Linux 内核根据功能不同,将 NUMA 节点的物理内存划分为多个独立的物理内存区域,如 ZONE_DMA、ZONE_DMA32、ZONE_NORMAL 和 ZONE_HIGHMEM。本文将深入剖析内核是如何通过 struct zone 这一核心数据结构来精确描述和管理这些区域的。
一、内存区域描述符:struct zone
struct zone 是内核中用于描述和管理 NUMA 节点内一个物理内存区域的结构体,系统的物理内存使用统计信息也大多来源于此。我们首先来看看这个结构体的整体设计。
1.1 内存区域的基本字段
为了追求极致的访问性能,struct zone 的设计非常考究。它被频繁访问的字段被精心归类为4个部分,并用 CACHELINE_PADDING 进行分割,目的是让这四个部分能分别对齐到 CPU 的高速缓存行(Cacheline)中,从而减少多核 CPU 访问时的缓存行伪共享(False Sharing)问题,提升并发访问效率。
struct zone {
...
CACHELINE_PADDING(_pad1_);
...
CACHELINE_PADDING(_pad2_);
...
CACHELINE_PADDING(_pad3_);
...
} ____cacheline_internodealigned_in_smp;
下面是 struct zone 中一些关键的字段(为方便理解,顺序有所调整):
struct zone {
// 防止并发访问该内存区域的自旋锁
spinlock_t lock;
// 内存区域名称,如 "DMA"、"Normal"、"HighMem"
const char *name;
// 指向所属的NUMA节点
struct pglist_data *zone_pgdat;
// 该区域管理的第一个物理页的页帧号(PFN)
unsigned long zone_start_pfn;
// 该区域跨越的总物理页数(包含内存空洞)
unsigned long spanned_pages;
// 该区域实际可用的物理页数(不包含内存空洞)
unsigned long present_pages;
// 由伙伴系统(Buddy System)管理的物理页数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[NR_PAGE_ORDERS];
// 该内存区域的各种使用统计信息
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
};
lock 自旋锁用于保护对该内存区域结构的并发访问。name 字段标识了区域的类型。之前介绍 NUMA 节点描述符 struct pglist_data 时提到,它通过一个 struct zone 类型的数组 node_zones 来组织节点内的所有内存区域。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
}
相应地,每个 struct zone 也会通过 zone_pgdat 指针指回自己所属的 NUMA 节点,形成双向关联。
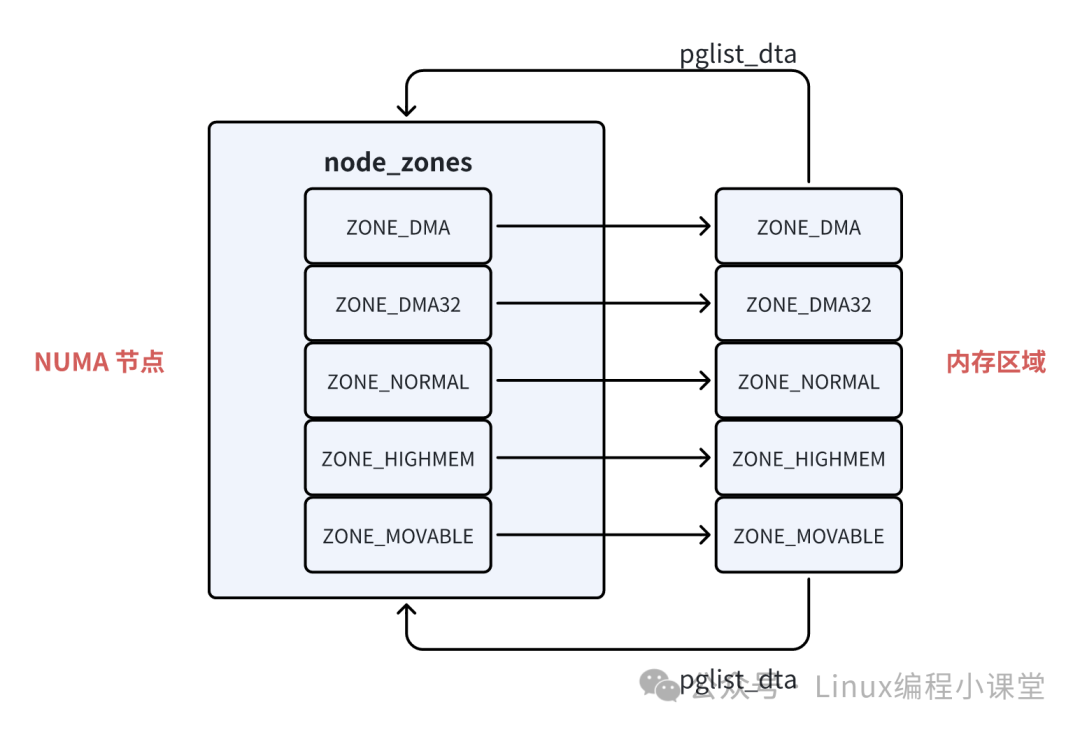
zone_start_pfn 指明了该区域所管理的第一个物理内存页的页帧号。在一个 NUMA 节点内部,内核按照功能将物理内存划分为不同的区域,并为每个区域单独分配一个 伙伴系统(Buddy System) 来负责该区域内物理页的分配与回收。
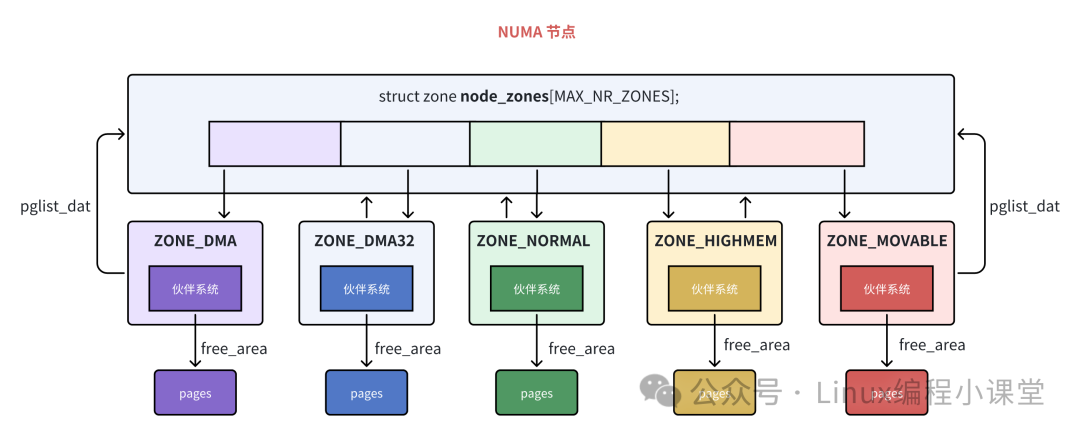
managed_pages 记录了被本区域伙伴系统管理的物理页总数。free_area[MAX_ORDER] 数组是伙伴系统算法的核心数据结构。vm_stat 数组则维护了该区域各种详细的内存使用统计。
1.2 内存区域的预留内存
除了基本描述信息,每个物理内存区域(struct zone)还会为操作系统预留一部分内存。这部分内存专用于内核中一些不允许失败的核心操作。
这是什么意思呢?内核中的内存分配大致分两种场景:
- 常规分配:当内存充足时,请求立刻满足;当内存紧张时,内核会先回收部分内存再分配,此过程请求进程会阻塞等待。
- 原子分配:在执行中断处理程序或持有自旋锁等临界区代码时,内存分配请求必须立刻成功,不允许阻塞。这就需要内核提前预留好内存。
struct zone {
...
// 为原子分配预留的内存页数量
unsigned long nr_reserved_highatomic;
// 为防止高位区域挤压而预留的页数数组
long lowmem_reserve[MAX_NR_ZONES];
...
}
nr_reserved_highatomic 表示该区域为原子操作预留的内存大小(单位是页)。lowmem_reserve 数组则定义了每个区域为“保护”自己而必须保留的物理页数量。
为什么需要这种“保护”?因为一些常规用途的内存可以从多个区域中分配,存在一个“降级分配”的路径:当 ZONE_HIGHMEM 不足时,可以从 ZONE_NORMAL 分配;ZONE_NORMAL 不足时,可以进一步从 ZONE_DMA 分配。
但内核不允许高位区域无限制地侵占挤压低位区域,毕竟低位区域(如 DMA)有其特定的硬件用途。因此,每个区域会根据一个比例来计算并为自己保留一部分内存,防止被过度挤压。这个比例可以通过命令查看:
simon@ubuntu:linux-6.9.1$ cat /proc/sys/vm/lowmem_reserve_ratio
256 256 32 0 0
输出从左到右分别对应 ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_MOVABLE 和 ZONE_DEVICE 区域的预留比例。那么具体如何计算呢?我们以一个例子来理解。
假设有三个区域:ZONE_DMA(比例256,大小8M,2048页)、ZONE_NORMAL(比例32,大小64M,16384页)、ZONE_HIGHMEM(比例0,大小256M,65536页)。
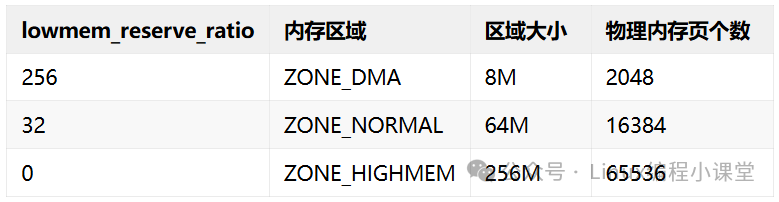
计算过程如下:
- ZONE_DMA 为防止被 ZONE_NORMAL 挤压而预留的页数:
16384 / 256 = 64。
- ZONE_DMA 为防止被 ZONE_HIGHMEM 挤压而预留的页数:
(16384 + 65536) / 256 = 320。
- ZONE_NORMAL 为防止被 ZONE_HIGHMEM 挤压而预留的页数:
65536 / 32 = 2048。
这些计算出的预留页数就存储在各自的 lowmem_reserve 数组中。
1.3 内存区域中的水位线
内核为每个内存区域定义了三条关键的水位线(Watermark),用于动态监控内存压力并触发不同的管理策略。这三条线定义在 include/linux/mmzone.h 中:
enum zone_watermarks {
WMARK_MIN, // 最低水位线,内存紧缺线
WMARK_LOW, // 低水位线,内存警戒线
WMARK_HIGH, // 高水位线,内存安全线
WMARK_PROMO,
NR_WMARK
};
对应的具体水位值存储在 struct zone 的 _watermark[NR_WMARK] 数组中:
struct zone {
// 物理内存区域中的水位线
unsigned long _watermark[NR_WMARK];
}
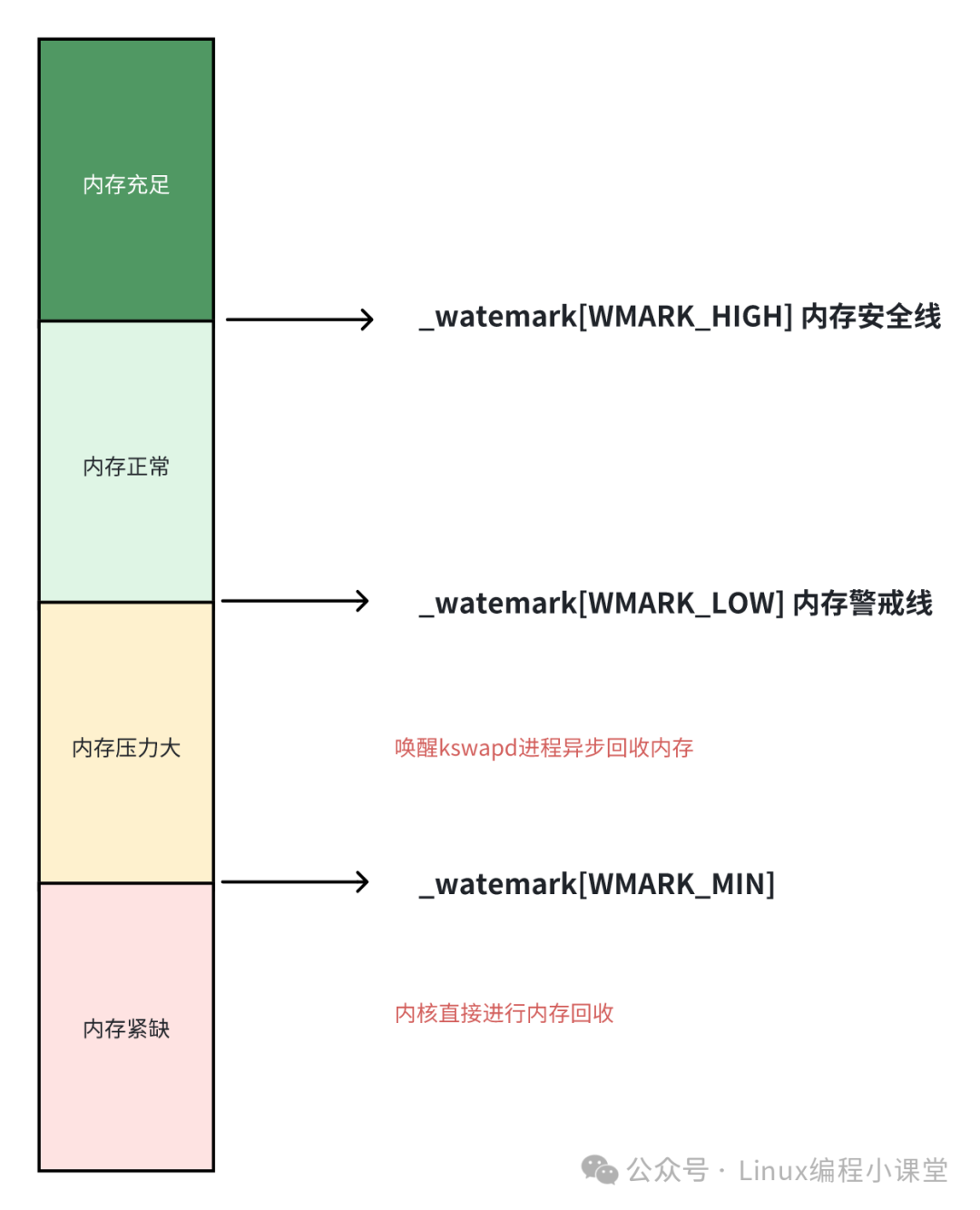
其工作原理如下:
- 内存充足:当区域剩余内存高于
_watermark[WMARK_HIGH] 时,内存分配毫无压力。
- 内存正常:当剩余内存介于
_watermark[WMARK_LOW] 与 _watermark[WMARK_HIGH] 之间时,内存虽有消耗,但仍可正常满足分配需求。
- 内存压力大:当剩余内存介于
_watermark[WMARK_MIN] 与 _watermark[WMARK_LOW] 之间时,内存压力显现。内核在完成此次分配后,会唤醒 kswapd 内核线程开始异步回收内存,直到剩余内存回升至高水位线以上。
- 内存紧缺:当剩余内存低于
_watermark[WMARK_MIN] 时,情况危急。若有进程此时请求内存,内核会进行直接内存回收,请求进程将同步阻塞等待回收完成,这对性能影响较大。
这套基于水位线的机制,是 Linux 内存管理 实现动态平衡和响应式回收的核心。
二、查看系统中的内存区域信息
上面介绍的所有关于内存区域的信息,都可以通过 Linux 系统的 /proc/zoneinfo 接口来查看。例如,查看系统中 NUMA 节点包含哪些内存区域:
simon@ubuntu:linux-6.9.1$ cat /proc/zoneinfo | grep Node
Node 0, zone DMA
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 0, zone Device
查看某个区域(如 DMA 区)的详细状态,可以看到剩余页数(free)、三条水位线(min, low, high)、跨度/可用/管理页数以及保护预留信息等:
simon@ubuntu:linux-6.9.1$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3328 // 剩余内存页数
min 30 // _watermark[WMARK_MIN]
low 37 // _watermark[WMARK_LOW]
high 44 // _watermark[WMARK_HIGH]
spanned 4095 // 总跨度页数
present 3997 // 实际可用页数
managed 3840 // 伙伴系统管理页数
cma 0
protection: (0, 2903, 8355, 8355, 8355) // lowmem_reserve 信息
nr_free_pages 3328
nr_zone_inactive_anon 0
... (后续为各种详细统计计数)
三、总结
本文深入解析了 Linux 内核如何通过 struct zone 结构体精细化管理 NUMA 架构下的物理内存区域。每个区域不仅记录了 zone_start_pfn、managed_pages 等基本信息,还通过 free_area 数组承载了 伙伴系统 这一核心分配器。
为了保障系统鲁棒性,内核设计了 lowmem_reserve 机制,防止高位内存区域无限制侵占低位专用区域。同时,通过 _watermark 水位线动态监控内存压力,智能地在内存充足、正常、压力大和紧缺等状态间切换,并触发异步回收(kswapd)或同步的直接内存回收。
通过 /proc/zoneinfo,我们可以直观地洞察系统每个内存区域的实时状态,这为性能分析和问题排查提供了强大窗口。理解这套机制,是掌握 Linux 内核 内存管理精髓的关键一步。
 发表于 2026-4-11 08:24:49
|
查看: 139|
回复: 0
发表于 2026-4-11 08:24:49
|
查看: 139|
回复: 0
