Redis作为现代高性能架构的核心组件,其应对高并发场景的能力至关重要。本文将深入剖析支撑Redis实现百万级QPS(每秒查询率)的四大核心机制。
1. 纯内存操作
内存操作是Redis极致性能的基石。与传统数据库需要频繁进行磁盘I/O(查找、读取、写入)不同,Redis将所有数据存储在主内存(RAM)中,所有操作均在内存中直接完成。

内存访问速度是纳秒级,而磁盘访问是毫秒级,二者相差数个数量级。这从根本上消除了I/O等待延迟,使得Redis能够以极快的速度响应海量并发请求。
2. 多实例分片集群
要真正支撑百万级乃至更高量级的QPS,必须依靠横向扩展能力,而分片(Sharding)正是实现这一目标的“硬核”手段。
通过部署Redis Cluster等分片集群,可以将数据与访问流量水平拆分到多个实例节点上,从而实现吞吐量的线性增长。例如:
- 单实例性能假设为15万 QPS;
- 10个实例节点理论上可支撑约150万 QPS;
- 20个节点则可达到约300万 QPS。
典型的部署中,每个主节点(master)会配备至少一个从节点(slave),以确保高可用与故障转移。常见的分片策略包括基于键的哈希(key hash)、客户端一致性哈希以及Redis Cluster内置的槽位(slot)分配机制。深入理解数据库与中间件的集群化部署,对于构建高可用后端架构至关重要。
3. I/O多路复用机制
这是Redis能够用单线程(或少量线程)高效处理数万甚至更多并发连接的核心技术。
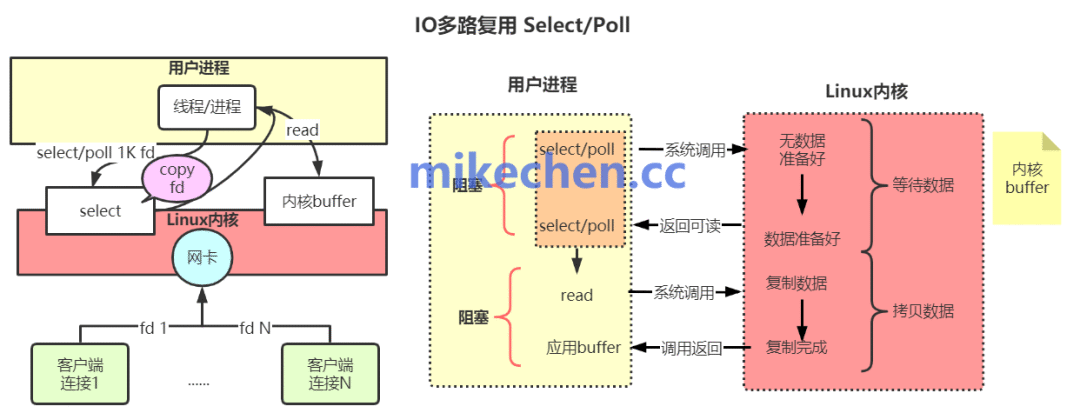
Redis利用了操作系统提供的select、epoll(Linux)或kqueue(macOS/BSD)等I/O多路复用技术。该机制允许一个主线程同时监听多个网络套接字(Socket)上的I/O事件(如连接建立、数据到达、可写等)。
其性能优势在于:当线程等待某个客户端发送数据或网络传输响应时,并不会被阻塞,而是可以去处理其他已就绪套接字上的事件。这种事件驱动模型使得单个线程也能极高效率地管理海量连接,是实现高并发的关键。
4. 高度优化的数据结构
Redis并非简单的键值存储,其每种数据类型背后都采用了精心设计、极度高效的底层数据结构。
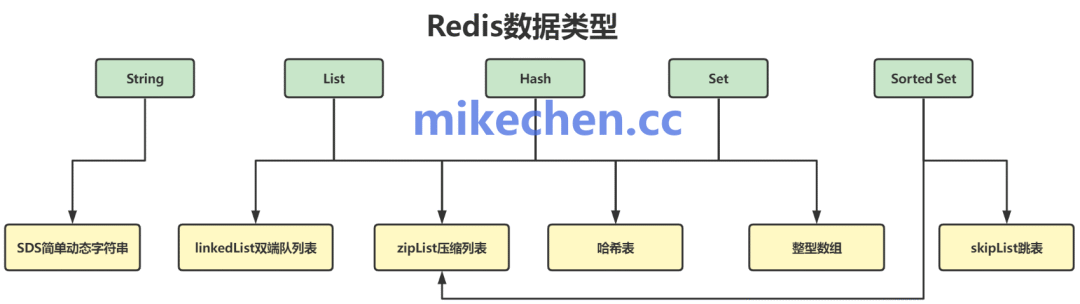
针对不同的数据类型(String, Hash, List, Set, Sorted Set),Redis分别使用了哈希表(Hash Table)、跳跃表(Skip List)、压缩列表(Zip List)、快速列表(Quick List)等数据结构。例如,哈希表提供了O(1)时间复杂度的键值查找,跳跃表为有序集合提供了高效的区间查询能力。这些底层优化确保了数据操作的极致速度。
综上所述,纯内存操作奠定了性能基础,分片集群提供了横向扩展能力,I/O多路复用保障了高连接下的处理效率,而优秀的数据结构则让每次数据访问都更快一步。这四者协同工作,共同构成了Redis应对百万级高并发流量挑战的核心架构体系。掌握这些后端与架构设计原则,是构建稳健高性能系统的关键。 |  发表于 2025-12-11 06:58:47
|
查看: 312|
回复: 0
发表于 2025-12-11 06:58:47
|
查看: 312|
回复: 0
