在探讨容器原理时我们提到,容器通过 Network Namespace 实现了网络资源的隔离。被隔离的进程只能看到当前 Namespace 里的网络栈。
这个网络栈包含了网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。无论是 Linux 宿主机还是容器,其网络功能都依赖于网络栈来实现。
那么,构建一个可用的容器网络,我们需要解决哪些核心问题呢?
- 容器 IP 地址的分配与管理。
- 同一节点上容器间的互相访问(本文聚焦单节点,跨节点访问通常由 Kubernetes 等编排系统解决)。
- 容器如何访问宿主机外部网络(如互联网)。
- 外部网络如何访问到容器内部的服务。
接下来,我们就带着这四个问题,一步步拆解容器网络的实现原理。
Linux 虚拟网络技术基础
容器网络并非魔法,其基石是 Linux 内核提供的强大虚拟网络能力。Linux 不仅能作为网络终端,还能模拟交换机、路由器等网络设备。Network Namespace 正是利用了诸如虚拟网卡对、网桥、路由、iptables 等技术来实现的。我们先来认识两个关键角色:veth pair 和 bridge。
Linux veth pair
veth pair 是一种成对出现的虚拟网络设备接口。你可以把它们想象成一根虚拟网线的两端。数据从一端进入,必定会从另一端出来。因此,只要将 veth pair 的两端分别放入两个不同的 Network Namespace,这两个原本隔离的命名空间就能实现网络互通。
Linux 默认情况下,即使在同一台主机上创建的两个 Network Namespace,彼此之间也是无法通信的。
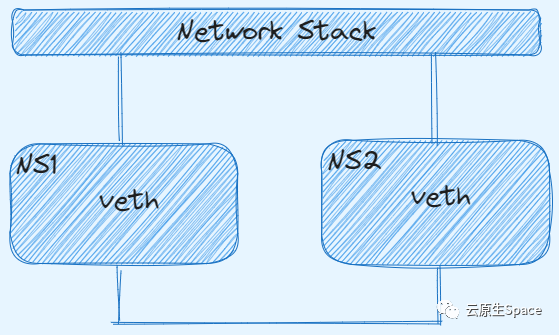
下面我们通过实操,用 veth pair 连接两个 Namespace 并验证连通性。
首先,创建两个网络命名空间 ns1 和 ns2:
$ ip netns add ns1
$ ip netns add ns2
接着,创建一对 veth pair,分别命名为 veth-ns1 和 veth-ns2:
$ ip link add veth-ns1 type veth peer name veth-ns2
然后,将这对 veth 的两端分别放入 ns1 和 ns2,就像用网线连接了两个独立的主机:
$ ip link set veth-ns1 netns ns1
$ ip link set veth-ns2 netns ns2
为两个命名空间内的网卡配置 IP 地址,让它们处于同一个子网 192.168.1.0/24 中:
$ ip -n ns1 addr add 192.168.1.1/24 dev veth-ns1
$ ip -n ns2 addr add 192.168.1.2/24 dev veth-ns2
启动这两张虚拟网卡:
$ ip -n ns1 link set veth-ns1 up
$ ip -n ns2 link set veth-ns2 up
现在,从 ns1 中 ping ns2 的 IP 地址,测试连通性:
$ ip netns exec ns1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.142 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.021 ms
可以分别进入 ns1 和 ns2 查看网卡信息,确认配置生效:
$ ip netns exec ns1 ifconfig
veth-ns1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::e415:f8ff:fe53:bbb3 prefixlen 64 scopeid 0x20<link>
ether e6:15:f8:53:bb:b3 txqueuelen 1000 (Ethernet)
RX packets 45 bytes 3693 (3.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 54 bytes 4642 (4.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip netns exec ns2 ifconfig
veth-ns2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.2 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::e415:f8ff:fe53:bbb3 prefixlen 64 scopeid 0x20<link>
ether e6:15:f8:53:bb:b3 txqueuelen 1000 (Ethernet)
RX packets 45 bytes 3693 (3.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 54 bytes 4642 (4.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Bridge(网桥)
veth pair 解决了两个网络之间的直连问题,但如果需要连接三个甚至更多 Namespace 到同一个二层网络呢?在物理网络中,我们会使用交换机或网桥。幸运的是,Linux 也提供了虚拟网桥的实现。
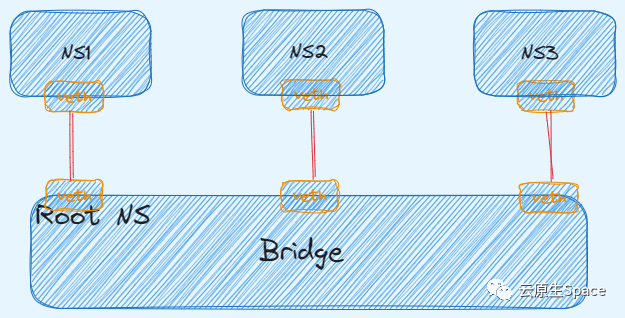
下面演示如何通过 Bridge 连通三个 Namespace。
创建三个命名空间:
$ ip netns add ns1
$ ip netns add ns2
$ ip netns add ns3
创建一个 Linux 虚拟网桥:
$ brctl addbr virtual-bridge
我们需要创建三对 veth pair,每对的一端放入对应的 Namespace,另一端接入网桥。这就像把三台电脑用网线连接到同一个交换机上。
# 创建第一对 veth,连接 ns1 和 bridge
$ ip link add veth-ns1 type veth peer name veth-ns1-br
$ ip link set veth-ns1 netns ns1
$ brctl addif virtual-bridge veth-ns1-br
# 创建第二对 veth,连接 ns2 和 bridge
$ ip link add veth-ns2 type veth peer name veth-ns2-br
$ ip link set veth-ns2 netns ns2
$ brctl addif virtual-bridge veth-ns2-br
# 创建第三对 veth,连接 ns3 和 bridge
$ ip link add veth-ns3 type veth peer name veth-ns3-br
$ ip link set veth-ns3 netns ns3
$ brctl addif virtual-bridge veth-ns3-br
为三个命名空间内的网卡配置 IP,它们位于同一子网 192.168.1.0/24:
$ ip -n ns1 addr add local 192.168.1.1/24 dev veth-ns1
$ ip -n ns2 addr add local 192.168.1.2/24 dev veth-ns2
$ ip -n ns3 addr add local 192.168.1.3/24 dev veth-ns3
启动网桥和所有的 veth 接口:
$ ip link set virtual-bridge up
$ ip link set veth-ns1-br up
$ ip link set veth-ns2-br up
$ ip link set veth-ns3-br up
$ ip -n ns1 link set veth-ns1 up
$ ip -n ns2 link set veth-ns2 up
$ ip -n ns3 link set veth-ns3 up
测试三个 Namespace 间的连通性:
$ ip netns exec ns1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.131 ms
$ ip netns exec ns1 ping 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.345 ms
64 bytes from 192.168.1.3: icmp_seq=2 ttl=64 time=0.163 ms
此时,bridge 仅作为二层设备(交换机)工作,实现了同子网下 Namespace 的通信。
但如果 Namespace 需要访问宿主机或外部网络呢?仅作为二层设备的 bridge 就无能为力了,因为数据包到达网桥后无法继续路由。
子 Namespace 访问 Root Namespace
要实现子 Namespace 访问其所在的宿主机(Root Namespace),必须借助三层路由功能。
Linux Bridge 不仅可以做二层交换机,还能扮演三层交换机或路由器的角色。我们只需为 bridge 配置一个 IP 地址,并将其设置为子 Namespace 的默认网关,数据包就能通过网桥路由到 Root Namespace。
要让 Linux 内核执行路由转发功能(扮演三层设备),必须开启 IP 转发。
sysctl -w net.ipv4.ip_forward=1 或 echo 1 > /proc/sys/net/ipv4/ip_forward
注意:这种方式是临时的,重启后会失效。
首先创建子命名空间和网桥:
$ ip netns add ns1
$ ip netns add ns2
$ brctl addbr br0
用 veth pair 将 ns1 和 ns2 连接到网桥 br0 上:
$ ip link add veth-ns1 type veth peer name veth-ns1-br
$ ip link set veth-ns1 netns ns1
$ brctl addif br0 veth-ns1-br
$ ip link add veth-ns2 type veth peer name veth-ns2-br
$ ip link set veth-ns2 netns ns2
$ brctl addif br0 veth-ns2-br
为 ns1,ns2 配置 IP:
$ ip -n ns1 addr add local 192.168.1.2/24 dev veth-ns1
$ ip -n ns2 addr add local 192.168.1.3/24 dev veth-ns2
启动网桥和 veth:
$ ip link set br0 up
$ ip link set veth-ns1-br up
$ ip link set veth-ns2-br up
$ ip -n ns1 link set veth-ns1 up
$ ip -n ns2 link set veth-ns2 up
此时,从 ns1 ping 宿主机网卡 IP(例如 172.30.95.74),会发现网络不可达:
# 172.30.95.74 是宿主机网卡 IP
$ ip netns exec ns1 ping 172.30.95.74
connect: Network is unreachable
我们需要为网桥 br0 设置一个 IP,并把它指定为 ns1、ns2 的默认网关:
$ ip addr add local 192.168.1.1/24 dev br0
$ ip link set br0 up
$ ip netns exec ns1 ip route add default via 192.168.1.1
$ ip netns exec ns2 ip route add default via 192.168.1.1
查看宿主机,确认 br0 网卡已配置 IP:
$ ifconfig br0
br0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::d6:2dff:fec5:a767 prefixlen 64 scopeid 0x20<link>
ether 02:d6:2d:c5:a7:67 txqueuelen 1000 (Ethernet)
RX packets 15 bytes 1032 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 656 (656.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
现在,从 ns1 和 ns2 再次 ping 宿主机,网络已经可达:
$ ip netns exec ns1 ping 172.30.95.74
PING 172.30.95.74 (172.30.95.74) 56(84) bytes of data.
64 bytes from 172.30.95.74: icmp_seq=1 ttl=64 time=0.097 ms
64 bytes from 172.30.95.74: icmp_seq=2 ttl=64 time=0.061 ms
$ ip netns exec ns2 ping 172.30.95.74
PING 172.30.95.74 (172.30.95.74) 56(84) bytes of data.
64 bytes from 172.30.95.74: icmp_seq=1 ttl=64 time=0.124 ms
64 bytes from 172.30.95.74: icmp_seq=2 ttl=64 time=0.062 ms
子 Namespace 访问外网
想让子 Namespace 能够访问互联网,还需要配置 iptables 规则。
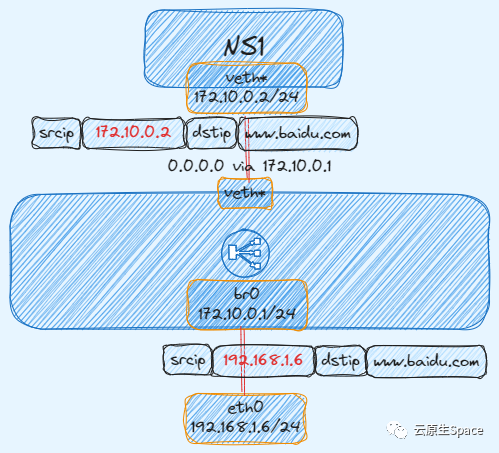
为什么呢?如果不设置规则,从子 Namespace 发出的数据包可以到达外网,但外网的回包会遇到问题。因为回包的目的 IP 是子 Namespace 的私有 IP(如 192.168.1.2),而互联网上的路由器没有到达这个私有网段的路由,导致回包无法送达。
解决方案是使用 SNAT(源地址转换)。当数据包从子 Namespace 发往网桥进而去往外网时,iptables 规则会将数据包的源 IP 地址修改为宿主机的公网 IP。这样,外网服务器回包的目的地就是宿主机,再由宿主机根据连接追踪信息将包转发回对应的 Namespace。
添加 SNAT 规则:
$ iptables -t nat -A POSTROUTING -s 192.168.1.0/24 ! -o br0 -j MASQUERADE
现在,子 Namespace 内就可以访问外网了:
$ ip netns exec ns1 ping www.baidu.com
PING www.a.shifen.com (153.3.238.110) 56(84) bytes of data.
64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=1 ttl=49 time=9.53 ms
64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=2 ttl=49 time=9.52 ms
64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=3 ttl=49 time=9.04 ms
下图展示了数据包经过 SNAT 规则后,其源 IP 地址发生的变化:
端口映射(DNAT)
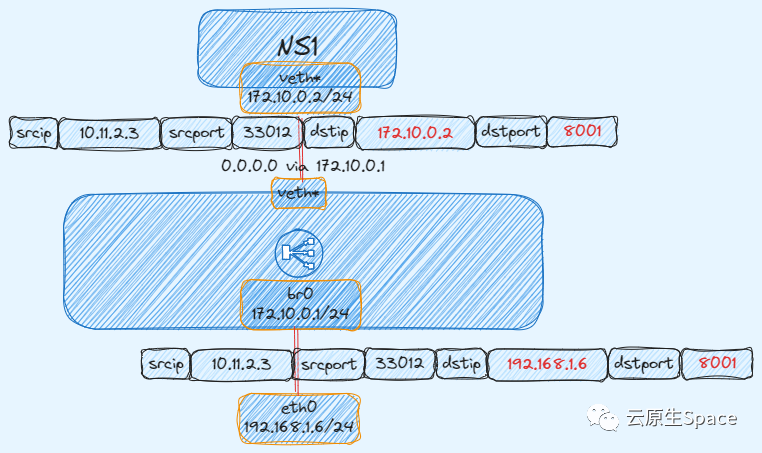
如果希望将子 Namespace 内部的服务发布出去,供外部网络访问,就需要用到 DNAT(目的地址转换) 技术。
例如,在 ns1 中启动一个监听 8001 端口的 HTTP 服务:
$ ip netns exec ns1 python3 -m http.server --bind 192.168.1.2 8001
通过 iptables 设置 DNAT 规则来发布端口。DNAT 的作用是在数据包进入本机或转发前,修改其目的地址和端口。
# 为来自外部网络的流量做 DNAT(流量经过 PREROUTING 链)
$ iptables -t nat -A PREROUTING -d 172.30.95.72 -p tcp -m tcp --dport 8001 -j DNAT --to-destination 192.168.1.2:8001
# 为来自宿主机本地的流量做 DNAT(本地产生的流量不经过 PREROUTING 链,而是 OUTPUT 链)
$ iptables -t nat -A OUTPUT -d 172.30.95.72 -p tcp -m tcp --dport 8000 -j DNAT --to-destination 192.168.1.2:8001
查看已添加的 iptables 规则:
$ iptables -t nat -nL
为了使得网桥上的流量也能被 Netfilter(iptables)处理,需要加载 br_netfilter 内核模块:
$ modprobe br_netfilter
现在,就可以从外部网络或宿主机本机访问这个服务了:
$ curl 172.30.95.72:8001
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=ascii">
<title>Directory listing for /</title>
</head>
<body>
</body>
</html>
下图展示了数据包经过 DNAT 规则后,其目的 IP 和目的端口发生的变化:
回顾一下,我们通过 Linux 的基础网络设施,已经能够模拟出容器网络的所有核心场景:宿主机上容器间互访、容器内访问外网、以及外部访问容器内服务。
接下来,我们看看 Docker 是如何封装这些底层技术,为我们提供便捷的容器网络模型的。
Docker 容器网络模式
Docker 主要提供了四种网络模式:
- Host 模式: 容器与宿主机共享同一个
Network Namespace,容器直接使用宿主机的网络栈。使用 --net=host 指定。
- Bridge 模式: 这是 Docker 的默认网络模式。容器拥有独立的
Network Namespace,并通过 docker0 网桥与宿主机及其他容器通信。使用 --net=bridge 指定。
- Container 模式: 新容器与一个已存在的容器共享
Network Namespace,两者网络环境完全相同。使用 --net=container:NAME_or_ID 指定。
- None 模式: 容器拥有独立的
Network Namespace,但 Docker 不为其配置任何网络(无 IP、无路由)。需要用户手动配置。使用 --net=none 指定。
Host 模式
使用 host 模式启动的容器,不会拥有独立的 Network Namespace,而是与宿主机共享。容器内看到的网卡、IP、路由等信息与宿主机完全一致。
$ docker run -it --net host busybox:latest ifconfig
None 模式
使用 none 模式的容器,拥有自己的 Network Namespace,但 Docker 不会为其配置任何网络。启动后,容器内通常只有回环接口(lo)。
$ docker run -it --net none busybox:latest ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Bridge 模式
这是最常用也是最复杂的模式。其原理与我们上面手动搭建的网络几乎一致。
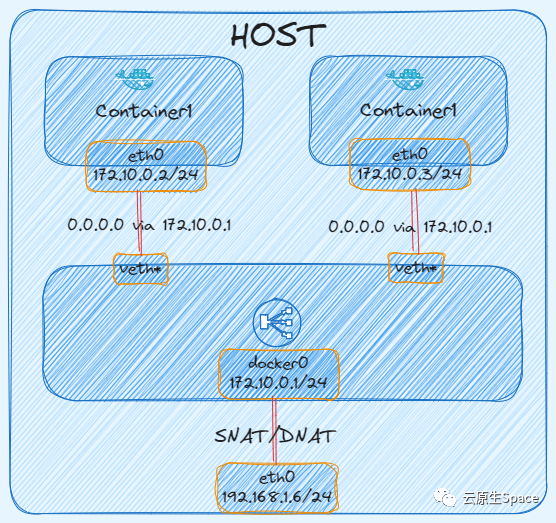
Docker 服务启动时,会在宿主机上自动创建一个名为 docker0 的虚拟网桥,并为其分配一个 IP 地址(通常是 172.17.0.1/16),这个 IP 将作为后续所有 bridge 模式容器的默认网关。
$ ifconfig docker0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:a8ff:fe2a:210 prefixlen 64 scopeid 0x20<link>
ether 02:42:a8:2a:02:10 txqueuelen 0 (Ethernet)
RX packets 10274607 bytes 1726083694 (1.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8862553 bytes 5870677425 (5.4 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
创建一个 bridge 模式的容器:
$ docker run -it --net bridge busybox:latest sh
在容器内查看网络配置,可以看到 Docker 创建了一对 veth,一端在容器内命名为 eth0,另一端在宿主机上连接到了 docker0 网桥。
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
37: eth0@if38: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
/ # ip link show eth0
35: eth0@if36: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
# 在宿主机上查看对应的 veth 端点
$ ip addr | grep 38
38: vethf240dfc@if37: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
查看容器内的路由表,默认网关正是 docker0 的 IP:
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
再创建一个 bridge 模式的容器,两个容器之间可以互相 ping 通,因为它们都接入了 docker0 网桥,且处于同一子网(172.17.0.0/16)。
$ docker run -it --net bridge busybox:latest sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:03
inet addr:172.17.0.3 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:16 errors:0 dropped:0 overruns:0 frame:0
TX packets:16 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1216 (1.1 KiB) TX bytes:1216 (1.1 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2): 56 data bytes
64 bytes from 172.17.0.2: seq=0 ttl=64 time=0.108 ms
64 bytes from 172.17.0.2: seq=1 ttl=64 time=0.119 ms
在宿主机上查看 docker0 网桥,可以看到连接的两个 veth 端点:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02428f5df66f no veth2a72e0f
vethf240dfc
$ ifconfig | grep veth
veth2a72e0f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
vethf240dfc: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
容器内可以访问外网,这是因为 Docker 自动在宿主机上设置了 SNAT 规则:
/ # ping www.baidu.com
PING www.baidu.com (153.3.238.102): 56 data bytes
64 bytes from 153.3.238.102: seq=0 ttl=49 time=8.843 ms
64 bytes from 153.3.238.102: seq=1 ttl=49 time=8.422 ms
# 在宿主机上查看 POSTROUTING 链的 SNAT (MASQUERADE) 规则
$ iptables -t nat -nL POSTROUTING
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 0.0.0.0/0
当使用 -p 参数发布容器端口时,Docker 会自动配置 DNAT 规则。例如,将容器内的 80 端口映射到宿主机的 8080 端口:
$ docker run -d --net bridge -p 8080:80 nginx:latest
$ curl http://172.30.95.74:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Docker 创建的 DNAT 规则与我们手动设置的原理相同,但组织得更清晰,它创建了一个自定义链 DOCKER 来集中管理规则。
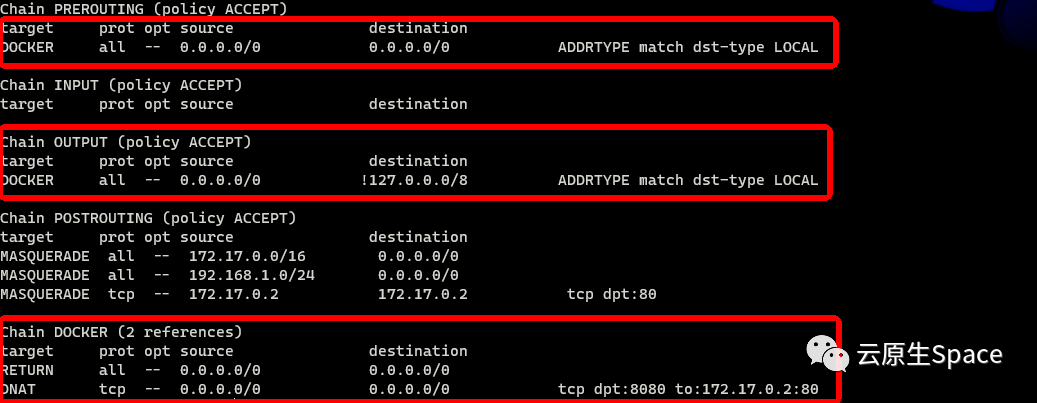
如上图所示,外部流量经 PREROUTING 链、本地流量经 OUTPUT 链,最终都跳转到 DOCKER 链进行目的地址转换。
Container 模式
此模式下,新创建的容器会与一个已经存在的容器共享 Network Namespace,而不是新建一个。新容器不会创建自己的网卡和 IP,而是直接使用目标容器的网络栈。
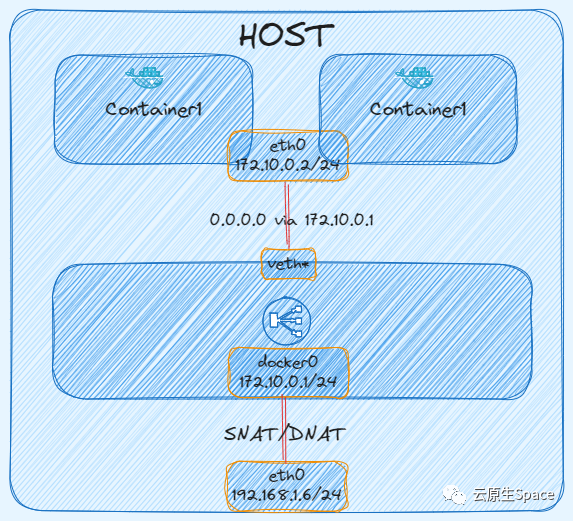
首先,创建一个 bridge 模式的容器:
docker run -it --net bridge busybox:latest sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:03
inet addr:172.17.0.3 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6 errors:0 dropped:0 overruns:0 frame:0
TX packets:5 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:516 (516.0 B) TX bytes:426 (426.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
然后,创建一个新容器,并指定其网络模式为 container,共享上面容器的网络命名空间(假设其容器ID为 8d5aedb8ed81):
docker run -it --net container:8d5aedb8ed81 busybox:latest sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:03
inet addr:172.17.0.3 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:656 (656.0 B) TX bytes:656 (656.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
可以看到,第二个容器的网络配置与第一个容器完全一致。
总结
本文深入探讨了容器网络的实现原理。我们首先学习了 Linux 的两种核心虚拟网络技术:作为虚拟网线连接两个命名空间的 veth pair,以及可作为二层交换机或三层路由器使用的虚拟网桥(bridge)。
随后,我们通过一系列动手实验,逐步实现了在 Network Namespace 中常见的网络场景:
- 多个
Network Namespace 之间的二层/三层通信。
- 子命名空间与 Root Namespace(宿主机)的通信。
- 子命名空间通过 SNAT 访问外部互联网。
- 通过 DNAT 将子命名空间内的服务端口发布到外部网络。
最后,我们剖析了 Docker 的四种网络模式(Host、Bridge、Container、None),发现其本质上就是对上述 Linux 虚拟网络技术、路由和 iptables 规则的封装与自动化。尤其是默认的 Bridge 模式,其工作原理与我们手动搭建的网络模型如出一辙,完美解答了文章开头提出的 “容器网络需要解决的四个核心问题”。
理解这些底层原理,对于在 云原生/IaaS 环境中进行高效的网络排障、性能调优以及自定义网络方案设计至关重要。希望这篇文章能帮助你穿透容器网络的神秘面纱,看到其下坚实而精巧的 网络/系统 基础设施。如果你想深入探讨更多运维与网络技术细节,欢迎在 云栈社区 与大家交流。
 发表于 2026-4-7 07:12:55
|
查看: 198|
回复: 0
发表于 2026-4-7 07:12:55
|
查看: 198|
回复: 0
