在 Kubernetes 集群中,Kubernetes 会为每个 Pod 分配一个 podIP。在默认网络模式下,这个 podIP 是随机分配的虚拟 IP,并且会由于 Pod 重启而自动更新。那么,客户端访问 Pod 时,就必然要面对不断更新访问地址的问题。另一方面,如果一个服务由多个 Pod 实例负载均衡来提供,在客户端侧实现负载均衡访问也显得不够合理。
基于以上两个问题,Kubernetes 实现了 Service。Service 也是一个 Kubernetes 资源对象。每一个 Service 都是一组 Pod 的逻辑集合和对其访问方式的抽象,由 Service 去代理访问上游的每个 Pod 实例。下面我们来详细剖析 K8S Service 的实现原理。
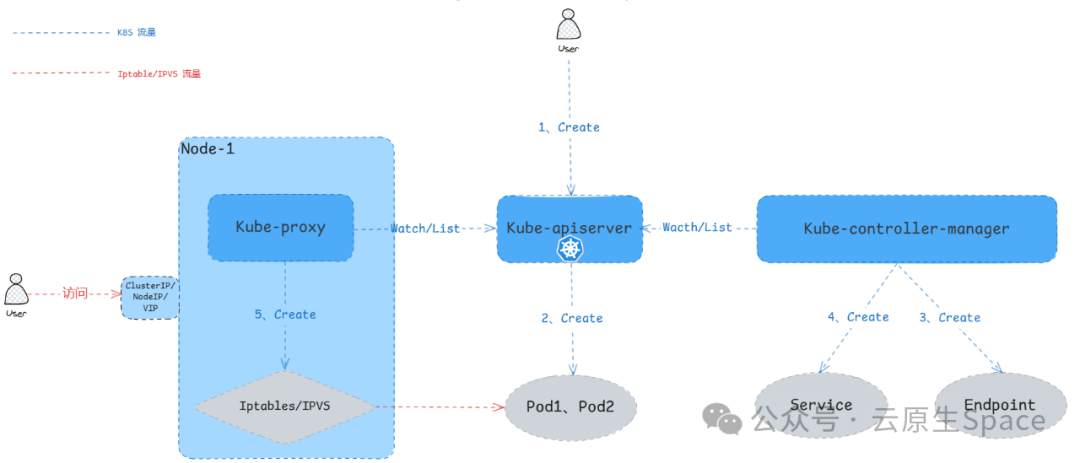
Service 创建流程
当一个 Service 对象创建事件被触发时,Kube-controller-manager 中的 Endpoints controller 会通过 Kube-apiserver 监听(Watch/List)到这个事件。它会根据 Service 的资源定义创建一个与之对应的 Endpoints 对象,这个对象定义了上游 Pod 实例组的 IP 和 Port。Endpoints 资源对象如下:
apiVersion: v1
kind: Endpoints
metadata:
name: svc-a
namespace: default
subsets:
# 上游 Pod 组 IP、Port
- addresses:
- ip: 101.76.9.141
targetRef:
kind: Pod
name: pod-a-55fcf5456c-86mw6
namespace: default
uid: dfcbaa48-912d-4ab6-b935-99e119553cca
ports:
- name: http
port: 80
protocol: TCP
Endpoints controller 创建完 Endpoint 对象后,会接着创建 Service 对象。Service 会根据 selector 字段的标签选择器去匹配并绑定对应的 Endpoints 对象。Service 资源对象如下:
apiVersion: v1
kind: Service
metadata:
name: svc-a
namespace: default
spec:
clusterIP: 10.233.56.44
clusterIPs:
- 10.233.56.44
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: pod-a
sessionAffinity: None
# Service 类型
type: ClusterIP
status:
loadBalancer: {}
当 Service 和 Endpoints 都创建好后,集群中每个节点上的 Kube-proxy 组件会去监听(Watch/List)这些对象,并在节点上创建相应的 Iptables 或 IPVS 规则。这些规则的作用就是将流量根据既定策略转发至上游的 Pod。
所以,整个流程涉及 Service、Endpoint、Pod 这三个核心对象,它们之间的协作关系如下图所示:
IPVS 原理
每个 Node 上都运行着一个 Kube-proxy 组件,它负责为 Service 创建 Iptables 或者 IPVS 规则,实现一种 VIP(虚拟IP)代理模式。
Kube-proxy 支持三种模式:userspace、Iptables 和 IPVS。其中 userspace 模式已不常用。Iptables 模式最主要的问题是在服务数量庞大时会产生大量的规则,其非增量式更新会引入一定延迟,在大规模场景下存在明显的性能瓶颈。为解决 Iptables 模式的性能问题,Kubernetes 从 v1.11 开始正式支持(GA)IPVS 模式。它采用增量式更新,并能保证 Service 更新期间现有连接不断开。从 Kubernetes v1.14 开始,集群默认使用 IPVS 模式。本文也将重点解析 IPVS 模式。
使用 IPVS 作为集群内服务的负载均衡器,可以有效解决 Iptables 带来的性能问题。它的规则数量不会像 Iptables 那样随着 Kubernetes 节点数量的增加而线性增长。IPVS 底层使用了更高效的数据结构(哈希表),理论上支持无限规模扩张。
IPVS 是 Linux 内核实现的四层负载均衡,也是 LVS(Linux Virtual Server)项目的核心。与 Iptables 一样,IPVS 也是基于 Netfilter 框架实现的。它支持 TCP、UDP、SCTP、IPv4、IPv6 等多种协议,并提供了丰富的负载均衡算法,如 rr(轮询)、wrr(加权轮询)、lc(最少连接)、wlc(加权最少连接)等。
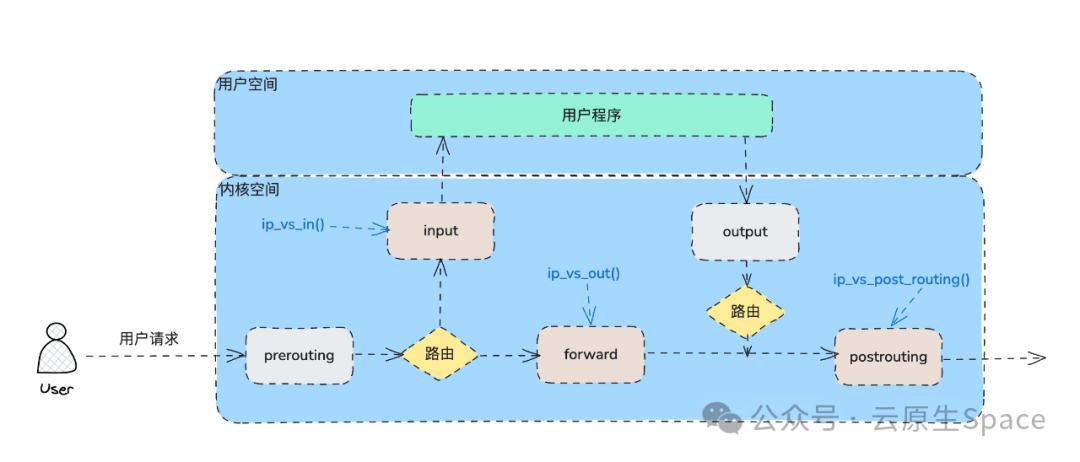
Iptables 向 Netfilter 的 5 个钩子点都注册了对应的表。而 LVS 主要向 Netfilter 的 3 个阶段注册钩子函数来处理数据包,如下图所示:
- 在
LOCAL_IN 阶段注册了 ip_vs_in() 钩子函数。当数据包经过路由判决,发现是发送给本机时,就会调用此函数处理。
- 在
FORWARD 阶段注册了 ip_vs_out() 钩子函数。当数据包经过路由判决,发现不是发送给本机(需要转发)时,会调用此函数。
- 在
POST_ROUTING 阶段注册了 ip_vs_post_routing() 钩子函数。在数据包发送出去之前,会调用此函数。
因此,要使用 IPVS 实现 Service,数据包必须经过 INPUT、FORWARD、POSTROUTING 其中任意一个链,这样才能触发对应的钩子函数。那么,Kubernetes Service 是如何保证报文经过这些链的呢?我们会在后文解释。
IPVS 支持三种负载均衡模式:Direct Routing (DR)、Tunneling (ipip) 和 NAT (Masq)。由于 DR 和 Tunneling 模式都不支持端口映射,而 NAT 模式支持,因此只有 NAT 模式能够支撑 Kubernetes Service 的所有使用场景。下面主要讲解 NAT 模式的原理。
NAT 模式
因为 K8S Pod 提供服务必然要通过端口访问,所以通过 Service 访问 Pod 时,也需要支持将 Service 的端口转发映射到上游 Pod 的端口。IPVS 只有 NAT 模式支持端口转发,其原理与 Iptables 类似,包含了 DNAT(目的地址转换)和 SNAT(源地址转换)。例如,一个将 IPVS 服务端口 3080 映射到 Pod 端口 8080 的规则如下:
TCP 10.233.56.44:3080 rr
-> 101.76.9.141:8080 Masq 1 0 0
-> 101.76.9.142:8080 Masq 1 0 0
但是,仅仅进行 DNAT 会导致回包报文被丢弃,因此还需要一次 SNAT。我们来看看如果不做 SNAT 会出现什么问题:
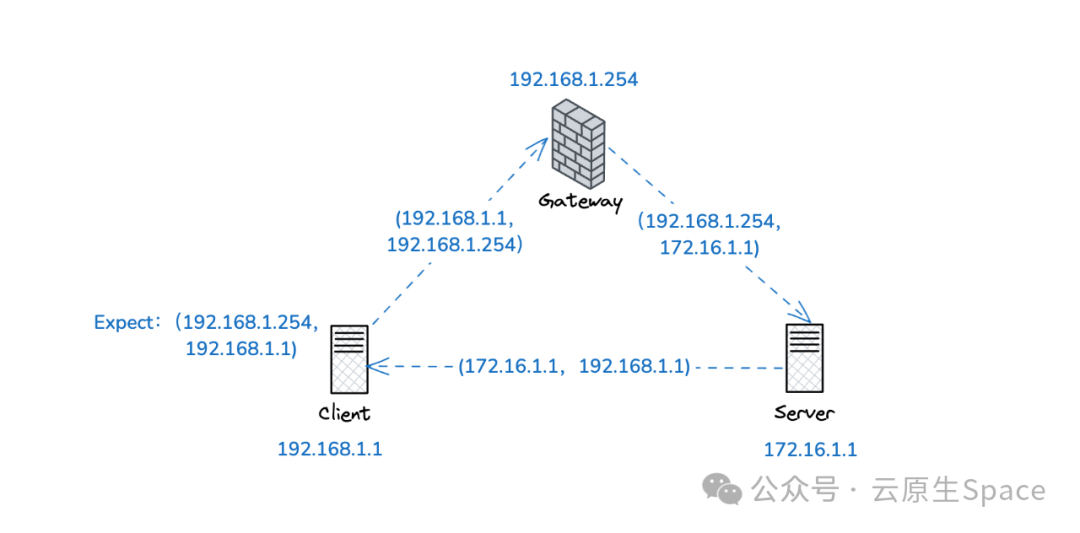
上图中 Client 的 IP 地址为 192.168.1.1,Server 的 IP 地址为 172.16.1.1。Client 无法直接访问 Server,但 Client 和 Gateway 在同一内网,且 Gateway 有到达 Server 的路由,因此 Client 可以通过 Gateway 访问 Server。
Client 向 Server 发起访问,原始报文的源目 IP 地址为 (192.168.1.1, 192.168.1.254)。客户端期待的回程报文源地址应该是 192.168.1.254(即 Gateway 的 IP)。当报文经过 Gateway 的 Netfilter 进行一次 DNAT 后,目的地址被修改成了 172.16.1.1(Server 的地址)。Server 收到报文后,看到源地址是 Client,便会将响应报文直接返回给 Client,此时响应报文的源目地址对为 (172.16.1.1, 192.168.1.1)。这与 Client 端期待的 (192.168.1.254, 192.168.1.1) 不匹配,因此 Client 会丢弃该报文。
所以,当报文不直接送达后端服务,而是经过一个中间设备(如 Gateway)转发时,都需要在网关处做一次 SNAT,将报文的源 IP 修改为网关自身的地址。这样,Server 的响应报文就会先回到 Gateway,然后 Gateway 再将回程报文的目的地址改为 Client 地址,源地址改为 Gateway 地址,从而完成一次完整的通信。
因此,IPVS 在访问 Service VIP 做了一次 DNAT 后,必须再做一次 SNAT 才能让报文顺利返回。然而,Linux 内核原生的 IPVS 实现只做 DNAT,不做 SNAT。所以在这种模式下,Kubernetes 仍然需要借助 Iptables 来实现 SNAT。
有些定制版本的 IPVS,例如华为和阿里自己维护的分支,支持 fullNAT 模式,可以同时处理 SNAT 和 DNAT。这也就解释了为什么在使用 IPVS 模式时,节点上依然会存在 Iptables 规则。
使用 Iptables 创建的 SNAT 规则如下:
# 该命令是查询 POSTROUGING 链上的 nat 表规则
$ iptables -t nat -L POSTROUTING
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
KUBE-POSTROUTING all -- anywhere anywhere /* kubernetes postrouting rules */
# 该命令是查询 KUBE-POSTROUGING 链上的 nat 表规则
$ iptables -t nat -L KUBE-POSTROUTING
Chain KUBE-POSTROUTING (1 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK xor 0x4000
MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */ random-fully
由上述规则可知,IPVS 的报文在经过节点的 Netfilter POSTROUTING 链时,会跳转到 KUBE-POSTROUTING 链处理。在该链中,会为每个报文打上一个 Kubernetes 独有的 MARK 标记 (0x4000/0x4000),并对数据包执行 MASQUERADE(即用节点 IP 替换数据包的源 IP)操作,完成 SNAT。
Service 原理
Service 常用的有三种类型:ClusterIP、NodePort 和 LoadBalancer。下面我们来详细讲解每种类型的实现原理。
ClusterIP
我们在定义 Service 时,如果不指定类型,默认就是 ClusterIP。Kube-proxy 启动时,会在当前节点上创建一个名为 kube-ipvs0 的虚拟网卡。每当创建一个 ClusterIP 类型的 Service,Kube-proxy 都会在 kube-ipvs0 上绑定一个 IP 地址,这个地址就是该 Service 的虚拟 VIP(也可以在创建时手动指定)。以下是一个节点的 kube-ipvs0 网卡信息示例:
$ ip addr show kube-ipvs0
33597871: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 56:b2:39:2a:8b:f5 brd ff:ff:ff:ff:ff:ff
inet 10.233.0.10/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.233.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.233.38.167/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
...
现在可以回答之前的问题了:如何保证 Service 报文能经过 Netfilter 的 INPUT、FORWARD、POSTROUTING 链?答案就是通过创建 kube-ipvs0 网卡并将 Service IP 绑定到该网卡上。这使得内核认为这个 VIP 就是本机的一个 IP 地址,因此发往该 VIP 的报文会进入 INPUT 链。
接着,Kube-proxy 会通过 Linux 的 IPVS 内核模块,为这个 IP 地址设置多个后端的真实服务器(即 Pod),并配置负载均衡策略(如轮询 rr)。我们可以通过 ipvsadm 命令查看:
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.233.56.44:80 rr
-> 101.76.9.141:80 Masq 1 0 0
-> 101.76.9.142:80 Masq 1 0 0
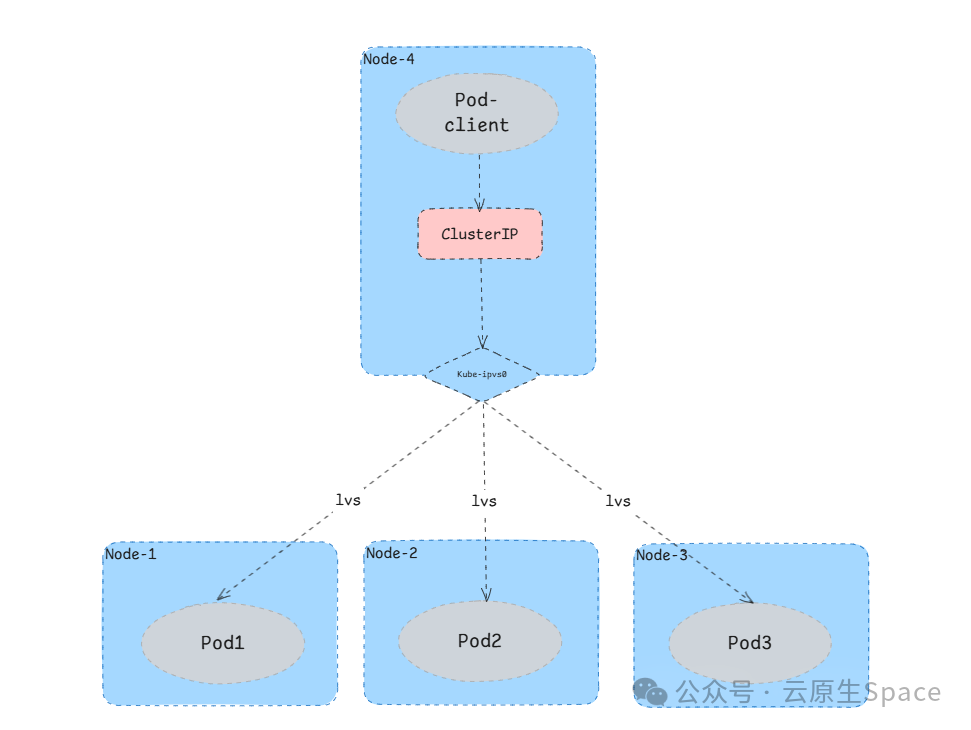
以上 IPVS 规则中,10.233.56.44 就是 Service 的虚拟 VIP,而 101.76.9.141 和 101.76.9.142 则是上游两个 Pod 的 IP 地址。
在集群内部,无论是在 Pod 里还是在节点主机上,任何发往 10.233.56.44:80 的请求,都会被当前节点的 kube-ipvs0 网卡接收,然后通过 IPVS 模块转发到某一个后端 Pod。流量路径如下图所示:
IPVS 提供了多种负载均衡算法:
rr :轮询调度
lc :最小连接数
dh :目标哈希
sh :源哈希
sed :最短期望延迟
nq : 不排队调度
根据上面的描述,在使用 IPVS 模式后,节点上依然会创建用于 SNAT 的 Iptables 规则,不过这条规则是所有 Service 共用的,不需要为每个 Service 单独创建。以上就是 ClusterIP 模式的原理。
NodePort
使用 ClusterIP 只能在集群内部访问。如果需要在集群外部访问 Kubernetes 内部的资源,一种方式就是在物理主机层面开放端口,这就是 NodePort 类型 Service 的作用。
NodePort 类型的 Service 会在所有部署了 Kube-proxy 的节点上打开一个指定的端口。之后,所有发送到这个端口的外部流量,都会被转发到 Service 后端真实的 Pod 进行访问。
当创建 NodePort Service 时,每个节点的 Kube-proxy 都会在该节点上创建一条对应的 IPVS 规则:
$ ipvsadm -l
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.17.0.1:32257 rr
-> 101.76.9.141:9153 Masq 1 0 0
-> 101.76.9.142:9153 Masq 1 0 0
这条规则的意思是,访问 172.17.0.1:32257(节点IP:NodePort)的流量,会被负载均衡到 101.76.9.141:9153 和 101.76.9.142:9153(Pod IP:Port)。流量路径如下图所示:
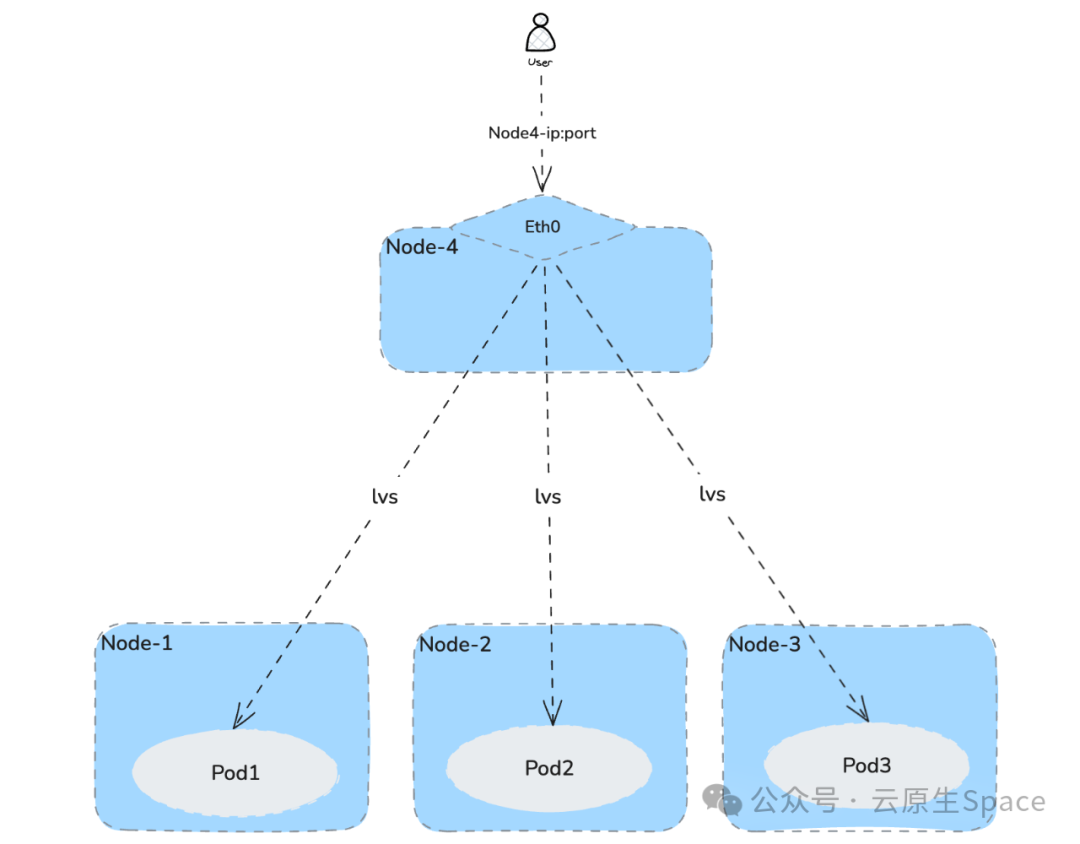
同样,NodePort 模式也会共用之前提到的 SNAT Iptables 规则。
Kubernetes Service 的 NodePort 默认端口范围是 30000-32767。可以通过修改 kube-apiserver 的 --service-node-port-range 启动参数来修改这个范围,例如 --service-node-port-range=8000-9000。
如果需要修改 NodePort 的默认端口范围,除了修改 kube-apiserver 的参数,通常还需要修改 Linux 主机的 ip_local_port_range 内核参数。该参数默认范围是 32768-60999,它定义了系统为本地临时出站连接分配的端口号。必须确保 ip_local_port_range 与 --service-node-port-range 的端口范围没有重叠,否则可能导致端口冲突异常。
LoadBalancer
NodePort 模式虽然实现了集群外访问,但无法保证高可用。例如,如果你使用 Node-1-IP:Port 去访问,当 Node-1 宕机时,就需要手动切换到其他节点。LoadBalancer 类型正是为了解决这个问题,它通过一个外部 VIP(虚拟IP)来提供服务,只要保证这个 VIP 本身高可用即可。
LoadBalancer 类型需要与云供应商的负载均衡器或 MetalLB 这类开源方案配合工作。当创建一个类型为 LoadBalancer 的 Service 时,新 Service 的 EXTERNAL-IP 字段会处于 pending 状态。如果没有配置负载均衡器,它将一直处于此状态:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test LoadBalancer 10.96.0.10 <pending> 53:32083/UDP,53:30321/TCP,9153:32257/TCP 30d
如果集群中配置了负载均衡器(如云厂商的LB或MetalLB),它会自动分配一个外部 VIP 并更新 Service:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test LoadBalancer 10.96.0.10 172.17.0.3 53:32083/UDP,53:30321/TCP,9153:32257/TCP 30d
此时,外部用户通过 172.17.0.3:Port 访问,流量会先到达负载均衡器,再由负载均衡器分发到各个节点的 NodePort,最终到达后端 Pod。关于 LoadBalancer 更详细的原理,可参考 MetalLB 原理 这篇文章。
总结
Kubernetes Service 的三种类型各有其适用场景:
- ClusterIP:用于集群内部访问,无论在节点还是 Pod 内,都可以通信。
- NodePort:集群内、外都可以访问,但依赖具体的节点IP,不具备服务级别的高可用性。
- LoadBalancer:集群内、外都可以访问,通过外部负载均衡器提供稳定、高可用的接入点。
Kube-proxy 实现的是一个分布式负载均衡器,而非集中式。每个节点都充当一个负载均衡器,上面配置着完全相同的 IPVS/Iptables 规则。在 云栈社区 的云原生技术讨论中,我们常建议在生产环境中谨慎使用 NodePort 模式,因为它可能导致流量不均衡地集中在某个特定节点。通常的建议是:集群内部服务间调用使用 ClusterIP,而对外暴露服务则优先使用 LoadBalancer。
 发表于 2026-4-7 07:25:14
|
查看: 121|
回复: 0
发表于 2026-4-7 07:25:14
|
查看: 121|
回复: 0
