日志作为系统可观测性的三大支柱之一,在运维监控和故障排查中始终扮演着关键角色。从早期的单体应用演进到如今的云原生环境,日志分析架构也在持续迭代。如果你需要搭建企业级系统,可以参考之前的架构设计讨论。本文则将焦点放在一个更具体的方向:如何针对“轻量化”需求落地一套高效的日志方案,即基于 Fluent Bit + Loki + Grafana(简称 FLG)构建日志采集与分析系统。
架构的演进:从 ELK 到 FLG
在传统的日志管理领域,ELK(Elasticsearch、Logstash、Kibana,含 Filebeat)栈曾是广泛采用的标准方案,很多团队包括笔者本人都曾是其长期用户。一个典型的 ELK 架构流程如下:
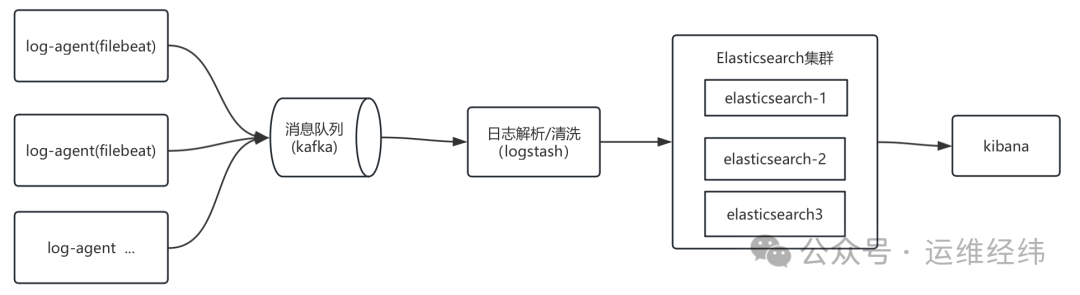
ELK 体系功能强大,但随着业务规模的增长和云原生技术的普及,其架构也暴露出一些痛点:
- 资源消耗大:Elasticsearch 对内存和 CPU 的需求很高,一个最小可用的生产集群通常需要至少 3 个节点。Logstash 基于 JVM,启动慢、内存占用高,在容器化环境中调度效率不佳。尽管后来有更轻量的 Filebeat 作为采集器,但在某些场景下仍非最优解。
- 读写性能瓶颈:Elasticsearch 默认对每条日志内容建立全文索引,这在高并发写入场景下容易成为瓶颈。索引膨胀速度快,也推高了存储成本,即便采用冷热数据分层策略,成本压力依然存在。
- 总体成本高昂:随着数据量的指数级增长,硬件投入和商业许可成本不断攀升。
面对 ELK 的这些挑战,业界开始探索更轻量、更云原生友好的替代方案。最终,Fluent Bit + Loki + Grafana 的组合进入了我们的视野(需要说明的是,如果业务场景强烈依赖全文检索和复杂的关联分析,ELK 依然是值得考虑的方案)。这个组合常被称为“日志领域的 CNCF 黄金三角”,下面我们来逐一解析。
技术栈解析
Fluent Bit:高性能的日志处理引擎
Fluent Bit 是一款用 C 语言编写的轻量级日志处理器与转发器,设计目标就是高效收集、灵活处理与快速转发数据,以满足现代分布式系统的严苛要求。
- 极低的资源占用:凭借其 C 语言内核,它在内存和 CPU 使用率上表现卓越,远超 Logstash 等基于 JVM 的方案,堪称日志采集界的“性能王者”。
- 插件化架构:支持丰富的输入(Input)、过滤(Filter)和输出(Output)插件,生态系统活跃,能轻松对接 Kafka、S3、Elasticsearch、Loki 等多种后端。
- 云原生友好:原生支持 Kubernetes 环境,能够自动发现和采集容器日志。
- 部署灵活:既可以作为 DaemonSet 部署在每个节点上,也可以作为 Sidecar 容器与业务容器协同工作。
Fluent Bit 的核心数据处理流程如下图所示:
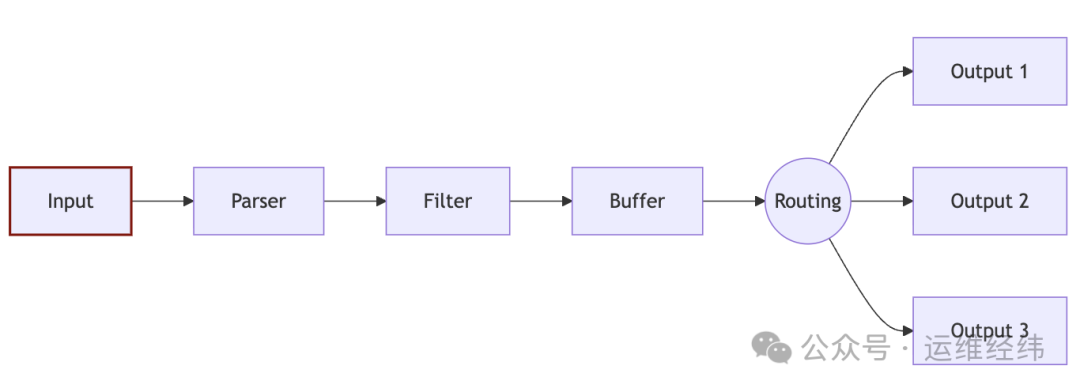
Loki:为日志而生的聚合系统
Loki 是由 Grafana Labs 开发的开源日志聚合系统,专为云原生环境设计。其设计灵感来源于 Prometheus,核心思想是 “索引标签,而非日志内容”。
- 日志模型:日志 = 流(Stream,由一组标签唯一标识)+ 时间戳 + 内容。
- 查询逻辑:先通过标签筛选出相关的日志流,再在指定的时间范围内扫描这些流的原始内容。
这种独特的设计带来了显著优势:
- 经济高效的存储:通过分离稀疏的索引(标签)和压缩存储的日志内容,大幅降低了存储需求,避免了倒排索引的膨胀问题。
- 与 Prometheus 无缝集成:复用相同的标签体系,轻松实现指标与日志的联动查询与上下文切换。
- 运维简洁:组件少,架构清晰,部署和维护相对简单。
- 水平扩展与高可用:采用分布式架构,可通过分片与复制技术应对海量日志数据,保障可靠性。
- 原生 Grafana 支持:在 Grafana 中即可使用类 PromQL 的 LogQL 语法查询日志,无需切换工具。
- 多租户支持:为不同团队或项目提供数据隔离,适合企业级共享集群的使用场景。
Grafana:统一的可观测性平面
对于 Fluent Bit 和 Loki,大家可能稍感陌生,但 Grafana 无疑是可观测性领域的“老熟人”。如今,Grafana 不仅能完美展示指标(Metrics)和链路追踪(Traces),还能无缝集成 Loki 日志。用户可以在同一个面板中完成以下操作:
- 查看服务指标异常;
- 点击异常时间点,直接跳转至对应的日志详情;
- 利用标签快速过滤出相关 Pod 的日志;
- 基于日志内容(如错误率突增)设置告警。
FLG 的协同优势
当 Fluent Bit、Loki 与 Grafana 组合在一起,便形成了一个优势互补的完美技术栈:
- 资源效率:整体资源消耗相比 ELK 架构预计可降低 60-70%。
- Kubernetes 原生:完美适配容器化环境,支持服务自动发现和丰富的元数据(标签)注入。
- 平缓的学习曲线:对于已经使用 Prometheus 的团队,Loki 的标签理念和 LogQL 查询语言非常容易上手。
- 成本可控:存储成本显著降低,特别适合日志量巨大的业务场景。
一个典型的基于 Kubernetes 的 FLG 日志收集架构参考如下:
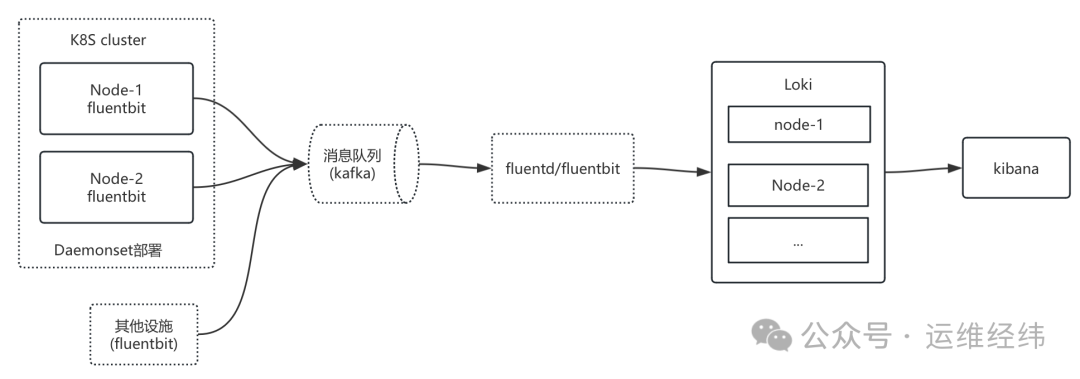
(注:Fluent Bit 插件生态丰富,若其内置功能仍无法满足特定需求,可以考虑功能更强大的 Fluentd 作为补充。)
方案实施与落地
能落地的方案才是好方案。接下来,我们看看如何一步步部署一套属于自己的 FLG 服务。本次实践的背景如下:
- 基础设施基于阿里云平台,服务部署在 ACK(阿里云 Kubernetes)集群中。
- 业务日志已做标准化规范,所有应用日志统一输出到指定路径,文件以
.log 结尾。
- 为控制成本,采用 OSS 作为 Loki 的日志存储后端。
- 测试环境为简化架构,不引入消息队列,由 Fluent Bit 直接写入 Loki。
Loki 部署
首先部署 Loki,因为如果存储后端未就绪,Fluent Bit 启动后会因无法写入而报错。Loki 支持多种部署模式以适应不同场景:
- 单进程模式:所有组件运行于单个进程内,通过配置启用功能。适用于开发、测试或日志量小、高可用要求低的场景。
- 简单可扩展模式:核心组件拆分开但架构简化,依赖云原生对象存储(如 S3/OSS)或 MinIO。组件可独立扩缩容,适用于中等规模生产环境。
- 完整微服务模式:所有组件完全独立部署,支持高可用、水平扩展和复杂功能(如日志告警、索引分片),适用于超大规模生产集群。
这里我们选择部署“简单可扩展模式”,采用 Helm 方式进行。
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm pull grafana/loki #拉取到本地,修改默认配置
tar fxvz loki-6.44.0.tgz
进入解压后的目录,根据实际环境修改 values.yaml 文件。例如,启用 ServiceAccount 并配置 OSS 作为存储:
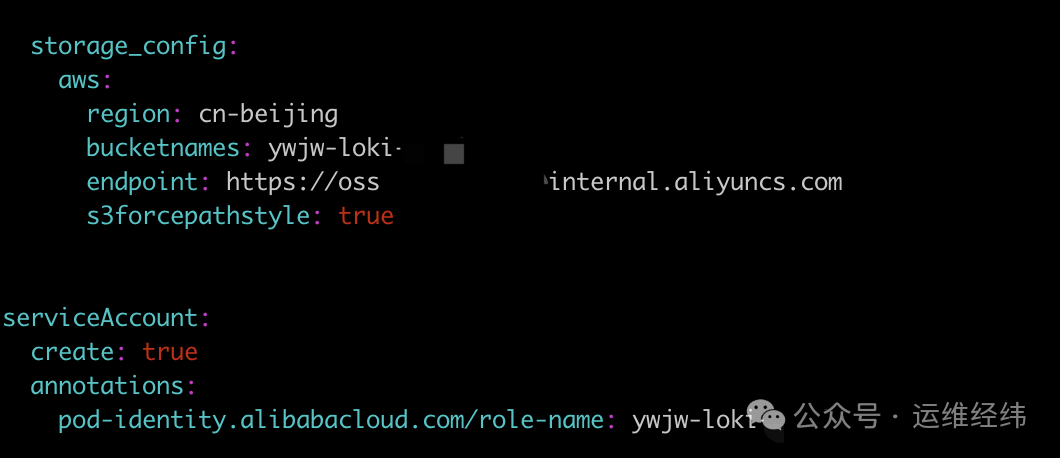
同时,需要为 read 和 write 组件配置持久化存储,用于缓存等数据:
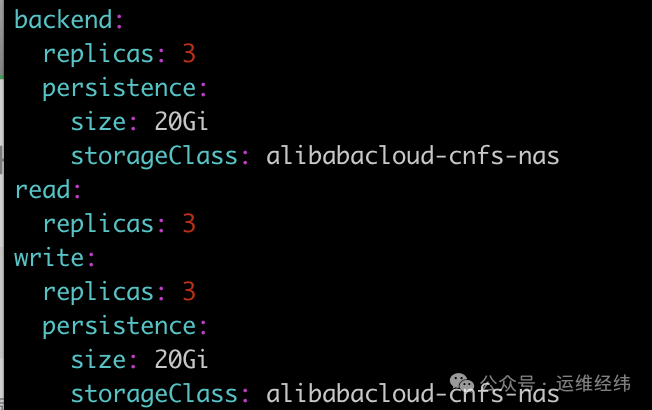
配置确认无误后,执行安装命令:
kubectl create namespace loki-test
helm install --values simple-scalable-values.yaml -n loki-test loki ./
查看部署状态:
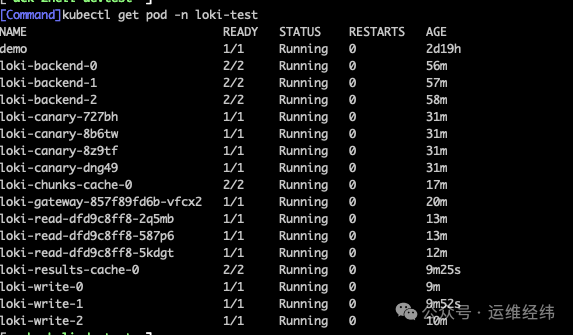
如果需要调整配置,可以编辑对应的 ConfigMap。测试稳定后,可以考虑关闭 canary(金丝雀)组件以节省资源。
Fluent Bit 部署
在 Kubernetes 中采集日志,通常有两种主流模式:
- Sidecar 模式:在每个业务 Pod 中注入一个 Fluent Bit 容器。优点是与应用强绑定,配置隔离性好;缺点是资源消耗较高,增加集群总体负载和成本。
- DaemonSet 模式:在每个节点上部署一个 Fluent Bit 实例,通过挂载宿主机目录(如
/var/log/containers)来采集该节点上所有 Pod 的日志。优点是资源利用率高,管理简单;缺点是所有 Pod 共享同一套采集配置。
本例中,我们采用更通用的 DaemonSet 方式进行部署。
helm repo add fluent https://fluent.github.io/helm-charts
helm install --dry-run --debug -n loki-test fluent-bit fluent/fluent-bit
通过 --dry-run 预览配置后,编辑生成的或自定义的配置文件,关键片段如下:
[INPUT]
Name tail
Path /var/log/containers/*.log
multiline.parser docker, cri
Tag kube.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
[FILTER]
Name kubernetes
Match kube.*
Merge_Log Off
Keep_Log On
K8S-Logging.Parser Off
K8S-Logging.Exclude Off
[FILTER]
Name modify
Match kube.*
Remove _p
Remove stream
Remove kubernetes
[OUTPUT]
Name Loki
Match kube.*
Host loki-write.loki-test.svc.cluster.local
Port 3100
配置文件更新后,需要重启 Fluent Bit 的 Pod 以使配置生效。
Grafana 部署
Grafana 的安装同样简单,使用 Helm 即可快速完成。
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install grafana grafana/grafana -n loki-test
根据需求决定是否修改默认配置,例如设置持久化存储、修改默认密码等。部署完成后,获取 Grafana 的访问地址(通常是 LoadBalancer 类型的 Service 或 Ingress),添加 Loki 数据源(地址为 http://loki-gateway.loki-test.svc.cluster.local),即可开始体验完整的日志查询功能。
在 Grafana Explore 界面使用 LogQL 查询日志的效果如下:
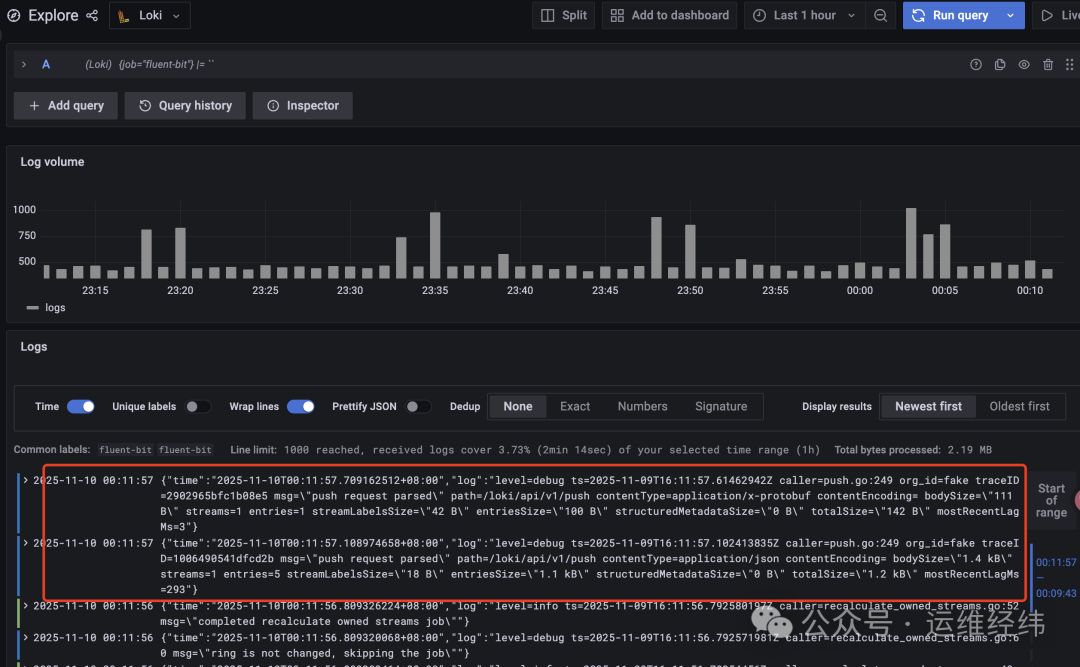
最后,有一个重要的实践细节需要注意:在 Kubernetes 环境中,如果 Pod 没有配置持久化存储,其内部产生的日志会随着 Pod 的销毁而消失。如果 Pod 异常终止(Crash),末端的部分日志可能来不及被采集器读取。因此,对于日志完整性要求极高的场景,建议考虑对 Pod 内的日志目录进行“临时持久化”挂载(如使用 emptyDir),确保日志被成功采集后再由日志轮转或清理策略处理。
结语
从 ELK 到 FLG,不仅仅是一次技术组件的替换,更是一次面向云原生时代的运维架构思维进化。它旨在用更低的资源成本、更高的处理效率和更简洁的运维复杂度,重新定义日志系统的核心价值。当然,架构选型没有银弹,最终选择 ELK 还是 FLG,抑或其他方案,都取决于你具体的业务场景、团队技术栈和成本预算。
希望这篇关于轻量化日志方案 FLG 的实践分享,能为你提供有价值的参考。如果在实践中遇到问题,欢迎在云栈社区与其他开发者交流探讨!
 发表于 2026-4-12 04:20:58
|
查看: 152|
回复: 0
发表于 2026-4-12 04:20:58
|
查看: 152|
回复: 0
