在后端服务的性能监控中,接口耗时是关键指标之一,通常包括平均响应时间、TP90、TP99等。这些值理想情况下应在毫秒级。一旦响应时间超过1秒,用户端就会感受到明显卡顿,长期如此可能直接影响产品留存。
正常情况下,建立一次TCP连接的耗时大约是一次RTT(往返时间)多一点。然而,现实往往不总是那么顺利,各种异常情况可能导致连接耗时飙升、CPU开销增加,甚至连接超时失败。本文将结合实际线上案例,深入解析TCP三次握手过程中可能遇到的几种典型异常。
一、客户端 connect 系统调用异常
端口号和CPU消耗,这两者看似关联不大,但我确实遇到过因本地端口号不足导致客户端CPU使用率大幅上涨的案例。
客户端发起 connect 系统调用时,核心工作之一是进行本地端口的选择。在选择过程中,内核会从 ip_local_port_range 指定的范围内,从一个随机偏移位置开始遍历,寻找可用的端口。如果端口资源充足,循环几次就能成功退出。但如果端口已被大量消耗甚至耗尽,这个循环就需要执行成千上万次。
我们来看看相关的内核代码逻辑:
//file:net/ipv4/inet_hashtables.c
int __inet_hash_connect(...)
{
inet_get_local_port_range(&low, &high);
remaining = (high - low) + 1;
for (i = 1; i <= remaining; i++) {
// 其中 offset 是一个随机数
port = low + (i + offset) % remaining;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
//加锁
spin_lock(&head->lock);
//一大段的选择端口逻辑
//......
//选择成功就 goto ok
//不成功就 goto next_port
next_port:
//解锁
spin_unlock(&head->lock);
}
}
在每次循环内部,都需要获取自旋锁并在哈希表中进行查找。注意这里使用的是自旋锁(spin_lock),这是一种非阻塞锁。如果锁被占用,进程不会挂起,而是会持续占用CPU进行忙等待,反复尝试获取锁。
假设 ip_local_port_range 配置为 10000 - 30000,且端口已完全耗尽。那么每次发起新连接时,都需要将这个循环执行近两万次才能退出。这将伴随大量的哈希查找和自旋锁竞争,直接导致系统态CPU使用率大幅上升。
以下是两组对比数据:
第一张图是正常情况下的 connect 系统调用耗时,约为 22 微秒。
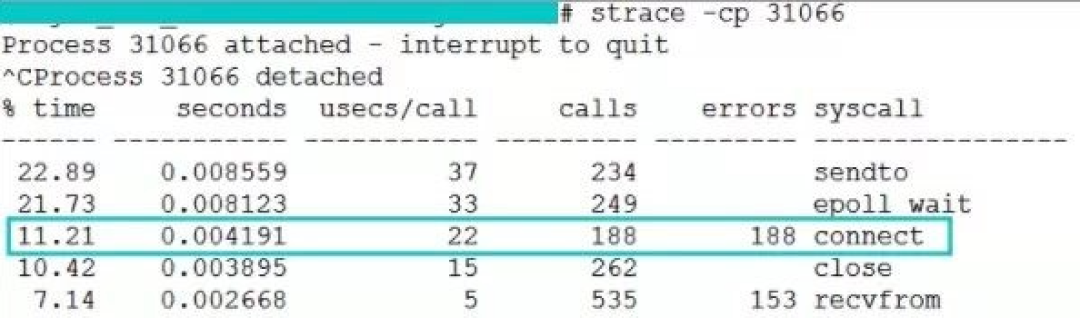
第二张图是某台服务器在本地端口不足时的 connect 开销,高达 2581 微秒。
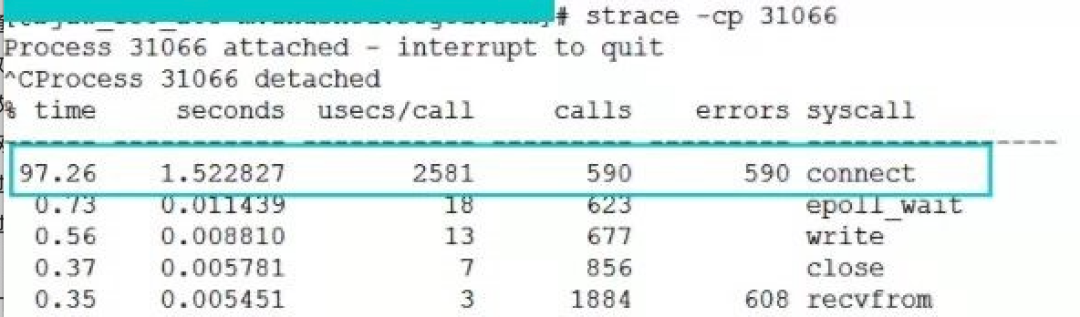
可以看出,异常情况下的 connect 耗时是正常情况的 100 多倍。虽然换算成毫秒只有 2 毫秒多,但请注意,这消耗的全是宝贵的CPU时间片。
二、第一次握手 SYN 包被丢弃
服务器在响应客户端的第一次握手(SYN)请求时,会判断半连接队列(SYN队列)和全连接队列(Accept队列)是否已满。如果发生溢出,内核可能会直接丢弃这个SYN包,不给客户端任何回复。
2.1 半连接队列满
先看半连接队列满的情况:
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
//看看半连接队列是否满了
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, “TCP”);
if (!want_cookie)
goto drop;
}
//看看全连接队列是否满了
...
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
inet_csk_reqsk_queue_is_full 返回 true 表示半连接队列已满。tcp_syn_flood_action 函数会检查 net.ipv4.tcp_syncookies 内核参数是否开启:
//file: net/ipv4/tcp_ipv4.c
bool tcp_syn_flood_action(...)
{
bool want_cookie = false;
if (sysctl_tcp_syncookies) {
want_cookie = true;
}
return want_cookie;
}
结论是:如果半连接队列已满,且 tcp_syncookies 参数为 0,那么服务器会直接丢弃客户端的SYN握手包。
SYN Flood攻击正是利用此机制,耗尽服务器的半连接队列以阻断正常服务。但在现代Linux内核中,只要开启 tcp_syncookies,即使半连接队列满,也能保障正常握手的进行。
2.2 全连接队列满
在半连接队列检查通过后,紧接着是对全连接队列的判断:
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
//看看半连接队列是否满了
...
//看看全连接队列是否满了
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
...
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
sk_acceptq_is_full 判断全连接队列是否满,inet_csk_reqsk_queue_young 判断是否存在未完成的半连接请求(young_ack)。
这意味着:当全连接队列已满,且同时有未处理的半连接请求时,内核同样会丢弃这个SYN包。
2.3 客户端的重试机制
从客户端视角看,服务器因队列满而丢弃SYN包,表现就是发出的SYN包石沉大海,没有任何回应。
好在客户端在发出SYN包时,就启动了一个重传定时器。如果收不到预期的SYN-ACK回复,超时重传逻辑便会触发。但需要注意的是,重传定时器的时间单位是秒。这意味着,一旦发生握手重传,即使第一次重传就成功,接口的最快响应时间也会延迟1秒以上,对用户体验和接口耗时指标影响巨大。
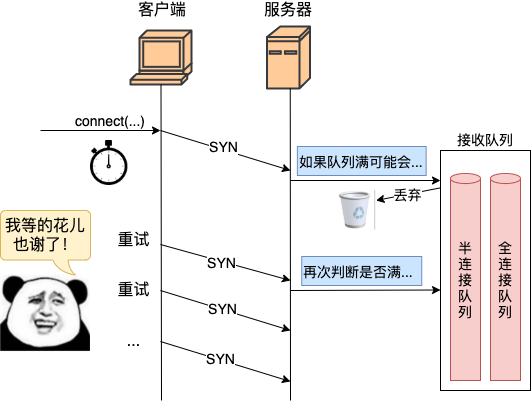
客户端在调用 connect 发出SYN后,立即启动了重传定时器:
//file:net/ipv4/tcp_output.c
int tcp_connect(struct sock *sk)
{
...
//实际发出 syn
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
//启动重传定时器
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
}
定时器的初始超时时间 icsk_rto 被设置为1秒(TCP_TIMEOUT_INIT):
//file:ipv4/tcp_output.c
void tcp_connect_init(struct sock *sk)
{
//初始化为 TCP_TIMEOUT_INIT
inet_csk(sk)->icsk_rto = TCP_TIMEOUT_INIT;
...
}
//file: include/net/tcp.h
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ))
在一些老版本内核(如2.6)中,这个初始值甚至是3秒。
如果服务器正常回复了SYN-ACK,客户端的定时器会在 tcp_rearm_rto 函数中被清除。如果服务器丢包,定时器超时后会回调 tcp_write_timer 进行重传:
//file: net/ipv4/tcp_timer.c
static void tcp_write_timer(unsigned long data)
{
tcp_write_timer_handler(sk);
...
}
void tcp_write_timer_handler(struct sock *sk)
{
//取出定时器类型。
event = icsk->icsk_pending;
switch (event) {
case ICSK_TIME_RETRANS:
icsk->icsk_pending = 0;
tcp_retransmit_timer(sk);
break;
......
}
}
tcp_retransmit_timer 是重传的核心函数,它负责重发数据包,并设置下一次的超时时间:
//file: net/ipv4/tcp_timer.c
void tcp_retransmit_timer(struct sock *sk)
{
...
//超过了重传次数则退出
if (tcp_write_timeout(sk))
goto out;
//重传
if (tcp_retransmit_skb(sk, tcp_write_queue_head(sk)) > 0) {
//重传失败
......
}
//退出前重新设置下一次超时时间
out_reset_timer:
//计算超时时间
if (sk->sk_state == TCP_ESTABLISHED ){
......
} else {
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
}
//设置
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
}
tcp_write_timeout 判断是否超过最大重试次数(受 net.ipv4.tcp_syn_retries 参数影响,但注意是转换为时间对比,并非简单次数对比)。随后重传发送队列头部的SYN包,并将下一次超时时间设置为当前值的两倍(指数退避)。
2.4 实际抓包分析
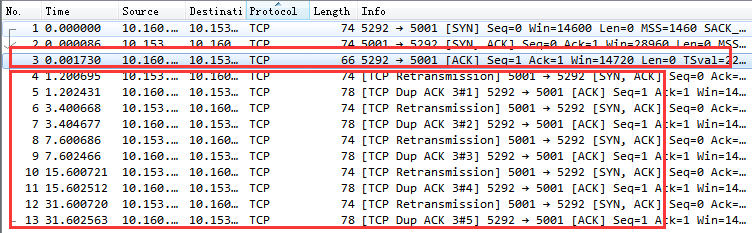
下图展示了一个因服务器第一次握手丢包而引发的完整重传过程:

从抓包图可见,客户端在1秒后进行了第一次SYN重传。由于仍未收到响应,随后在3秒、7秒、15秒、31秒、63秒后分别进行了后续重传,共重试6次(受当时 tcp_syn_retries 设置影响)。
如果服务器因队列满丢弃握手包,接口响应时间将至少增加1秒(在老版本内核上是3秒)。若连续多次重传失败,耗时将轻易达到七八秒,对用户体验是灾难性的。
三、第三次握手 ACK 包被丢弃
当客户端收到服务器的SYN-ACK后,会将自己的状态置为ESTABLISHED,并发出第三次握手ACK。但服务器在处理这最后一个ACK时,仍可能遇到意外。
服务器在准备创建新的 socket 结构以完成连接时,会再次检查全连接队列:
//file: net/ipv4/tcp_ipv4.c
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, ...)
{
//判断接收队列是不是满了
if (sk_acceptq_is_full(sk))
goto exit_overflow;
...
exit_overflow:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
...
}
结论很明显:第三次握手时,如果服务器的全连接队列已满,来自客户端的ACK包又会被直接丢弃。
这很容易理解,三次握手成功后,连接需要放入全连接队列等待应用层 accept。如果队列已满,握手自然无法完成。
有趣的是,第三次握手失败后,重传方不是客户端,而是服务器。因为客户端认为连接已建立,而服务器在半连接队列中还保留着最初的SYN请求。服务器等待半连接定时器超时后,会重新向客户端发送SYN-ACK,以触发客户端重新回复ACK。
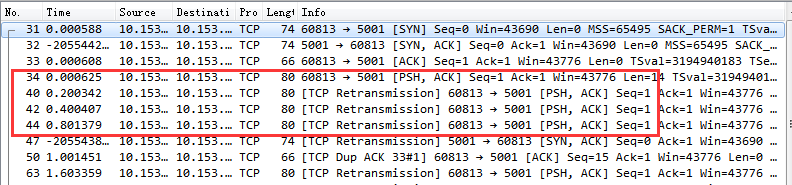
我们通过一个实际案例来看:写一个简单的服务器,只 listen 不 accept,并让客户端占满其全连接队列,然后用另一个客户端发起连接,抓包结果如下:
第一个红框内的ACK就是被服务器丢弃的第三次握手。此时客户端已认为自己连接成功,但服务器并未认可。随后,服务器在半连接定时器触发后,重新发送了SYN-ACK(第二个红框),客户端则以一个新的ACK响应。如果服务器全连接队列持续为满,此重试过程会持续,次数由 net.ipv4.tcp_synack_retries 参数控制。
这里还有一个关键问题:在实践中,客户端在发出第三次握手ACK后,通常会立即开始发送应用层数据。但在这种异常情况下,这些数据包都会被服务器无视,直到连接真正建立成功。
四、总结与解决方案
处理线上复杂的网络问题,是检验工程师功底的标准之一。看似简单的TCP三次握手,在实践中可能因各种异常而变得复杂。深刻理解这些异常,是快速定位和解决问题的前提。
本文重点分析了三类异常:
- 客户端端口不足:导致
connect 系统调用陷入大量自旋锁等待和哈希查找,推高CPU使用率。
- 服务器第一次握手丢包:因半连接队列或全连接队列满所致,导致客户端经历漫长的SYN重传。
- 服务器第三次握手丢包:因全连接队列满所致,由服务器重传SYN-ACK,客户端感知延迟。
一旦发生因队列溢出导致的丢包,即使第一次重试成功,接口耗时也会陡增至1秒(老内核为3秒)。重试两三次后,总耗时可能达到数秒,极易触发Nginx等代理的超时设置,直接导致请求失败。
针对这些问题,我们可以从以下几个层面着手解决:
1. 打开 tcp_syncookies
这是应对半连接队列满(包括SYN Flood攻击)最简单有效的办法。在现代Linux系统中,建议开启此参数以提供一层基础防护。
2. 增大连接队列长度
连接队列的长度配置需要关注:
- 全连接队列:长度为
min(backlog, net.core.somaxconn)。其中 backlog 是应用 listen 时传入的参数。
- 半连接队列:长度计算稍复杂,大致为
min(backlog, somaxconn, net.ipv4.tcp_max_syn_backlog) + 1 再上取整到2的幂次,且最小不小于16。
根据实际情况,调整 net.core.somaxconn(全局)、net.ipv4.tcp_max_syn_backlog 以及应用程序的 listen backlog 参数,确保队列大小能够满足并发连接请求的峰值。
3. 应用程序尽快 accept
确保你的服务器程序在握手成功后,能及时调用 accept 将新连接从全连接队列中取走。避免因处理其他业务逻辑过慢,导致队列堆积。
4. 减少不必要的TCP连接
如果连接请求过于频繁,上述调优可能仍捉襟见肘。此时应考虑优化架构,使用长连接替代短连接。这不仅能从根本上降低握手异常的概率,还能消除三次握手本身带来的内存、CPU和时间开销,是提升整体性能的有效手段。
5. 缓解客户端端口不足
对于客户端端口耗尽问题,可以:
- 调整
net.ipv4.ip_local_port_range,扩大可用端口范围。
- 优化客户端连接策略,使用连接池或长连接复用,减少频繁创建新连接。
- 在特定场景下,可考虑开启
net.ipv4.tcp_tw_reuse(注意 tcp_tw_recycle 已废弃且不建议使用)。
网络问题排查是后端开发与架构中的一项重要技能。希望本文对TCP握手异常的分析,能帮助你在未来的运维和问题排查工作中,更快地定位根因,找到解决方案。
 发表于 2026-4-11 07:12:49
|
查看: 210|
回复: 0
发表于 2026-4-11 07:12:49
|
查看: 210|
回复: 0
