最近,我封装了一个专门用于Linux性能分析的AI技能(Skill),可以直接上手使用。
这个技能主要面向运维场景,当你需要深度分析某台Linux设备(无论是ARM还是x86架构)的性能瓶颈时,它就能派上用场。这让我想起之前制作的Linux性能调试与优化系列视频。没错,这个技能正是对系列核心内容的精炼与浓缩。当然,受限于AI技能的上下文长度,它只包含了最关键的部分,算是一个高效的“速查手册”。
那么,具体该怎么用呢?
使用场景与方法
在真实的Linux运维环境中,你通常无法在被管理的服务器上直接安装Claude Code这类AI工具,这往往会违反公司的安全策略,带来不小的隐患。
但是,就像运维工程师通过SSH登录目标机器一样,你也可以配置Claude Code通过SSH连接到目标设备,然后远程执行Skill中预设的命令来完成性能分析。其工作流程大致如下图所示:
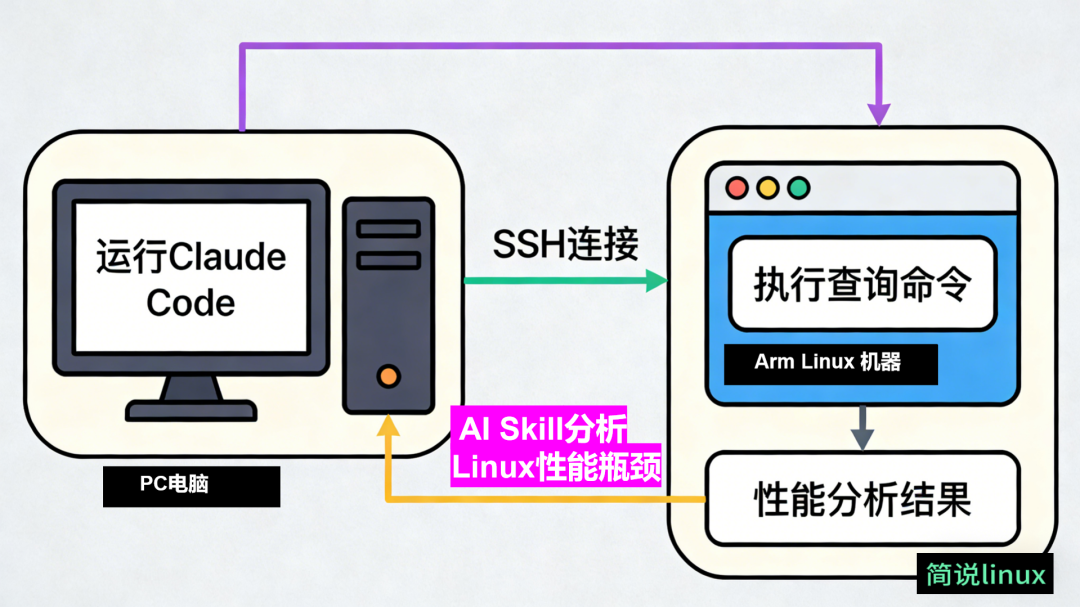
下面,我们来实际演示一遍。
实战演示
第一步:在Claude Code中配置SSH MCP服务器
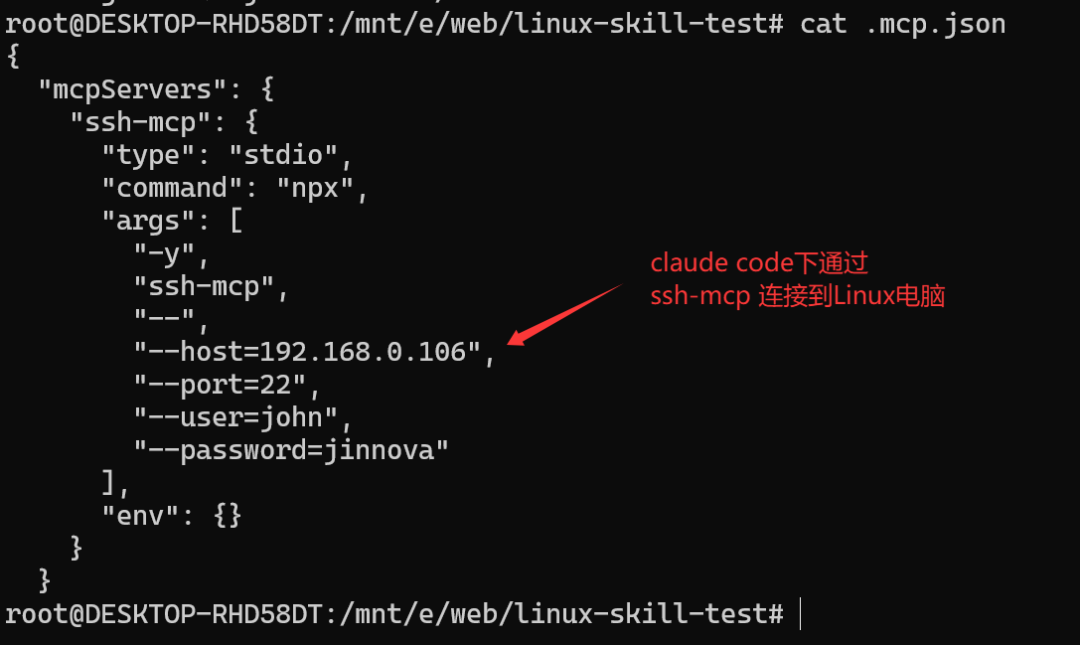
首先,你需要在Claude Code的项目目录中创建一个名为 .mcp.json 的配置文件,用于建立SSH连接。配置文件内容如下:
{
"mcpServers": {
"ssh-mcp": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"ssh-mcp",
"--",
"--host=192.168.0.106",
"--port=22",
"--user=john",
"--password=jinnova"
],
"env": {}
}
}
}
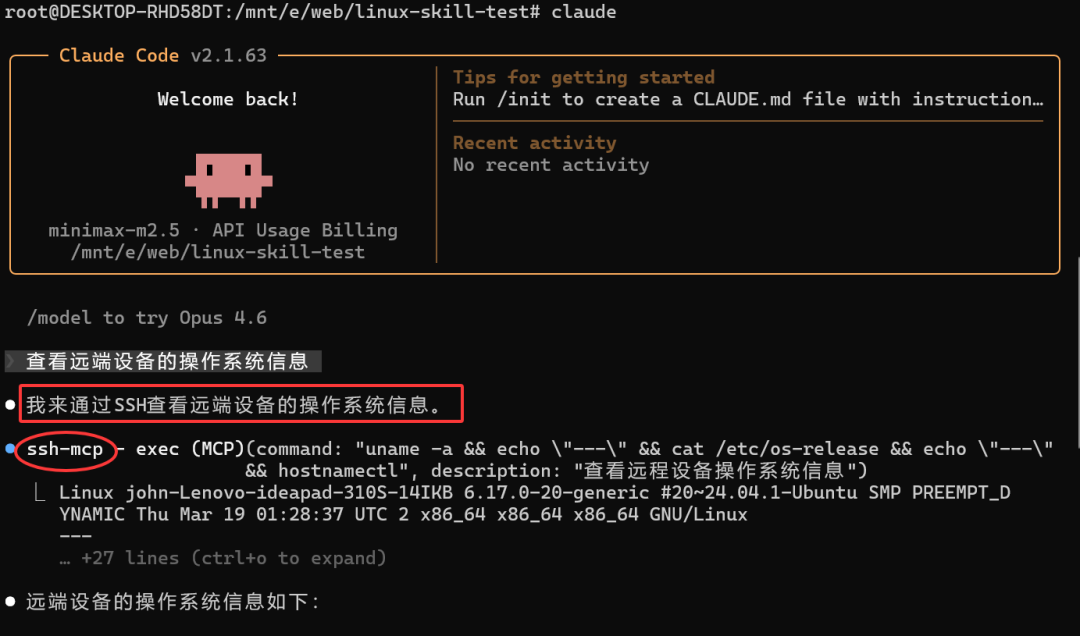
第二步:测试SSH连接并获取系统信息
启动Claude Code,通过简单的对话即可测试SSH连接是否正常,并获取远端设备的基础信息。
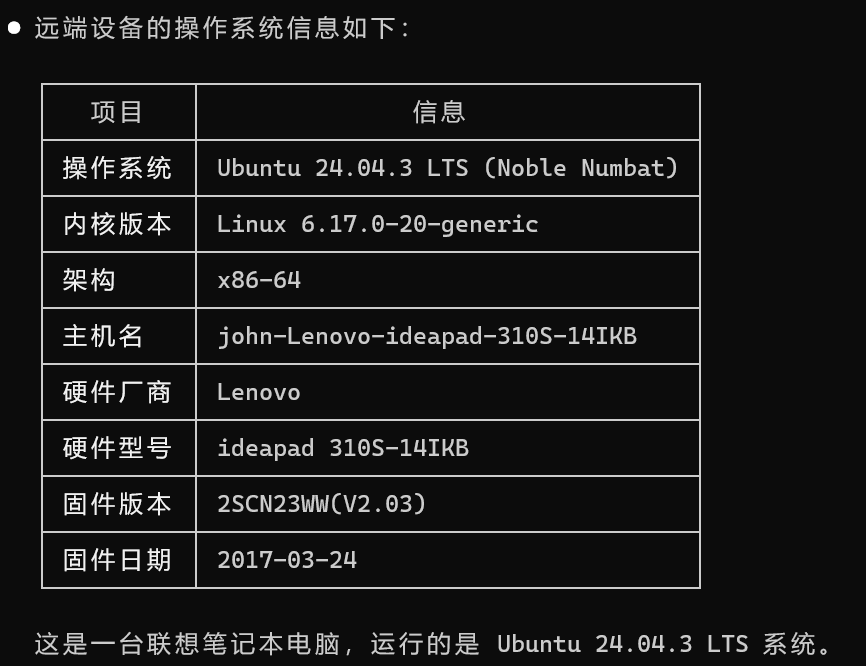
连接成功后,AI会返回清晰的系统信息汇总:
第三步:调用Linux性能分析Skill
核心操作来了。你只需要向AI发出指令 “分析远端设备的性能瓶颈”,即可触发加载并运行 linux-performance-analysis 这个技能。
AI会依次执行一系列性能采集命令(如 uptime, top, pidstat, free, iostat, netstat 等),最后生成一份结构化的四维度分析报告。
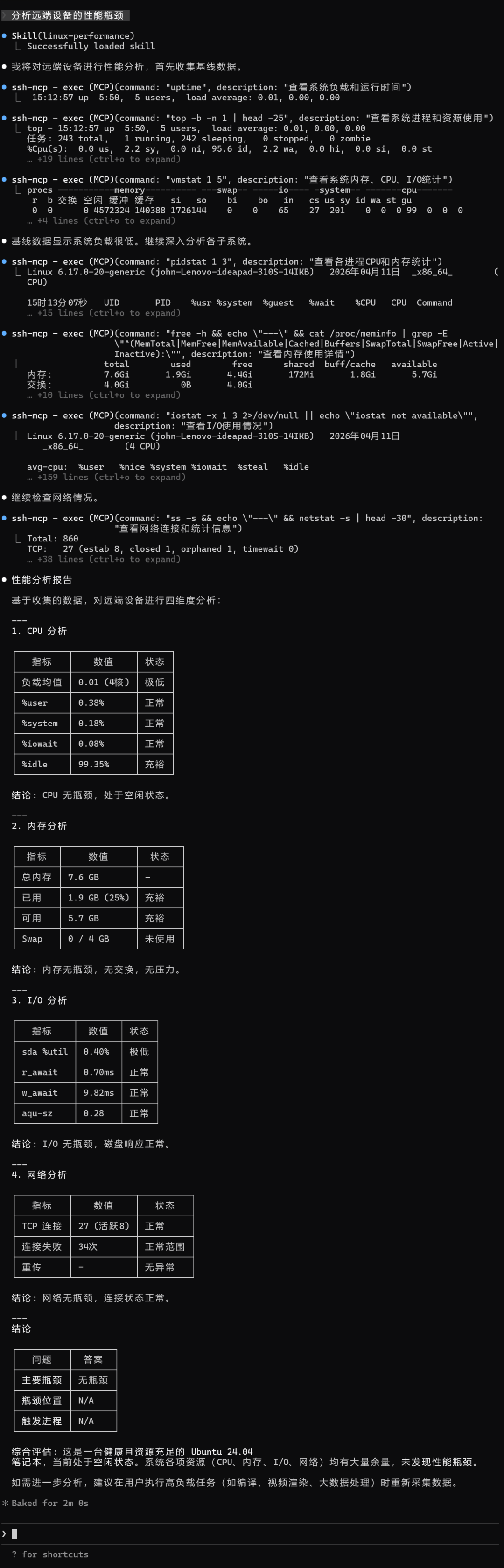
这份报告旨在清晰回答运维中最关心的三个核心问题:
- 主要性能瓶颈是CPU、内存、I/O还是网络?
- 瓶颈主要出现在内核空间还是应用空间?
- 如果问题在应用层,具体是哪个进程引发的?
技能原理与源码结构
那么这个技能是如何工作的?我们来看看它的代码结构。除了 README.md,整个技能由6个文件构成:
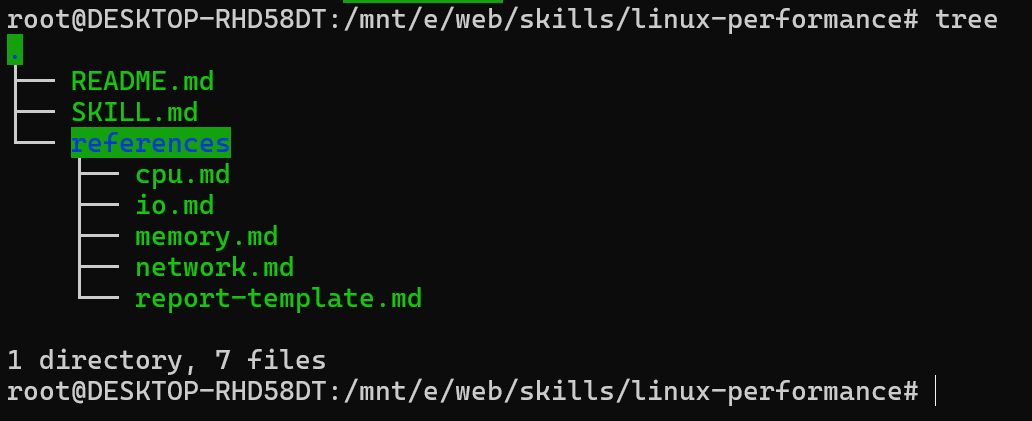
SKILL.md:这是技能的核心定义文件。它规定了技能的名称、描述、工作流程,并特别强调了“侵入性原则”——将命令分为L1(只读)、L2(受限)、L3(需确认)三个安全等级。文件还定义了基线检查方法、各维度的性能分析规则、内核/用户空间瓶颈的判别逻辑,并引用了下方的参考文件。references/ 目录:包含四个维度的详细分析指南(cpu.md, memory.md, io.md, network.md)以及最终报告的模板(report-template.md)。例如,cpu.md 中详细说明了从系统负载到进程深度排查的完整思路,包括如何区分内核态和用户态的CPU开销。
总得来说,这个技能的实现原理就是将系统化的性能分析知识转化为AI可执行的、标准化的操作流程。虽然为了适配AI上下文做了浓缩,可能丢失一些细节,但其优势在于:当目标机器缺少某些性能工具时,Claude Code 可以尝试协助安装(当然,这需要使用者自行评估风险)。
这个技能本质上是对复杂运维知识的一次工程化封装与尝试,相关的开源实战经验也值得在社区中分享探讨。
获取与反馈
如果你对这个技能感兴趣,可以访问以下地址获取源码:
https://github.com/simple-tec/linux-performance-annlysis-skill
欢迎大家自由学习、修改和使用。如果你在使用过程中有任何问题或建议,也欢迎在项目中提交Issue进行反馈。希望这个工具能为你排查Linux性能问题带来一些新的思路和效率提升。也欢迎到云栈社区的运维板块交流更多实战经验。
 发表于 2026-4-13 04:08:08
|
查看: 379|
回复: 0
发表于 2026-4-13 04:08:08
|
查看: 379|
回复: 0
