问题展开:这项技术是如何实现的?实际使用体验究竟如何?以及,这对于开发者和普通用户分别意味着什么?
技术核心:小体积如何实现大能力?
首先要关注一个关键数字:1.5GB。
这是经过量化后的 Gemma 4 E2B 模型在运行时的内存占用量。对于拥有 8GB 内存的 iPhone 16 Pro 来说,运行它绰绰有余。
但随之而来的疑问是:一个仅占用 1.5GB 内存的模型,能力能有多强?通常,模型的参数量与其能力呈正相关。像 GPT-4、Claude 这样的顶尖模型参数量都以千亿甚至万亿计,一个有效参数仅约 20 亿的模型能做什么?
谷歌的答案是名为 PLE(Per-Layer Embeddings,逐层嵌入) 的技术。
传统的 Transformer 模型,其嵌入层通常是“一锤子买卖”——输入在进入模型的第一层就被转换为向量表示,之后在各层间传递。PLE 采用了不同的思路:它在每一层解码器都注入一个额外的二级嵌入信号。这相当于给模型的每一层都配备了一副“新眼镜”,使其能够从不同维度重新审视和理解输入信息。
带来的结果是惊人的:一个仅有 23 亿激活参数 的模型,却获得了接近 51 亿参数模型 的表达深度。模型体积大幅缩小,但“理解力”并未等比例下降。
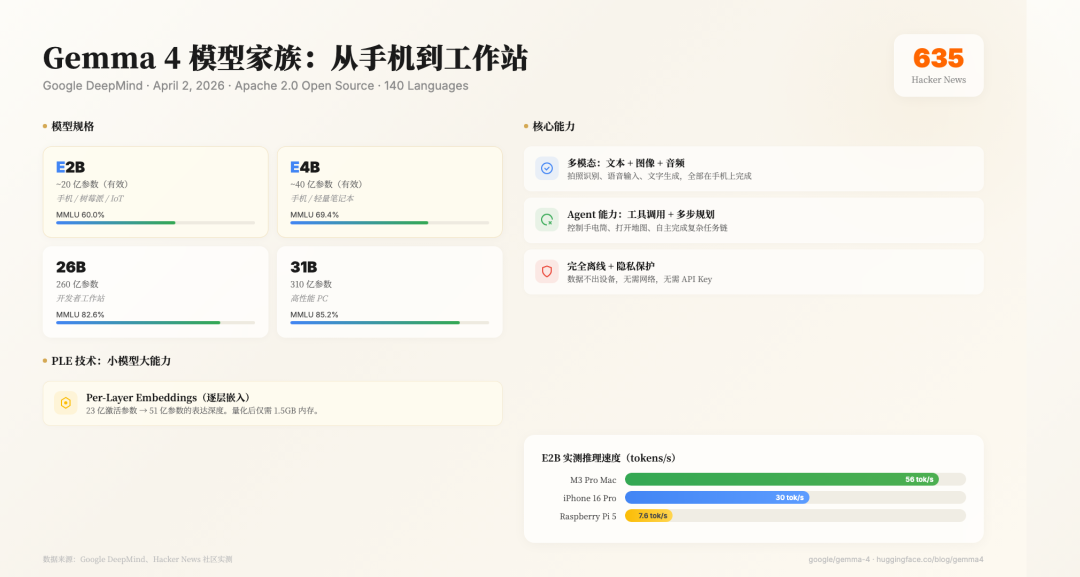
Gemma 4 家族共包含四个版本,从小到大分别是:
- E2B:约 20 亿有效参数,专为手机和 IoT 设备设计。
- E4B:约 40 亿有效参数,面向手机和轻薄笔记本。
- 26B:260 亿参数,适合开发者工作站。
- 31B:310 亿参数,面向高性能 PC。
其中,E2B 和 E4B 名称中的 “E” 代表 “Effective”(有效),正是因为 PLE 技术使得模型实际激活的参数量远低于其名义上的总参数量。
在推理引擎方面,谷歌推出了专为终端设备优化的 LiteRT-LM 框架。它支持 4-bit 量化,将内存占用压缩到极致。根据官方数据,在树莓派 5 上,E2B 模型的预填充速度可达 133 tok/s,解码速度为 7.6 tok/s。而在搭载 Apple Silicon 的 iPhone 上,得益于 Neural Engine 和 GPU 的协同工作,解码速度可以达到约 30 tok/s。
性能基准:数据说明了什么?
先看客观数据,再做出判断。
E2B 模型在 MMLU(大规模多任务语言理解)基准测试中的成绩是 60.0%。这个水平大致相当于早期 GPT-3.5 的能力——能够回答多数常识性问题,但在处理复杂逻辑推理时会显得吃力。
E4B 的表现则更好一些,MMLU 达到 69.4%。更重要的是,在工具调用能力(τ2-bench)测试中,其得分从 E2B 的 29.4% 跃升至 57.5%。这意味着 E4B 在执行需要多步骤操作的任务时,可靠性和准确性显著高于 E2B。
26B 和 31B 版本则属于另一个级别。31B 模型的 MMLU 高达 85.2%,在 AIME 2026(数学竞赛题)上达到 89.2%,在 LiveCodeBench(编程)上为 80.0%——这些成绩已经非常接近 GPT-4o 的水平。当然,这两个版本需要 16GB 以上内存,无法在当前的手机上运行。
一个关键洞察:E4B 与 E2B 之间的能力差距,在工具调用(Agent)方面表现得尤为突出(29.4% vs 57.5%)。因此,如果你打算在手机上开发或使用具备 AI Agent 功能的应用(例如让 AI 帮你操作其他 App),E4B 可以被视为一个更可靠的最低门槛。
真实体验:每秒30个token的速度够用吗?
在 Hacker News 原帖高达 169 条的评论中,许多用户分享了他们的真实体验。
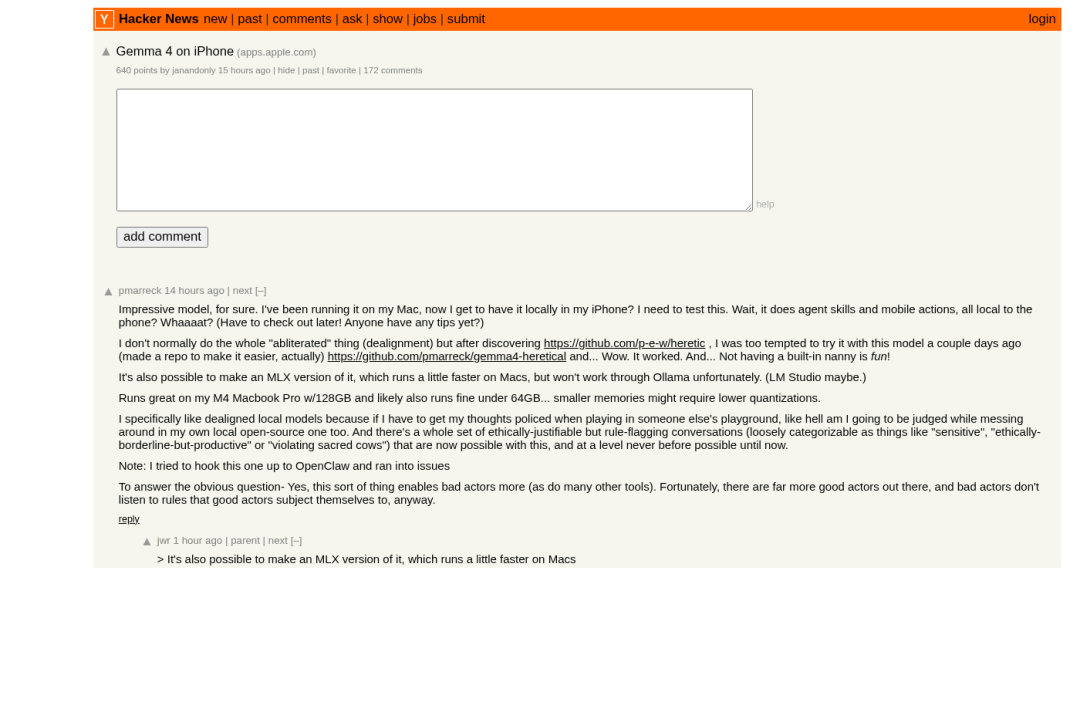
一位名为 allpratik 的用户在 iPhone 16 Pro 上运行 E2B 模型,报告了约 30 tokens/秒的速度。作为参考,人类的平均阅读速度约为每分钟 250 个单词,折算下来大概是每秒 5-6 个 token。30 tok/s 意味着模型的文字生成速度是你阅读速度的 5 倍左右——你往往还来不及看完当前这句话,下一句就已经显示出来了。
从交互流畅度来看,这个速度无疑是够用的。
但实际使用中仍面临两个现实问题:
首先是发热问题。 多位用户反馈,持续使用模型进行 15 分钟以上的对话或任务后,手机会出现明显的发热现象。这是物理规律决定的——神经网络推理本质上是海量的矩阵乘法运算,当手机芯片全力运转时,发热是必然结果。
其次是幻觉问题。 小模型的参数量决定了其知识容量和复杂推理能力存在边界。有 HN 用户测试了经典的 “strawberry 里有几个 ‘r’ ” 这个问题,E2B 模型在不开启推理模式的情况下会答错。这并非模型缺陷,而是其 20 亿参数规模下的能力上限。
然而,最让技术社区感到兴奋的并非其聊天能力,而是 Gemma 4 所展示的 原生 Agent 功能。
谷歌的 “Google AI Edge Gallery” 应用内置了一项名为 “Mobile Actions” 的功能,允许模型直接控制手机:例如打开手电筒、启动地图导航、切换系统设置等。这是在手机端侧实现的真正 AI 智能体,所有决策和执行均不经过任何云端 API。
HN 用户 PullJosh(一名教育领域开发者)评论道:“对我们来说,隐私合规是最大的痛点。如果 AI 处理学生数据的过程全部在本地完成,数据不出设备,那么合规审查的流程将会简化太多。”
行业信号:端侧AI的竞争已然开始
将 “Gemma 4 on iPhone” 置于更大的行业图景中观察,会发现一条清晰的趋势线。
2024 年,苹果发布了 Apple Intelligence,将一个 30 亿参数的语言模型集成到 iOS 18 中。但其策略是封闭的——开发者只能通过系统提供的 API 调用,无法触及模型本身,更不能进行微调或替换。
同年,谷歌将 Gemini Nano 模型内置到 Pixel 8 Pro 手机中,但同样属于闭源方案,用户只能使用谷歌预设的功能。
Gemma 4 的不同之处在于:它是完全开源的,采用 Apache 2.0 许可证,任何人可以下载、修改甚至用于商业用途。开发者可以将这个模型嵌入自己的应用中,实现任何设想的功能,这为 iOS开发 带来了新的可能性。
过去几年,大多数 AI 应用的商业模式都建立在“云端 API 调用”之上——应用每处理一个用户请求,开发者就需要向 OpenAI 或 Anthropic 等公司支付费用。Token 成本如同悬在开发者头上的达摩克利斯之剑,应用越成功、用户越多,成本压力就越大。
端侧运行模型彻底打破了这个循环。一旦模型直接在用户设备上运行,每次推理的边际成本就趋近于零。 没有 API 调用费用,没有带宽成本,也无需维护昂贵的服务器集群。
当然,我们必须承认,E2B 模型的能力无法与 GPT-4o 相提并论。但在众多实际应用场景中,根本不需要那般强大的能力。例如翻译一段文字、识别一张发票、总结一封邮件的要点、生成一条快捷回复——这些日常任务,一个 20 亿参数的模型完全能够胜任。
趋势展望:两极分化的AI未来
原帖作者 janandonly 在评论中写下了一条颇具洞察力的预测:
“未来的 AI 要么在你的设备上免费运行,要么在云端为极致性能支付高昂费用。中间的选项将会逐渐消失。”
这与其他技术领域的趋势如出一辙——计算正在向两极分化。简单的、高频率的任务下沉到终端设备本地处理;复杂的、需要巨大算力的任务则上升到云端完成。而目前市场中那些“不算太贵但能力也非顶尖”的中间层 API 服务,可能会受到来自终端和云端的两端挤压。
对普通用户而言,最直接的影响将是:你手机里的 AI 助手会变得越来越聪明,并且在不联网的离线状态下也能可靠工作,隐私更有保障。
对开发者而言,影响更为深远:现在可以着手构建完全离线的 AI 应用,不再依赖任何第三方云服务。这对于医疗健康辅助诊断、个性化教育辅导、企业内部敏感文档处理等对数据隐私和安全有极高要求的场景,终于提供了一个切实可行的技术路径。在 云栈社区 等开发者聚集地,关于如何利用此类开源模型进行创新的讨论也日益增多。
对行业而言,这是一个强烈的信号:AI 的核心价值不再仅仅被锁在少数几家科技巨头的 API 之后。当模型开源程度如此之高、能力边界扩展至终端设备时,竞争的焦点将从“谁的模型更强”逐渐转向“谁的应用体验更好、更能解决实际问题”。
如何亲自尝试?
如果你也想在 iPhone 上体验 Gemma 4,可以按照以下步骤操作:
- 打开 App Store,搜索 “Google AI Edge Gallery”。
- 下载该应用(免费)。
- 在应用内选择 Gemma 4 E2B 或 E4B 模型。
- 等待模型下载完成(E2B 约 1.5GB)。
- 下载完成后即可开始本地使用。
建议使用 iPhone 15 Pro 或更新机型进行体验。iPhone 14 系列虽然也可能运行,但性能与稳定性可能无法得到最佳保障。
隐私提示:虽然模型推理过程完全在本地进行,但该应用本身来自谷歌。如果你对数据隐私极为敏感,可以在使用应用时主动关闭手机的网络连接(开启飞行模式),模型的运行将不受任何影响。
参考来源:Google DeepMind 官方博客、HuggingFace 模型库、Hacker News 社区讨论。
 发表于 2026-4-7 04:40:04
|
查看: 171|
回复: 0
发表于 2026-4-7 04:40:04
|
查看: 171|
回复: 0
