计算机专家 Brad 近日展示了他为经典 Intel 8086 和 8088 PC 系统量身打造的一款自制 ISA 加速卡。这张卡的核心目标相当硬核:将早期 x86 系统那颇为捉襟见肘的整数乘法性能,提升大约 2.5 倍。
这项创作的灵感,直接源于对早期 x86 芯片 计算机体系结构 指令执行方式的深入探究。Brad 指出,在 8088/8086 处理器上,乘法操作并非由专用硬件单元完成,而是通过微代码控制的迭代移位/加法算法实现的——这本质上和你用纸笔在二进制下进行竖式乘法计算的方式一模一样。
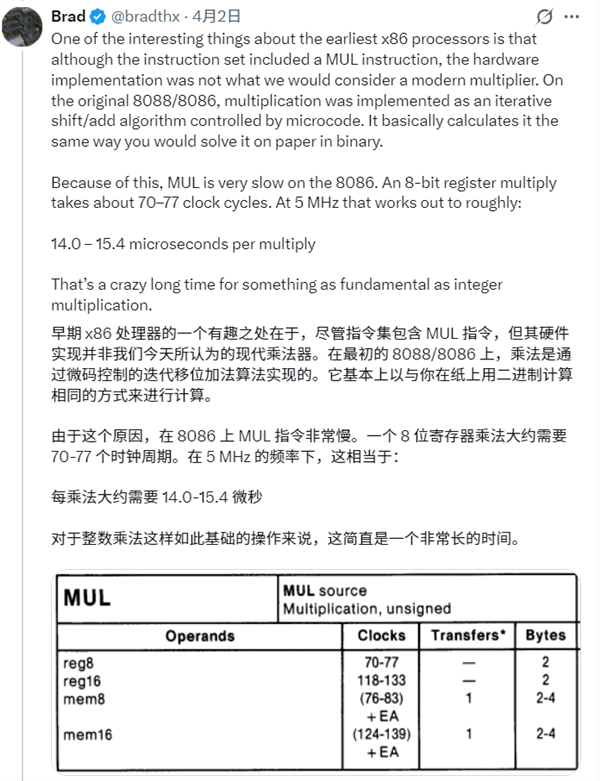
正因为这种实现方式,MUL 指令在 8086 上变得异常缓慢。一次 8 位寄存器乘法大约需要 70-77 个时钟周期。在典型的 5 MHz 主频下,这相当于每次乘法要花费 14.0 到 15.4 微秒。对于整数乘法这种基础运算来说,这个耗时确实相当可观。
为了突破这一性能瓶颈,Brad 将目光投向了历史更悠久的专用芯片:TRW MPY12HJ。这是一款诞生于上世纪 70 年代末至 80 年代初的 12×12 位并行乘法器,专为高速算术运算设计。

这块芯片以异步方式工作,不需要时钟信号,其运行速度仅取决于电信号在硅片内部的传播速度。相比于 CPU 内部那个需要数十个周期循环的微代码乘法例程,这种纯硬件并行计算的效率要高出一个数量级。

Brad 设计的加速卡是一块标准的 ISA 扩展卡,核心就是这块 TRW 乘法器。它的工作原理可以理解为“指令拦截”:当 CPU 执行 MUL 指令时,加速卡会捕获该指令,由 TRW 芯片以极高的速度完成乘法计算,然后将结果通过 ISA 总线返回给 CPU。
由于 TRW 乘法器的计算速度极快,它甚至能在两个连续的总线周期之间就完成计算。因此,尽管 ISA 总线的带宽以今天的标准来看非常有限,但它并没有成为这套加速方案的严重瓶颈。
不过,需要注意的是,这种硬件加速并非“即插即用”地对所有软件生效。它需要程序专门调用一个自定义的子程序来使用这块硬件乘法器。这意味着,现有的、预编译好的应用程序无法从中获益,除非开发者拥有源代码并针对新硬件重新编译。这更像是一种面向特定优化场景和复古计算爱好者的解决方案。

这个项目完美地结合了复古计算情怀与硬核硬件工程。它不仅仅是对性能的追求,更是一次对早期计算机 汇编语言 和硬件交互方式的深度探索。在当今一切追求软硬件协同、高度集成的时代,回顾这种通过外置专用芯片来弥补 CPU 功能短板的设计思路,别有一番风味。
对于热衷于挖掘老旧硬件潜力,或是对计算机 开源硬件 历史感兴趣的朋友来说,这类项目提供了绝佳的学习和借鉴案例。如果你也想了解更多的极客趣闻和硬核技术实践,不妨多逛逛 云栈社区 这样的开发者聚集地,总能发现意想不到的灵感。 |  发表于 2026-4-8 02:28:57
|
查看: 147|
回复: 0
发表于 2026-4-8 02:28:57
|
查看: 147|
回复: 0
