近年来,AI技术发展迅猛,相关产品和解决方案已深入社会经济的方方面面,成为驱动创新、提升效率的重要引擎。以目前颇受关注的大语言模型和智能驾驶为例:LLM凭借深度学习及海量数据,赋予机器更强大的语言理解与生成能力;智能驾驶则依靠先进的传感技术和算法,让车辆能够在复杂环境中达成自动驾驶。而随着上述AI技术的应用日益广泛,其可观测技术也成为了行业关注的一个焦点。
Prometheus是一款系统监控与报警工具套件,最初由SoundCloud于2012年开始构建,并在2015年正式开源。2016年,Prometheus被捐赠给CNCF,成为继Kubernetes之后第二个在CNCF正式毕业的项目,也奠定了其作为云原生监控领域事实标准的地位。
目前,Prometheus被广泛应用于AI大模型和智能驾驶领域的可观测任务,用于实现最佳性能及减少故障。本文将基于火山引擎托管Prometheus服务VMP与大模型、智能驾驶等领域深度合作所积累的丰富可观测经验,分享在解决这些特定领域高基数问题上的实践经验。
什么是基数
基数是一个数学概念,用于描述集合中元素数量的多少。在可观测领域,指标的基数也是一个常见的概念,可被视为构成指标的不同labels或者tags组合的数量。以如下Prometheus指标为例,http_request_total用于记录一个应用app中某个服务service的某个endpoint的请求数量。假设该应用分布在2个cluster,每个集群有5个service,每个服务有200个endpoint,支持POST和GET2个method,且resp_code有5种可能,那么这个指标的基数就是2 * 5 * 200 * 2 * 5 = 20000。
在实际场景中,此指标的基数或许不足20000,如resp_code始终为200,未曾出现过错误;也有可能超出20000,如新增了一个微服务service。
app_http_request_total{cluster="cluster1", service="service1", endpoint="endpoint1", method="GET", resp_code="200"}
高基数的影响及其成因
基于前文所述的基数概念,高基数意味着一个系统生成了大量的监控指标,会给监控系统带来诸多较大的影响,包括但不限于:
- 监控系统成本上升,例如CPU、内存、存储等资源成本增加:监控系统会为指标创建索引和缓存,指标基数越大,相应的索引、缓存所占用的磁盘空间和内存就越大,建立索引和缓存的过程也会消耗更多的CPU;
- 指标读写响应时间受到影响:建立索引的过程会延长写入请求的响应时间。对于读请求而言,相同的查询语句会命中更多的指标,进而增加了读请求的响应时间;
- 超出监控系统分配的读写quota上限:监控系统通常为多租户系统,为保障系统的稳定性,一般会为不同租户分配一定的指标quota,具有高基数的指标更易触及该quota。
在指标采集链路中,高基数产生的原因可能如下:
大模型、智能驾驶领域的高基数
大模型和智能驾驶领域出现高基数问题的一个常见的原因是高流失率。但不同于上述不可枚举的业务label, 这两个领域常见的高基数label是pod name,因为模型训练可能涉及大量的任务(Kubetnetes Job),部分任务的生命周期甚至只有几分钟,大量任务的频繁创建导致pod name label的变化非常频繁,从而产生了高基数。
大模型领域另外一个高基数场景是大模型开发平台(如火山方舟),用户在大模型开发平台会基于基础模型或精调模型创建大量接入点,每个接入点可以类比一个微服务。随着大模型在各种应用场景井喷式的爆发,接入点的数量高出传统微服务数量几万、几十万甚至更高数量级,这直接提升了监控目标的数量或单个目标暴露的时序量,从而带来高基数问题。
高基数问题的常见解决方案
高基数问题常见的解决方法可从指标设计、指标采集以及指标分析等方面着手。
指标设计
合理建模。指标旨在反映某一组件或系统的状态,label并非越详尽越好。例如,若依据某个key对系统进行分片,那么记录分片的标识(ID)相较于记录该key,更容易发现系统的问题。倘若需要详尽了解某个key乃至某次请求的细节信息,那么采用日志(log)或者跟踪(trace)或许比使用度量(metric)更为合理。

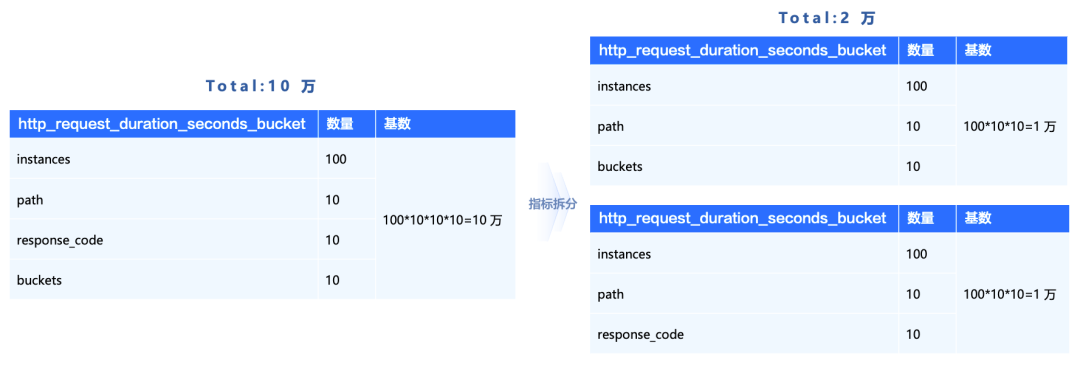
指标分解。基于使用场景,对指标的label予以合理划分,避免将所有label一概添加至一个指标。
指标生命周期。对于部分反映资源状态的指标,其生命周期应与资源的生命周期保持一致。当资源被删除或长时间未被使用时,与之相关的指标也应予以清理。
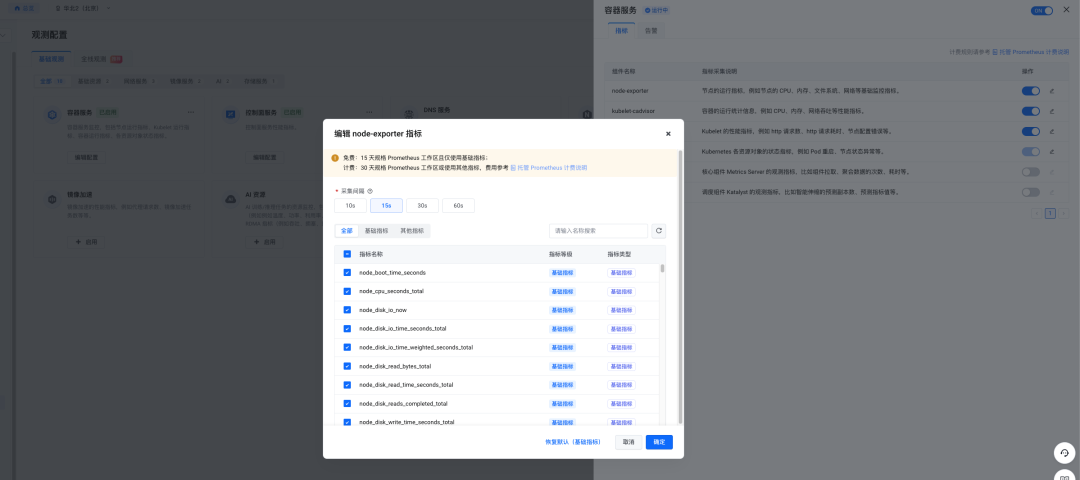
指标开关。有时一个组件涵盖众多维度指标,并非每个维度指标都是用户必然关注的。在此情形下,可为所暴露的指标设置一些开关,例如node-exporter便提供了此类配置。
按需取舍
按需开启。上文提及的node-exporter、kube-state-metrics均提供了指标的开关。开发者可以确认所采集的exporter是否具有类似的指标开关,并关闭不关注的指标。
写入前丢弃。在exporter层面未提供指标开关,且对某些指标不予以关注的情况下,可于采集端配置若干relabel策略,以通过relabel将不关注的指标予以丢弃:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config。火山引擎托管Prometheus服务VMP在容器服务VKE的采集组件中提供了可视化的指标丢弃操作,为用户提供了一种更便捷的配置方式。
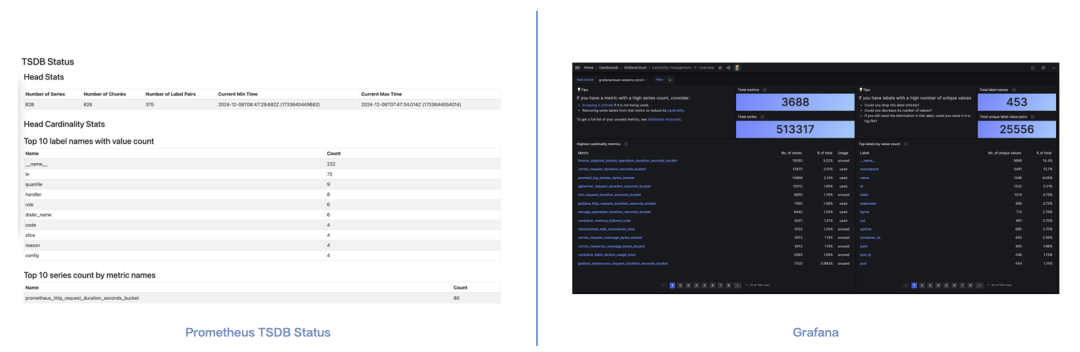
指标分析
若系统已生成高基数指标且欲探究其成因,一种高效的途径是借助工具对该指标予以分析。Prometheus与Grafana都提供了此类工具。VMP也推出了专家级分析服务,白屏化的分析工具正在研发之中。
大模型/智能驾驶领域高基数解决方案
对于大模型和自动驾驶领域的一般高基数问题,上述常见解决方案同样适用,且在实践中都取得了不错的效果。但随着数据量的持续攀升,为进一步保障可观测的性能,我们需要探寻一些更为深入的解决方案。
写入侧预聚合
在VKE中,VMP提供了Prometheus数据采集组件。借助该组件的预聚合功能,能够降低指标的基数和点数。
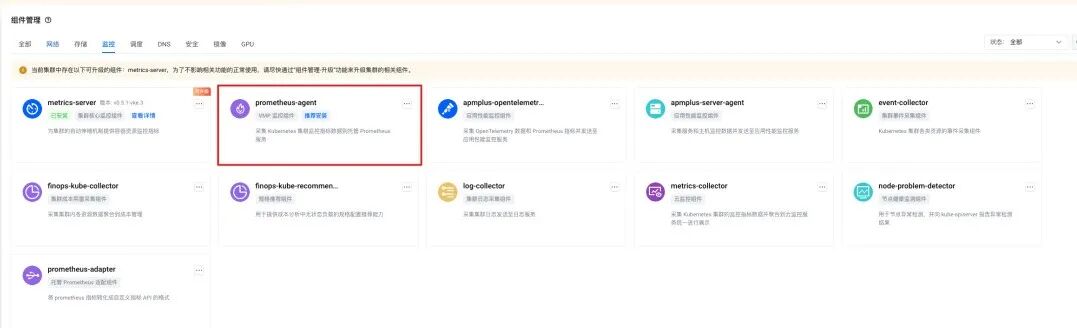
以“container_cpu_usage_seconds_total”指标为例,其标签包含“cluster”“node_pool”“node”“pod”等。当“pod”频繁变动时,“container_cpu_usage_seconds_total”指标的基数会极高。但实际上,业务方关注的并非某个“pod”的CPU使用情况,而是某个节点池或者某组训练任务的CPU使用状况,因此可在写入监控系统前通过预聚合对“pod”进行聚合处理。其他指标也可采用类似方式。

聚合查询
在一个PromQL的执行流程中,从磁盘读取数据的过程可简要归结为两个阶段:
- 依据PromQL的SeriesSelector来搜寻对应的时序。此过程与搜索引擎颇为相似,借助倒排索引获取相应的metricID;
- 基于第一步所获取的metricID以及查询的时间范围,从磁盘读取数据点。
当指标基数极高时,倒排索引的“规模”将变得极大,查找流程所耗费的时间会很长,也会对系统带来稳定性冲击。为防止过大的查询对系统的稳定性产生影响,VMP在查询所命中的时序基数超出特定阈值时会执行查询熔断操作。单个Prometheus实例(VMP的Workspace)的承载能力存在局限,故而考虑通过多个Prometheus实例分片来提高所承载的数据量。
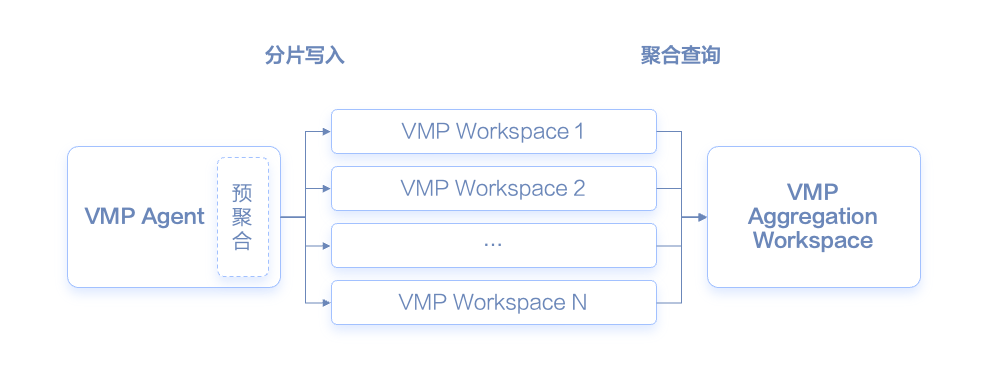
在写入方面,前文提及VMP所提供的采集组件具备将数据分片写入多个Prometheus实例的功能,在此不再赘述。在查询方面,如何提供统一的查询视图呢?
Prometheus社区提供了原生的解决方案RemoteRead:https://prometheus.io/blog/2019/10/10/remote-read-meets-streaming/#remote-apis。此协议作用于存储层,将多个Prometheus实例的原始时序数据汇聚一处,而后执行PromQL的语法树,这种方式通常需要传输大量数据。然而,在实际场景中,针对高基数指标查询的PromQL,通常都会包含聚合语句,并且聚合算子如sum、count、avg等均具有支持下推的特性,例如sum(A+B)= sum(A) + sum(B)。因此,如果能仅传输多个Prometheus实例的聚合结果,则相较于传输原始时序数据便能够大幅减少传输数据量。基于上述思路,VMP提供了基于查询下推的聚合查询功能。
以如下查询语句为例,VMP在将PromQL解析为抽象语法树(AST)后,会对AST进行改写:遍历整个语法树,查找可下推的算子,将该算子替换为多个Workspace查询请求,并将查询结果予以合并作为该算子的执行结果。当一个PromQL语句不存在可下推的算子时,该算法退化为RemoteRead的方式,通过拉取原始时序数据进行计算。Thanos社区也提供了类似的方案:https://thanos.io/tip/proposals-done/202301-distributed-query-execution.md/。

此外,聚合查询不仅在应对高基数的场景时能够发挥显著作用,在跨云查询以及跨Region查询场景中同样能够得到应用,以满足跨云用户或跨云上云下用户的全局查询需求。上述方案还存在一些优化的调度策略,例如通过维护路由信息,跳过特定Workspace的查询请求,从而提升查询效率。路由信息的维护能够结合写入侧分片策略、labels动态发现或者用户自定义路由表等方式来实现。
写在最后
以上就是火山引擎可观测团队对大模型和智能驾驶领域Prometheus监控高基数问题的观点和实践。高基数问题是现代可观测性面临的关键挑战之一,特别是在AI驱动的复杂业务场景下。解决它需要从指标设计、采集优化到后端查询引擎的全链路深度思考与实践。在实际运维与开发工作中,合理规划监控指标体系,是保障系统稳定与高效运行的前提。如果你也遇到过类似的挑战,或对云原生监控领域的技术有独到见解,欢迎在云栈社区与更多技术同行交流探讨。
 发表于 2026-4-7 06:56:15
|
查看: 138|
回复: 0
发表于 2026-4-7 06:56:15
|
查看: 138|
回复: 0
