文生图多模态大模型通过融合视觉与语言模态的深层语义理解,实现了从自然语言描述到高质量图像的智能生成。然而,在实际的评估工作中,图像的保真度与多样性难以兼顾,复杂的空间关系和精准的属性控制存在明显短板。现有的自动化指标与人类审美判断之间存在显著差异,缺乏能够全面反映模型性能的统一测评框架。而在伦理与社会影响维度,数据偏见、版权争议和潜在有害内容生成等问题日益凸显,这些挑战共同制约着技术的健康发展。因此,系统性地评估文生图模型的能力已成为推动其发展的核心议题,而融合自动化工具与人类判断的动态评估框架,将是构建更可靠评估标准的关键。
保真度评估:图像与文本的语义一致性
在文本生成图像的人工智能(AI) 技术中,我们如何判断机器生成的图像“像不像”“真不真”?这离不开一个核心概念——保真度。它衡量的是生成图像与文字描述的语义一致性,以及图像本身的真实感。目前,研究人员主要通过三类方法系统评估保真度。
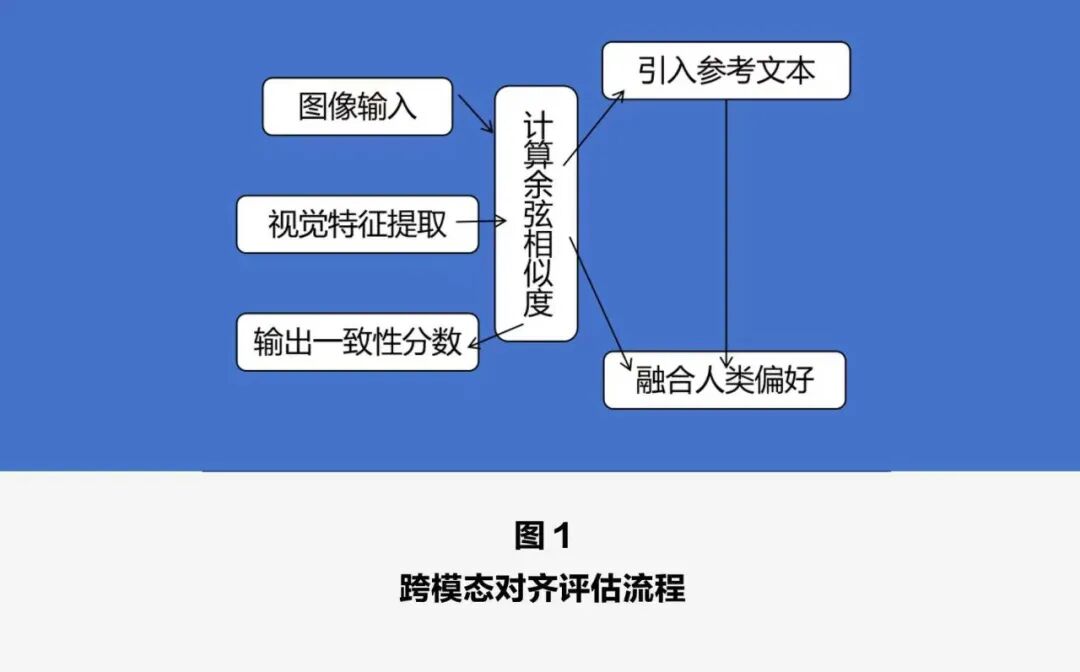
第一类方法称为跨模态对齐评估,其核心是让人工智能自己担任“裁判”。例如,CLIPScore是一种常用的自动化指标,它借助强大的视觉-语言预训练模型,分别提取图像和文本的特征表示,再通过计算它们的余弦相似度来评估二者的一致性。其改进版本RefCLIPScore进一步引入参考文本信息,显著提升了对语义匹配的判断能力,在多项国际标准数据集上的表现都优于传统基于n-gram匹配的评价方法。此外,像ImageReward这类融合人类偏好信号的技术,借助注意力机制优化,能够更精细地捕捉生成图像与复杂文本描述之间的对应关系,尤其在多对象、多属性场景中表现出良好的鲁棒性。
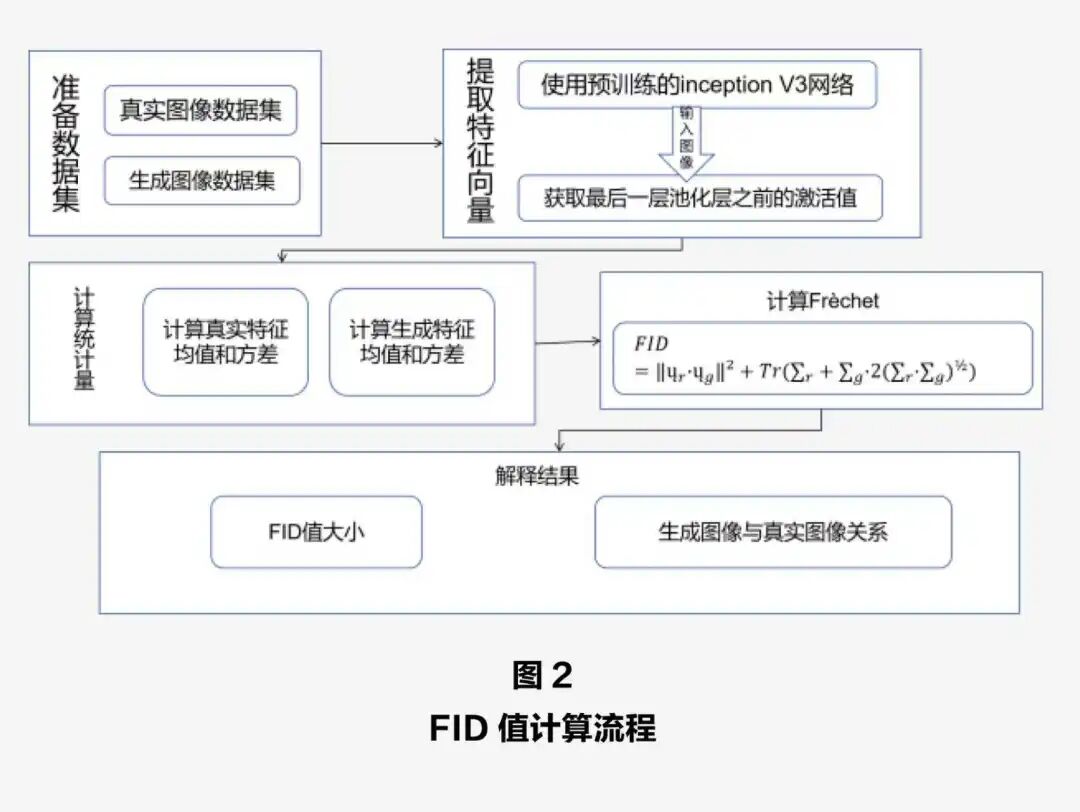
第二类方法聚焦于生成质量量化,重点评估图像本身的视觉真实感和自然度。其中最经典和广泛采用的指标是Fréchet Inception Distance(FID),它通过比较高维特征空间中生成图像与真实图像的分布差异,来判断整体生成质量。FID值越低,代表生成图像越接近真实图像分布。这一指标不仅普遍用于评估生成对抗网络(GANs),也在扩散模型和自回归模型的质量对比中发挥关键作用。除此之外,其他指标如Inception Score(IS)也常被用来衡量图像的清晰度和多样性,但它们更侧重于“视觉质量”而非“语义对齐”。
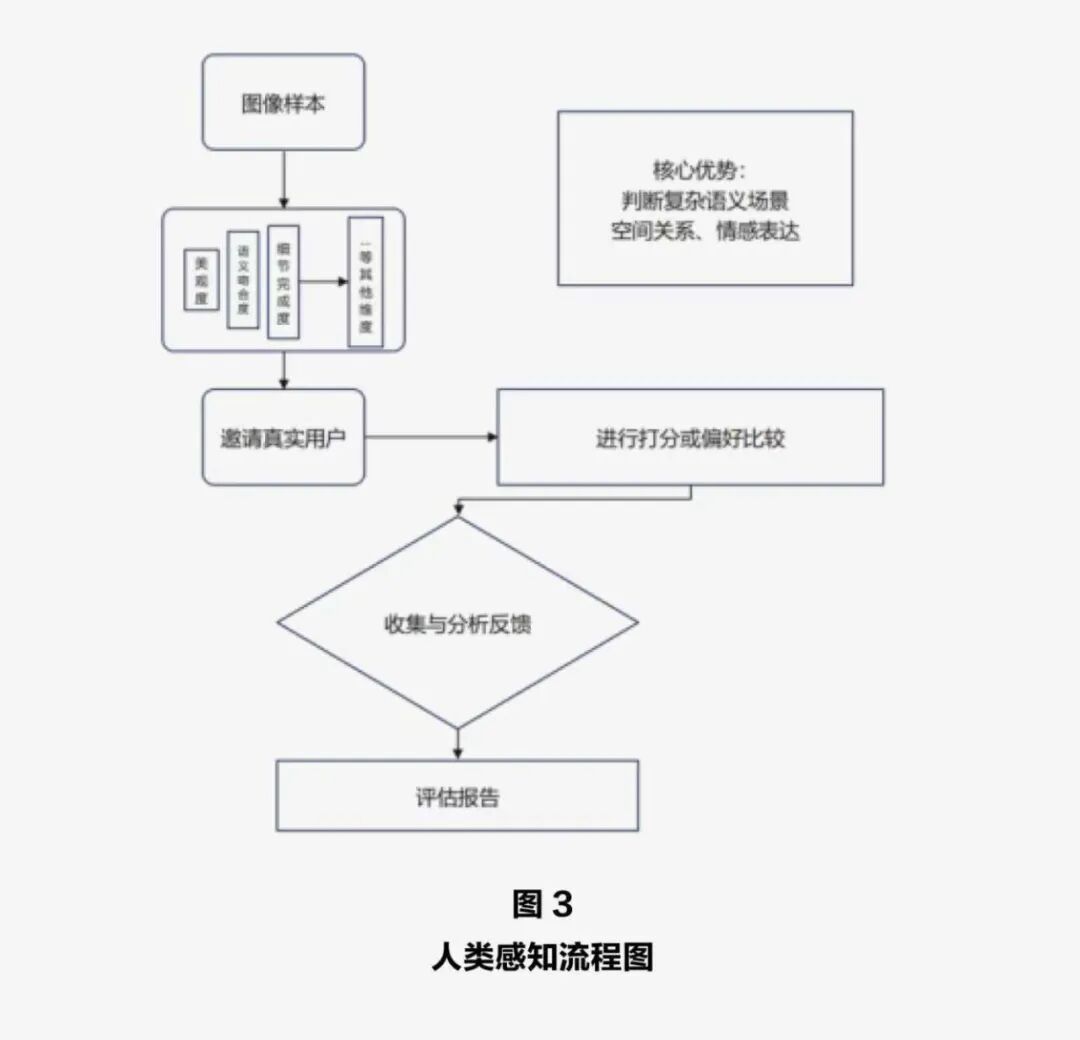
第三类方法回归到人类感知验证。人工评估始终被视作最可靠的评价手段。在这一类方法中,研究者会邀请真实用户从图像美观度、语义吻合度、细节完成度等多个维度对生成结果进行打分或偏好比较。大量实验表明,尽管自动评价指标在不断进步,但人类在判断空间关系、计数、情感表达等相对复杂的语义场景时仍然具有不可替代的优势。近年来,随着众包平台和大型评估数据集的发展,人工评估的规模和效率也在不断提升,为模型迭代提供了宝贵反馈。
尽管已有多种评估方法,但保真度的研究仍面临诸多挑战,如图像“真实性”与“艺术性”往往难以明确区分、高度专业化场景的评估需求未得到充分满足等。未来,研究人员还需开发更多具有场景适应性的评价指标,并结合人类反馈持续提升自动化评估体系的可靠性。
多样性的广度与深度:文化、语言与知识的挑战
除了“画得像”和“画得真”,文本生成图像技术还有一项关键能力——生成内容的“多样性”,即模型能否响应不同类型、风格和文化背景的文本输入,生成丰富而非重复的结果。当前主流文生图模型的多样性主要受到训练数据来源和用户群体的影响。此外,模型对复杂的文本描述,尤其是对涉及逻辑关系、低资源语言或文化特定概念等的理解能力仍显不足,这也限制了生成内容在语义层面的多样性。
在文化适应性方面,大多数新发布的多模态模型在处理某些文化细节时的表现不尽如人意。以生成传统服饰为例,大模型对非西方文化元素(如亚洲刺绣、非洲图案)的还原度明显较低,甚至会出现混淆和错误。这种偏差直接源于训练数据中文化内容的不均衡分布,例如在LAION和COCO等主流数据集中,欧美中心图像占绝大多数,导致模型对其他文化语境的理解能力较弱。

另一方面,当提示词要求模型整合多领域知识时,现有模型往往表现不佳,生成的主题插图常出现图中内容无关联、人物角色与道具严重不符的问题。这不仅揭示了模型在复杂知识推理上的短板,也反映出其生成结果在文化深度和知识准确性上的局限。
总体来看,当前文本生成图像模型在多样性方面呈现出广度初具而深度不足的特点。未来的研究需从多语言对齐机制、文化嵌入增强、知识图谱引导生成等方向重点突破,并设计能够精细衡量多样性缺陷的新一代评估基准。
安全与伦理:潜藏的风险与应对策略
从社交媒体滤镜到创意设计,从广告生成到虚拟场景构建,AI的文生图技术正以前所未有的速度融入日常生活。然而,其背后潜藏的安全漏洞、伦理困境与社会偏见也逐渐浮出水面。
这些安全和伦理漏洞主要聚焦于三大核心问题:一是大模型是否会产生暴力、色情或仇恨等有害图像;二是大模型是否会放大社会中的性别、种族与文化偏见;三是大模型是否具备真正的伦理意识。这些已不再只是技术议题,更成为影响人工智能健康发展、负责任落地的关键。
在安全机制方面,多数文生图模型仍缺乏内在的“免疫系统”。传统的“关键词黑名单”拦截效果有限,仅能识别约30%的明显有害指令,而面对同义词替换、语法改写甚至图像隐写等“越狱”手段时,防御效果大幅下降。相比之下,虽然一些基于潜在语义分析的新方法能够将识别率提升至近90%,但它们尚未成为主流模型的标准配置。更值得警惕的是,某些开源模型在面临涉及隐私信息、虚假内容生成或政治宣传图像等敏感提示时,漏洞率显著高于闭源模型。这暴露出当前安全设计多数仍停留在“后处理”阶段,而非在模型训练初期就引入价值观对齐。
偏见问题则更隐蔽,也更复杂。模型本身并没有主观恶意,但它会忠实地复刻训练数据中的现实偏差。多项大规模测试表明,模型在生成职业图像时呈现出强烈的性别刻板印象(如护士多为女性,工程师多为男性)和种族偏见(浅肤色人物占比超过70%,在高位职业中尤为突出)。此外,大模型在文化维度存在明显的西方中心主义倾向,在生成“传统婚礼”“民族服饰”等主题时,非西方文化的表现频次低且细节失真。这些偏差不仅源于训练数据样本的不均衡,也源于预训练模型语义编码中固有的歧视性关联。
在伦理层面,除了需要警惕模型生成暴力、色情内容外,更严峻的挑战在于被用于制造虚假新闻插图、科学谣言配图甚至名人“深伪”图像。评测表明,40%的恶意提示能成功绕过安全过滤机制生成违规图像,揭示了防护体系缺乏动态响应和持续迭代的能力。同时,大模型生成虚假信息的风险也引发对其事实准确性和可靠性的评测实践。除此之外,未经授权使用的高质量版权书籍被数字化后用于训练模型,构成了对创作者权益的严重侵害,凸显了知识产权保护在AI时代的紧迫性。
尽管如此,全球的研究者与机构仍在积极寻找解决方案。唯有通过技术、数据与治理的多维协同,生成式大模型才能真正迈向负责任、可信赖的未来。关于这些前沿的AI治理与评测方法,你也可以在 云栈社区 的技术讨论板块找到更多深度分析。
可解释性与人机协同:走向透明与可信的AI
从广告设计、教学插图到医疗可视化,多模态文生图大模型展现出惊人的生成能力。与此同时,人们也开始关注一个更深层的问题:这些模型是否真的“理解”了我们的指令,它们能否在复杂场景中做出合乎逻辑和伦理的决策?这些局限性表明,单靠提升生成质量已无法满足实际应用的需求,如何让人工智能的决策过程更加透明、可信,已成为当前研究的重点。
理解模型的内部运作机制是提升其可靠性的关键,为此,研究人员借鉴并改进了传统语言模型的可解释性方法。通过特征归因技术(如梯度分析和注意力可视化)观察到,模型对输入文本中不同词语的敏感程度不同,扩散模型更容易响应形容词(如“红色”“大型”),而常常忽略表达空间关系的介词(如“在……之间”“在……左侧”)。这解释了为什么生成的图像可能在颜色和风格上符合要求,却在物体布局和结构上出现偏差。此外,通过研究逆向工程分析模型的底层参数和隐变量分布发现,某些偏见问题源于隐空间中的特征分布不均。例如,在生成职业相关的图像时,模型会更频繁地激活与特定性别或种族相关的特征,导致生成结果缺乏多样性。这些发现为模型优化、减少偏见指明了方向。
可解释性不仅关乎技术透明度,更直接影响人机协作的效率。当用户能够理解模型的决策依据时,其使用体验和任务表现均会显著提升。比如,在医疗影像分析场景中,提供热力图解释能够帮助医生更好地理解人工智能的生成建议;在创意设计领域,解释功能可以帮助用户更高效地调整提示词。另一项由斯坦福大学团队提出的Holistic Evaluation of Text-to-Image Models(HEIM)评测框架则进一步扩展了评测维度,除了传统的图像-文本对齐度和图像质量之外,还引入了美学价值、原创性、推理能力、知识准确性、偏见、毒性、公平性、鲁棒性、多语言支持与效率等12个维度,并强调在主观维度上人类评判的不可替代性。研究显示,自动化指标与人类评价之间的相关性较弱,如美学评分相关系数仅为0.39,说明纯技术指标无法完全捕捉人类对图像的复杂感知。
文生图多模态大模型评测往往存在着“算法厌恶”和“过度依赖”的争议。人机协同的提出,恰好在这两者之间找到平衡。通过提供直观的解释,AI从不可理解的权威转变为一个可以被质疑、验证和协作的“伙伴”。人类专家可以借助解释信息,将大模型的输出与自身领域知识进行对比,从而实现情境化决策。这种协作模式不仅提升了任务表现,还增强了人类对AI的信任感。
尽管已经取得显著进展,多模态文生图模型的可解释性与交互体验研究仍面临建立跨模态统一解释标准、使评测基准更贴近真实动态任务、平衡解释深度与实用性的挑战。
构建可信、可靠、可协同的多模态未来
多模态文生图大模型的评测,已不再仅仅是技术性能的比拼,更是一场关于如何构建可信、可靠、可协作人工智能系统的深刻探索。从生成质量到安全伦理,从算法透明到人机协同,每一个维度的进步都意味着我们在迈向与人类价值观深度契合的人工智能新阶段。

当前的研究表明,唯有将自动化评估与人类判断深度融合,将技术优化与价值对齐同步推进,才能真正释放多模态大模型的潜力,使其成为增强人类创造力、理解力和判断力的伙伴,而非替代品。未来的道路仍充满挑战,但也充满希望,在技术创新与人文思考的交汇处,构建一个更具包容、公平与智慧的人机共融新生态。
 发表于 2026-4-16 16:45:31
|
查看: 122|
回复: 0
发表于 2026-4-16 16:45:31
|
查看: 122|
回复: 0
