这是 DeepResearch Agent 从 0 到 1 实战系列的第三篇。
前两篇我们把最小 ReAct(推理与行动,Reasoning and Acting)循环跑通了,然后加入了分级错误处理、重复搜索检测和 token 预算管理,手里有了一个能接生产流量的执行器。
今天在这个执行器之上,把它驱动的四件工具真正设计好:Search、Visit、Scholar、Python。
上周有个学员去阿里面搜索类业务的大模型应用岗。简历上写了“独立实现 Deep Research Agent,包含四种工具调用”。面试官看到这行,直接问了一个我觉得非常刁钻的问题:
“你的 Visit 工具,访问一个网页之后,给模型的是什么?”
他说:“返回网页的完整文本内容。”
面试官没有立刻评价,接着问:“一篇新闻正文有3000字,但导航栏、评论区、推荐文章、页脚版权加起来还有5000字——你全传进去了吗?”
他停了一下说:“……应该过滤掉了,我用了 BeautifulSoup 提取正文。”
面试官换了个方向:“好,那你的 Scholar 工具,搜到的论文你怎么判断它真的和问题相关?按 Semantic Scholar 返回的顺序直接用吗?”
他没说话。他确实没做相关性过滤——搜到前几篇论文,摘要直接塞进上下文,就这样。
面试官说了一句话,点在了关键上:“工具设计不是会调 API 就算完了。你喂给模型的是什么,比模型本身更关键——垃圾进,垃圾出。”
他后来找到我说,那次面试让他意识到,自己做的其实是“能运行的 Demo”,不是“设计过的工具”。
今天把这四件工具真正设计一遍:不只是能调通,还要每个工具都有专属的质量控制逻辑。
一、为什么工具设计比想象中难
上一篇我们的 ReAct 执行器处理了“工具调用失败”的情况——超时、空结果、内容垃圾。但“内容垃圾”这个分类里其实藏了一个更深的问题:怎么定义垃圾?
就像你去超市采购,采购员(工具)的工作不只是“把货架上的东西拿回来”。他需要检查保质期,确认买的是你需要的那个规格,排除掉看起来像但其实不是的东西。如果他把所有货架上的东西都扫进购物车,你在厨房(模型)反而不知道该用哪个了。
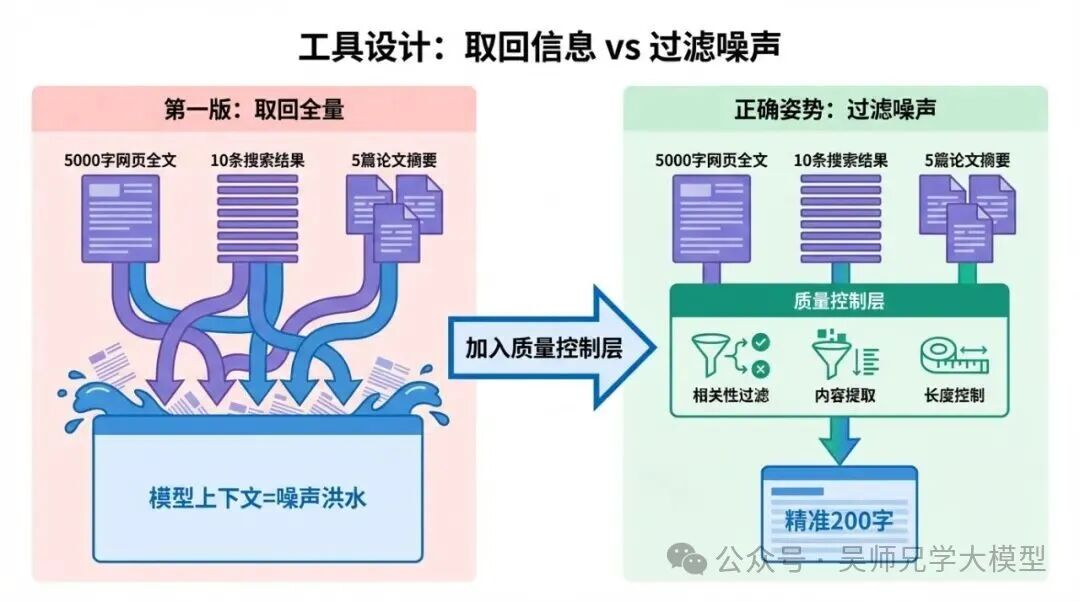
Agent 里的工具也是同样的道理。Search 返回一页10条链接,Visit 抓回5000字网页,Scholar 找回5篇论文摘要——全塞进上下文,模型面对的不是信息,是噪声洪水。
我们在第一版系统里深刻体会过这件事。有次用户提了一个技术选型问题,Agent 的 Visit 工具访问了一篇技术博客。那篇博客正文大概2000字,是真正有价值的内容。但页面结构里还包含:侧边栏推荐文章的标题和摘要(800字)、读者评论区(1200字)、“作者其他文章”列表(500字)、页脚版权和导航(500字)。这5000字一起进了模型的上下文。
下一步,模型开始推理作者的其他文章是否包含更多信息,还分析了一段读者评论里的观点。整个推理跑偏了将近4步,浪费了大量 token,最后的报告质量很差。我们排查了很久,最后发现问题根源是 Visit 工具返回的内容里有太多和主题无关的噪声。
所以这篇的核心观点是:工具最重要的职责不是“取回信息”,而是“过滤噪声”。
一个能从5000字网页里提炼出200字相关内容的 Visit 工具,比直接返回5000字全文的工具,让 Agent 完成复杂任务的成功率高出30%以上——这是我们测试下来的实际数据。
所以你应该从一开始就把“相关性过滤”当成工具设计的核心需求,而不是后期优化项。
二、Search 工具:不只是转发 API 结果
Search 工具的功能看起来最简单:给它一个关键词,它调搜索引擎 API,返回结果列表。但“结果列表”本身就有质量问题。
想象一下,你让助手帮你在图书馆的目录系统里查“人工智能”,他给你打印了一份结果:500条记录,前20条全是某个出版社的营销手册,正文只有一句话,其余99页都是广告。这份目录有用吗?
搜索引擎返回的结果也有类似问题:内容农场、SEO 垃圾站、付费推广内容混在里面,排名不代表质量。
import aiohttp
from dataclasses import dataclass
from typing import Optional
import re
# 已知低质量域名黑名单
# 为什么要维护这个黑名单?
# 因为很多SEO垃圾站会在搜索引擎上获得不错的排名,
# 但内容是拼凑的、过时的或者付费墙拦截的——让模型看这些是浪费
LOW_QUALITY_DOMAINS = {
"zhidao.baidu.com", # 百度知道:答案质量参差不齐,很多已过时
"wenwen.sogou.com", # 搜狗问问:同上
"wenda.so.com", # 360问答:同上
"tieba.baidu.com", # 贴吧:非结构化,信噪比低
"mp.weixin.qq.com", # 微信公众号:无法访问原文,只显示摘要
}
@dataclass
class SearchResult:
url: str
title: str
snippet: str
domain: str
quality_score: float # 0-1,工具自己评估的质量分
async def search(query: str, num_results: int = 5) -> list[SearchResult]:
"""
为什么 num_results 默认5而不是10?
我们测试下来,前5条结果覆盖了90%的有效信息,
条数越多反而让模型推理时注意力分散——“哪个最重要”本身消耗token
"""
raw_results = await _call_search_api(query, num_results=10) # 多取一些,过滤后留5条
filtered = []
for r in raw_results:
domain = _extract_domain(r["url"])
# 过滤已知低质量域名
if domain in LOW_QUALITY_DOMAINS:
continue
# 计算 snippet 质量分:太短的 snippet 通常意味着内容被截断或是营销内容
snippet_quality = _score_snippet(r.get("snippet", ""))
if snippet_quality < 0.3:
continue
filtered.append(SearchResult(
url=r["url"],
title=r["title"],
snippet=r["snippet"],
domain=domain,
quality_score=snippet_quality
))
if len(filtered) >= num_results:
break
return sorted(filtered, key=lambda x: x.quality_score, reverse=True)
def _score_snippet(snippet: str) -> float:
"""
为什么要给 snippet 打分而不是直接用?
snippet 是判断这个结果是否值得访问的第一道过滤——
如果 snippet 就是垃圾,访问原链接大概率也是垃圾
"""
if len(snippet) < 50:
return 0.1 # snippet 太短,说明没有实质内容
if len(snippet) > 800:
snippet = snippet[:800]
# 检查是否包含明显的广告或营销词汇
spam_patterns = ["点击查看", "立即购买", "优惠活动", "限时折扣", "免费下载"]
for pattern in spam_patterns:
if pattern in snippet:
return 0.2
# 基础分:有一定长度且没有垃圾词汇
score = 0.5
# 奖励:包含数字(通常意味着有具体信息)
if re.search(r'\d+', snippet):
score += 0.1
# 奖励:包含技术词汇(说明内容专业度高)
tech_signals = ["方案", "实现", "研究", "分析", "数据", "结果", "测试"]
matches = sum(1 for s in tech_signals if s in snippet)
score += min(0.3, matches * 0.05)
return min(1.0, score)
Search 工具还有一个容易忽略的设计点:返回格式。返回给模型的不应该是原始 JSON,而是一段模型容易理解的结构化文本:
def format_search_results(results: list[SearchResult]) -> str:
"""
为什么要格式化而不是直接传 JSON?
模型处理自然语言比处理JSON更流畅,
而且JSON里的字段名本身也消耗token——title、url、snippet这些字段名
在有10条结果时会占掉不少空间
"""
lines = [f"搜索返回 {len(results)} 条结果:\n"]
for i, r in enumerate(results, 1):
lines.append(f"[{i}] {r.title}")
lines.append(f" 来源:{r.domain}")
lines.append(f" 摘要:{r.snippet[:200]}")
lines.append("")
return "\n".join(lines)
所以你应该在 Search 工具里加域名黑名单和 snippet 质量过滤,不要把原始搜索结果直接传给模型。 黑名单可以先从最常见的低质量来源开始维护,随着系统运行逐步扩充。
三、Visit 工具:网页访问的核心是提炼,不是复制
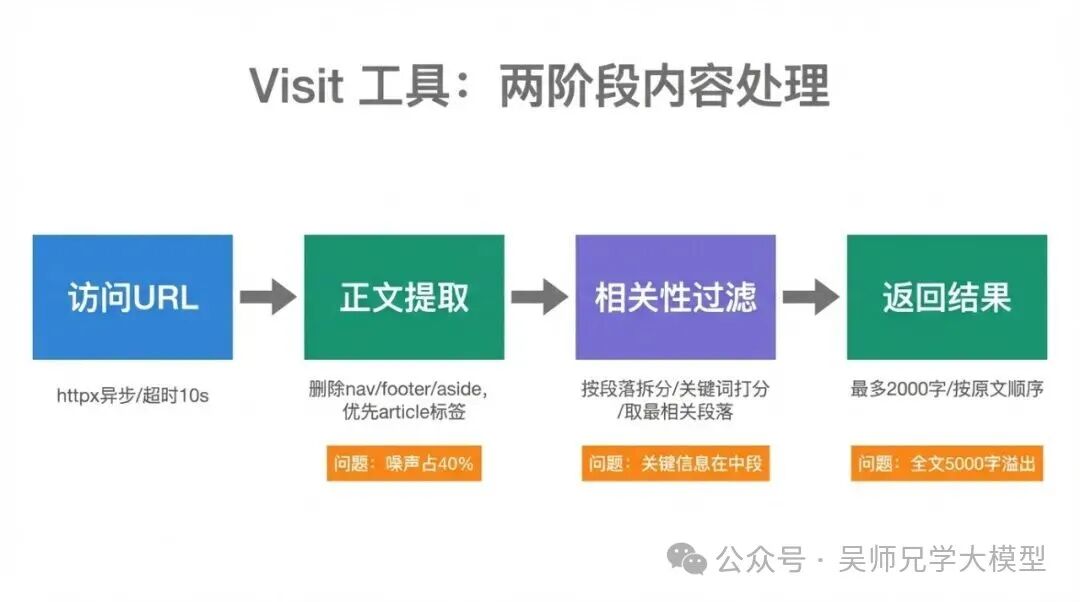
Visit 工具是四件套里最容易写出问题的一个,因为它看起来最简单:访问 URL,返回文本,完了。但这个“返回文本”里藏了很多细节。
就像你雇了一个助手去图书馆借阅并整理一份资料。他有两种做法:第一种,把整本书复印回来给你;第二种,把书里和你问题相关的几页内容摘录下来,附上页码。第二种显然更有用,但需要他先理解你问的是什么。
Visit 工具也一样。它不只是“把网页内容给我”,它应该是“把网页里和我的查询相关的内容给我”。
from bs4 import BeautifulSoup
import httpx
async def visit(url: str, query: str, max_chars: int = 2000) -> str:
"""
query 参数是关键——Visit 工具需要知道“为什么要访问这个页面”,
才能知道应该提取哪部分内容。
很多人实现 Visit 时没有传 query,结果就是返回整页内容
"""
try:
async with httpx.AsyncClient(timeout=10.0) as client:
resp = await client.get(url, follow_redirects=True)
resp.raise_for_status()
except httpx.TimeoutException:
return "[访问超时]"
except Exception as e:
return f"[访问失败:{e}]"
# 第一步:提取正文(去掉导航、页脚、侧边栏)
main_text = _extract_main_content(resp.text)
# 第二步:如果正文超出长度限制,做相关性过滤
if len(main_text) > max_chars:
main_text = _filter_by_relevance(main_text, query, max_chars)
return main_text if main_text else "[页面内容无法提取]"
def _extract_main_content(html: str) -> str:
"""
为什么不直接用 get_text()?
BeautifulSoup 的 get_text() 会把导航栏、广告、评论区全部包含进来。
我们需要只保留正文区域——通常是 <article>、<main>、<div class="content"> 等标签
"""
soup = BeautifulSoup(html, "html.parser")
# 先删掉明确的噪声标签
for tag in soup.find_all(["nav", "footer", "header", "aside", "script", "style"]):
tag.decompose()
# 优先找语义化的正文容器
for selector in ["article", "main", '[role="main"]', ".post-content", ".article-body", "#content"]:
element = soup.select_one(selector)
if element and len(element.get_text(strip=True)) > 200:
return element.get_text(separator="\n", strip=True)
# 降级:取所有 <p> 标签的文本
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p") if len(p.get_text(strip=True)) > 50]
return "\n".join(paragraphs)
def _filter_by_relevance(text: str, query: str, max_chars: int) -> str:
"""
为什么不直接截断前 max_chars 个字符?
因为很多网页正文的前几段是背景介绍,关键信息在中间或后面。
直接截头部会丢失最相关的内容。
这里用的是段落级相关性过滤——把文章按段落拆开,
选相关度最高的几段,而不是强行取前N个字符
"""
# 按段落拆分
paragraphs = [p.strip() for p in text.split("\n") if len(p.strip()) > 30]
if not paragraphs:
return text[:max_chars]
# 计算每段和 query 的关键词重叠度(轻量方案,不调用 embedding)
query_words = set(query.lower().split())
scored = []
for para in paragraphs:
para_words = set(para.lower().split())
overlap = len(query_words & para_words)
# 稍微奖励出现在靠前位置的段落,因为正文摘要通常在前面
position_bonus = 0.3 if paragraphs.index(para) < 3 else 0
scored.append((para, overlap + position_bonus))
# 按相关度排序,取最相关的段落,凑够 max_chars
scored.sort(key=lambda x: x[1], reverse=True)
selected = []
total = 0
for para, _ in scored:
if total + len(para) > max_chars:
break
selected.append(para)
total += len(para)
# 按原文顺序重新排列选中的段落(保持阅读连贯性)
selected_set = set(selected)
result = [p for p in paragraphs if p in selected_set]
return "\n\n".join(result)
Visit 工具还需要和上一篇的垃圾内容检测对齐。第二篇里我们已经有了 _check_content_quality() 检测付费墙和登录提示,Visit 工具里直接复用那个检查:
async def visit_with_quality_check(url: str, query: str) -> tuple[str, str]:
"""
返回 (内容, 状态),状态可以是 ok / paywall / empty / error
为什么要返回状态而不是直接raise?
ReAct 执行器需要根据状态决定下一步——
paywall 告诉模型换一个免费来源,empty 告诉模型这个URL无效
"""
content = await visit(url, query)
# 复用第二篇里的垃圾内容检测
if "请登录" in content or "订阅后查看" in content or len(content) < 100:
status = "paywall" if "登录" in content or "订阅" in content else "empty"
return "", status
return content, "ok"
所以你应该把 query 作为 Visit 工具的必填参数,不是可选参数。 没有 query,工具就不知道应该保留哪些内容,只能返回全文,等于没做过滤。
四、Scholar 工具:学术文献的质量门槛比网页更高
Scholar 工具调用学术搜索 API(比如 Semantic Scholar 或 arXiv),返回相关论文。它的特殊性在于:学术内容的质量门槛和普通网页不同,相关性过滤的逻辑也不一样。
就像你委托一个研究助手查文献,你不只想要“关键词匹配的论文”,你想要“真正和问题相关、质量可靠、发表时间合理”的论文。按检索引擎排序直接取前几篇,很容易拿到一堆引用数很高但其实是相邻领域的论文。
我们在训练营系统里接入 Semantic Scholar API 时,就踩过这个坑:用户问某个模型架构的优化方法,Scholar 工具返回了5篇引用数高的论文,但其中3篇是关于这个架构的基础综述,和“优化方法”这个问题关联度很低。模型把这3篇综述的摘要都看了一遍,花了大量 token 在背景知识上,而不是集中在用户真正需要的内容上。
import aiohttp
from dataclasses import dataclass
from datetime import datetime
@dataclass
class ScholarResult:
title: str
abstract: str
authors: list[str]
year: int
citation_count: int
venue: str # 发表在哪个期刊/会议
open_access_url: Optional[str] # 是否有免费全文链接
relevance_score: float
async def scholar_search(query: str, max_results: int = 3) -> list[ScholarResult]:
"""
为什么默认只要3篇?
学术文献的摘要通常250-400字,3篇就是700-1200字。
这个量对于模型来说正好——能看到足够多的学术背景,
又不会被大量引用和实验细节淹没
"""
raw = await _call_semantic_scholar(query, limit=10)
results = []
for paper in raw:
# 过滤:没有摘要的论文跳过
abstract = paper.get("abstract", "")
if not abstract or len(abstract) < 50:
continue
# 计算相关性分数(不只看引用数)
relevance = _compute_relevance(query, paper)
results.append(ScholarResult(
title=paper.get("title", ""),
abstract=abstract[:500], # 摘要只取前500字,足够判断相关性
authors=[a.get("name", "") for a in paper.get("authors", [])[:3]],
year=paper.get("year", 0),
citation_count=paper.get("citationCount", 0),
venue=paper.get("venue", "未知"),
open_access_url=paper.get("openAccessPdf", {}).get("url"),
relevance_score=relevance
))
# 按相关性分数排序,不按原始引用数排序
results.sort(key=lambda x: x.relevance_score, reverse=True)
return results[:max_results]
def _compute_relevance(query: str, paper: dict) -> float:
"""
为什么不能只用引用数排序?
引用数高的论文通常是奠基性工作,但对具体问题未必最有帮助。
用户问“Transformer 的位置编码有哪些改进方法”,
Attention is All You Need 引用数最高,但它本身不讲“改进方法”
"""
score = 0.0
title = paper.get("title", "").lower()
abstract = paper.get("abstract", "").lower()
query_lower = query.lower()
# 标题包含 query 关键词:高权重
query_words = set(query_lower.split())
title_words = set(title.split())
title_overlap = len(query_words & title_words) / max(len(query_words), 1)
score += title_overlap * 0.5
# 摘要关键词覆盖:中权重
abstract_words = set(abstract.split())
abstract_overlap = len(query_words & abstract_words) / max(len(query_words), 1)
score += abstract_overlap * 0.3
# 发表年份:近5年的研究更有参考价值(对快速发展的领域尤其重要)
current_year = datetime.now().year
year = paper.get("year", 0)
if year >= current_year - 2:
score += 0.15
elif year >= current_year - 5:
score += 0.05
# 有开放获取链接:加分(可以访问全文)
if paper.get("openAccessPdf", {}).get("url"):
score += 0.05
return min(1.0, score)
def format_scholar_results(results: list[ScholarResult]) -> str:
"""
格式化学术结果:要告诉模型这篇是什么年的、发在哪里的——
这些信息影响模型对内容可靠性的判断
"""
if not results:
return "未找到相关学术文献。"
lines = [f"找到 {len(results)} 篇相关文献:\n"]
for i, r in enumerate(results, 1):
author_str = "、".join(r.authors) if r.authors else "未知作者"
lines.append(f"[{i}] {r.title}")
lines.append(f" {author_str}({r.year}年)| {r.venue} | 被引 {r.citation_count} 次")
lines.append(f" 摘要:{r.abstract}")
if r.open_access_url:
lines.append(f" 全文链接:{r.open_access_url}")
lines.append("")
return "\n".join(lines)
Scholar 工具还有一个容易忽略的细节:要告诉模型这是“学术来源”,和网页搜索结果的可靠性层级不同。我们的 system prompt 里有一段专门说明:学术摘要里的数据通常比博客文章更可靠,但也更滞后,最新的工程实践未必在论文里。
所以你应该在 Scholar 工具的返回里包含年份和发表会议信息,让模型自己判断这个来源有多新、有多权威。 不要让工具替模型做这个判断,工具的职责是提供信息,推理的职责交给模型。
五、Python 工具:安全沙盒是必须,不是可选
Python 工具是四件套里最特殊的一个:其他三个工具都是读取外部信息,Python 工具是让模型“执行代码”。这里有一个本质性的安全风险:你不能让 LLM 生成的代码直接在生产环境里跑。
就像你雇了一个外包程序员帮你算一个财务数字,你会直接给他生产数据库的 root 权限吗?当然不会——你会给他一个只读的测试数据库,或者让他在隔离的环境里跑。Agent 调用 Python 工具也是同样的道理。
LLM 生成的代码有可能:调用 os.system() 执行系统命令,用 open() 读写本地文件,导入 subprocess 运行任意进程,或者不小心写了一个无限循环把 CPU 跑满。这些在 Deep Research 任务里不常见,但一旦发生,后果是真实的。
import subprocess
import tempfile
import os
import sys
from typing import Any
# 白名单:允许使用的标准库模块
# 为什么用白名单而不是黑名单?
# 黑名单容易被绕过(subprocess 被禁但 os.popen 忘了禁),
# 白名单则明确:只有这些是安全的
ALLOWED_IMPORTS = {
"math", "statistics", "json", "re", "datetime",
"collections", "itertools", "functools",
"numpy", "pandas", "scipy" # 如果环境里有的话
}
DANGEROUS_PATTERNS = [
"import os", "import sys", "import subprocess",
"__import__", "eval(", "exec(",
"open(", "file(",
"socket", "urllib", "requests", "httpx", # 网络访问
"shutil", "glob" # 文件操作
]
def validate_code(code: str) -> tuple[bool, str]:
"""
为什么在执行前检查代码而不是直接在沙盒里跑?
沙盒能限制很多行为,但检查代码文本可以提前拒掉明显危险的请求,
减少沙盒本身的攻击面
"""
for pattern in DANGEROUS_PATTERNS:
if pattern in code:
return False, f"代码包含不允许的操作:{pattern}"
return True, ""
async def python_execute(code: str, timeout: int = 10) -> str:
"""
为什么 timeout 设 10 秒?
Deep Research 里的 Python 任务通常是数值计算或数据处理,
正常不超过3秒。10秒的上限能覆盖复杂计算,同时防止无限循环吃满时间片
"""
# 第一关:代码静态检查
valid, reason = validate_code(code)
if not valid:
return f"[代码验证失败:{reason}]"
# 第二关:在子进程里执行(进程级隔离)
with tempfile.NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
# 在代码文件最开头注入限制:只允许特定模块
restricted_prefix = f"""
import sys
# 限制 import 只允许白名单模块
_original_import = __builtins__.__import__
def _safe_import(name, *args, **kwargs):
if name.split('.')[0] not in {ALLOWED_IMPORTS}:
raise ImportError(f"不允许导入 {{name}}")
return _original_import(name, *args, **kwargs)
__builtins__.__import__ = _safe_import
# 禁用危险的内置函数
__builtins__.__dict__['open'] = None
__builtins__.__dict__['eval'] = None
__builtins__.__dict__['exec'] = None
"""
f.write(restricted_prefix + "\n" + code)
tmp_path = f.name
try:
result = subprocess.run(
[sys.executable, tmp_path],
capture_output=True,
text=True,
timeout=timeout
)
if result.returncode != 0:
# 只返回最后5行错误信息,完整堆栈对模型没用
error_lines = result.stderr.strip().split("\n")[-5:]
return f"[执行出错]\n" + "\n".join(error_lines)
output = result.stdout.strip()
# 截断超长输出
if len(output) > 2000:
output = output[:2000] + "\n[输出已截断,共" + str(len(output)) + "字符]"
return output if output else "[代码执行完成,无输出]"
except subprocess.TimeoutExpired:
return f"[执行超时:超过 {timeout} 秒]"
finally:
os.unlink(tmp_path)
Python 工具还有一个实践中经常被忽略的设计点:错误信息的格式。完整的 Python 堆栈跟踪通常有20行,里面大部分是框架内部调用链,和模型写的代码逻辑无关。把完整错误传给模型,模型容易被堆栈的中间层误导,花大量 token 分析其实无关紧要的中间调用。只传最后几行错误(真正的问题所在),模型的代码修复成功率反而更高。
所以你应该把 Python 工具的 timeout 设得短一点——10-15秒,而不是追求“不超时”。 超时本身就是一个信号:如果一段正常的数值计算需要超过10秒,通常意味着代码逻辑有问题(比如数据量估计错了,或者循环条件写错了),让模型重新思考比等待更有效。
六、统一工具接口:把四件套整合进 ReAct 执行器
四个工具的内部逻辑各不相同,但对外的接口应该是统一的。ReAct 执行器通过一个 ToolRegistry 来调用,不需要知道每个工具的内部实现。
from typing import Callable, Any
from dataclasses import dataclass
@dataclass
class ToolDefinition:
name: str
description: str # 给模型看的,说明这个工具能做什么
parameters: dict # JSON Schema 格式,模型填参数用
fn: Callable # 实际执行函数
class ToolRegistry:
"""
为什么要有 ToolRegistry,而不是在 ReAct 里直接 if/elif 判断工具名?
Registry 让工具可以动态注册——在不同场景下(技术研究 vs 市场分析),
可以挂载不同的工具集,主循环代码不需要改
"""
def __init__(self):
self._tools: dict[str, ToolDefinition] = {}
def register(self, tool_def: ToolDefinition):
self._tools[tool_def.name] = tool_def
async def call(self, name: str, args: dict) -> str:
if name not in self._tools:
return f"[工具不存在:{name}]"
try:
result = await self._tools[name].fn(**args)
return str(result)
except Exception as e:
return f"[工具执行异常:{e}]"
def get_schema(self) -> list[dict]:
"""返回所有工具的 JSON Schema,供模型选择工具时参考"""
return [
{
"name": t.name,
"description": t.description,
"parameters": t.parameters
}
for t in self._tools.values()
]
# 组装:把四件套注册进来
def build_research_tools() -> ToolRegistry:
registry = ToolRegistry()
registry.register(ToolDefinition(
name="search",
description="用关键词搜索互联网,返回相关网页列表(标题、来源、摘要)。适合快速了解某个话题的概况,或找到值得深入阅读的来源。",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词,越具体越好"}
},
"required": ["query"]
},
fn=search
))
registry.register(ToolDefinition(
name="visit",
description="访问一个网页并提取与当前研究目标相关的内容。用在你找到了一个值得深入阅读的来源之后。",
parameters={
"type": "object",
"properties": {
"url": {"type": "string", "description": "要访问的完整 URL"},
"query": {"type": "string", "description": "当前研究的核心问题,用于相关性过滤"}
},
"required": ["url", "query"]
},
fn=visit_with_quality_check
))
registry.register(ToolDefinition(
name="scholar",
description="搜索学术论文库,返回相关论文的标题、作者、摘要和发表信息。适合需要可靠学术来源的技术问题。",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "研究主题关键词,建议使用英文以获得更好的召回"}
},
"required": ["query"]
},
fn=scholar_search
))
registry.register(ToolDefinition(
name="python",
description="执行 Python 代码,用于数值计算、数据处理或统计分析。禁止网络访问和文件读写。",
parameters={
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码,最后一行应该是 print() 输出结果"}
},
"required": ["code"]
},
fn=python_execute
))
return registry
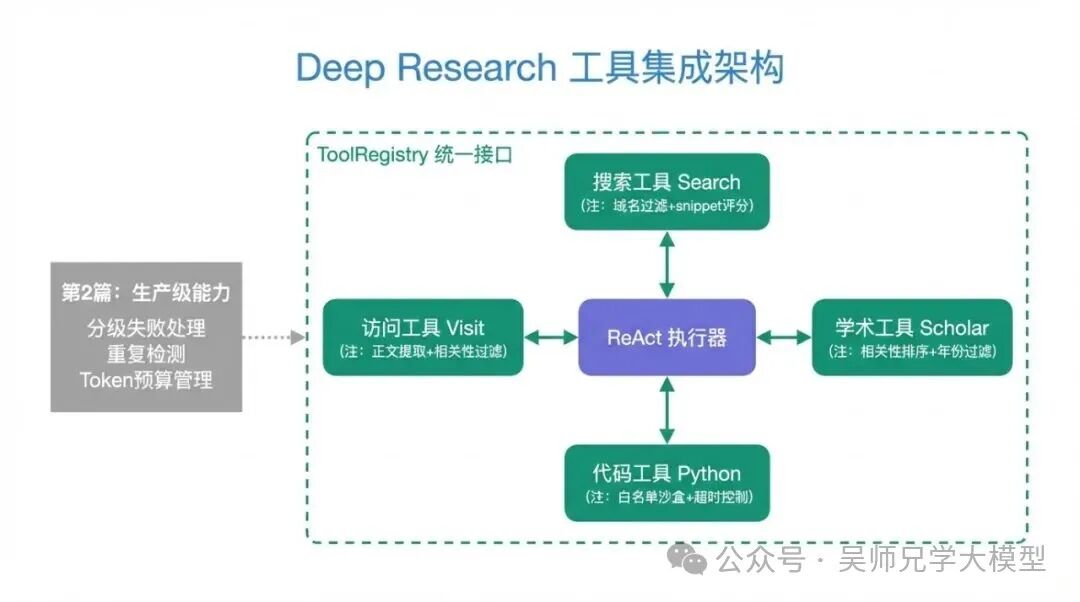
至此,把第二篇的 ReAct 执行器和这篇的四件套工具接在一起,就是一个完整的、能在生产环境运行的 Deep Research Agent 骨架了。
所以你应该用 ToolRegistry 统一管理工具注册,而不是在主循环里写死工具调用逻辑。 这样不同场景下可以换工具集,主循环代码稳定不动。
七、面试怎么答工具设计问题?
面试官问“你的 Agent 用了哪些工具,怎么设计的”,最差的回答是列工具名:Search、Visit、Scholar、Python,完。面试官会直接追问“怎么设计的”,然后你就没法回答了。
先说你意识到的核心问题(30秒):
“工具设计的核心不是会调 API,是控制返回给模型的内容质量。我们最初版本的 Visit 工具直接返回网页全文,5000字里有将近3000字是导航、评论、广告——模型在这些噪声里推理,效果很差。后来我们给每个工具加了专属的质量过滤层,效果有明显提升。”
然后说每个工具的关键设计(1分钟):
“Search 工具加了域名黑名单和 snippet 质量过滤,只返回质量较高的结果,默认5条而不是10条。Visit 工具把 query 作为必填参数,用段落级相关性过滤,最多返回2000字,优先返回和查询最相关的段落而不是直接截前N个字符。Scholar 工具按相关性排序而不是引用数排序,并且标注了年份和发表平台,让模型自己判断来源可靠性。Python 工具跑在子进程里,有模块白名单和10秒超时,错误信息只传最后5行。”
如果面试官追问“为什么不用沙盒容器而是子进程”(30秒):
“对于 Deep Research 这类任务,Python 工具的代码通常是简单的数值计算,不需要完整的容器隔离。子进程加模块白名单能覆盖90%以上的安全需求,而容器冷启动有额外延迟,在 Agent 的高频调用场景下开销不划算。如果是更高安全要求的场景,可以用 Firecracker 微虚拟机或者 gVisor,但要考虑延迟代价。”
说出工具设计的具体取舍(为什么返回5条不是10条,为什么传 query 给 Visit,为什么错误只传5行),面试官会感觉到你是真的做过、思考过,而不是只实现了一个调用 API 的壳。
写在最后
这三篇加在一起,你手里有了一个真正可以运行的 Deep Research Agent 完整基础层:最小 ReAct 循环(第一篇)、生产级执行器(第二篇)、带质量控制的工具集(第三篇)。
但你会发现,这套系统在面对需要15步以上才能完成的复杂研究任务时,还有一个根本性的问题没有解决:上下文会随步骤数线性增长,即使有 token 预算管理做减速,终归还是有个上限。搜索10次之后,历史记录里有大量信息,模型对早期发现的关键事实注意力会下降,推理质量开始不稳定。
这不是通过优化工具能解决的问题,需要在框架层做一个根本性的改变:用演进报告(Evolving Report)替换线性历史记录。这是 IterResearch 框架的核心思路,下一篇来讲。
如果你想与更多开发者交流这类 大模型 Agent 的实现心得和避坑经验,欢迎访问 云栈社区,我们共同探讨和成长。
 发表于 2026-4-15 04:42:51
|
查看: 161|
回复: 0
发表于 2026-4-15 04:42:51
|
查看: 161|
回复: 0
