在AI快速渗透企业核心业务的过程中,一个被忽视但正在快速放大的安全问题正在显现:模型网关正在成为AI系统中最脆弱、最容易被利用的攻击入口之一。
最新一项研究显示,在大量的第三方模型网关中,已经出现真实的恶意行为与数据窃取事件:
- 付费模型网关中约3.6%存在异常或恶意行为
- 免费模型网关中约2%直接注入恶意代码
- API Key、云凭证、系统提示词等敏感信息在网关层被完整暴露
缺乏安全审计、缺乏访问隔离、缺乏合规约束的模型网关,已构成企业数据观测、内容篡改与凭证窃取的重要安全风险。
研究数据来源:引用自安全研究论文《Your Agent Is Mine》(arXiv:2604.08407),由Hanzhi Liu等研究人员于2026年4月发布。
大模型供应链安全:被忽视的AI网关风险
大多数第三方模型网关并非简单转发请求,而是会终止TLS连接并以明文形式处理完整的请求与响应数据。这意味着,API Key、系统提示词、工具定义、执行指令乃至返回结果,都会在网关侧被完整暴露。
问题的关键在于,这些网关往往由个人或小规模团队搭建,缺乏合规资质与安全审计机制,其本质更接近于一个没有任何安全约束的应用层代理。一旦模型网关被恶意控制或本身就是恶意服务,它就能:
- 篡改内容:在工具调用中替换发送或返回中的URL、依赖包、执行脚本等
- 窃取密钥:可以窃取在与模型通信交互过程中无意泄漏的钱包助记词、私钥、API密钥等
这一威胁与传统提示注入完全正交——攻击发生在模型推理循环之下的回调层,现有的大部分提示词防护无法抵挡。
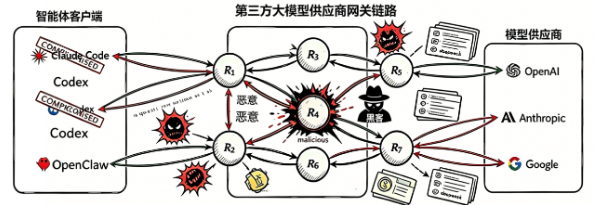
1. 攻击类型与成因分析
普遍情况下,攻击者通常先进行被动密钥窃取,收集敏感凭据,再根据场景选择载荷注入或依赖注入执行恶意操作。
下表总结了四大攻击类型的核心特征与危害等级:

2. 风险场景与实验数据
研究团队从公开渠道获取了428个第三方模型网关API(包括付费和免费),在其中放置真实的API密钥和云凭证,观察并记录攻击者的行为。
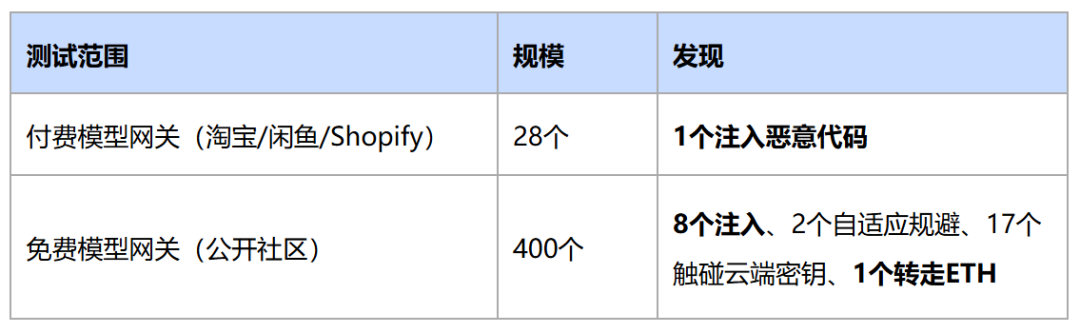
3. 企业内部面临的风险
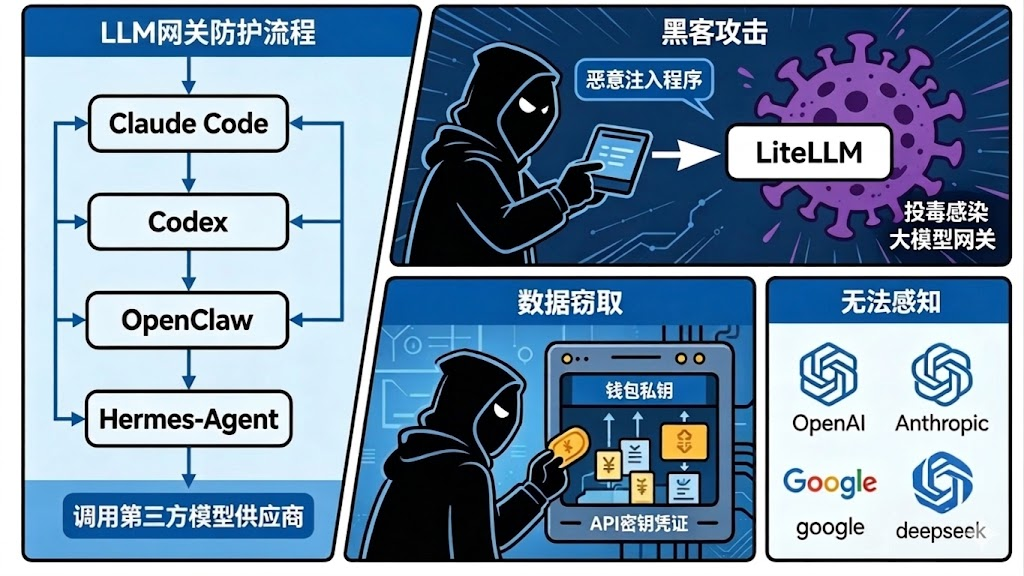
企业内部使用大模型的典型场景:
- 研发团队使用Claude Code、Codex等工具辅助编程
- 运营团队使用OpenClaw、Hermes Agent等智能体工具自动化处理客户请求
- 数据团队通过模型网关API调用大模型进行数据分析
攻击者通过未经审计、无资质监管的模型网关静默窃取API Key、云凭证等敏感信息,或篡改工具调用注入恶意代码。恶意内容进入企业内网后落地执行,凭据被用于横向移动,最终导致数据泄漏、资产损失或合规违规。上述整个过程员工完全无感知,往往在收到巨额账单或发现异常时才察觉。

真实案例:
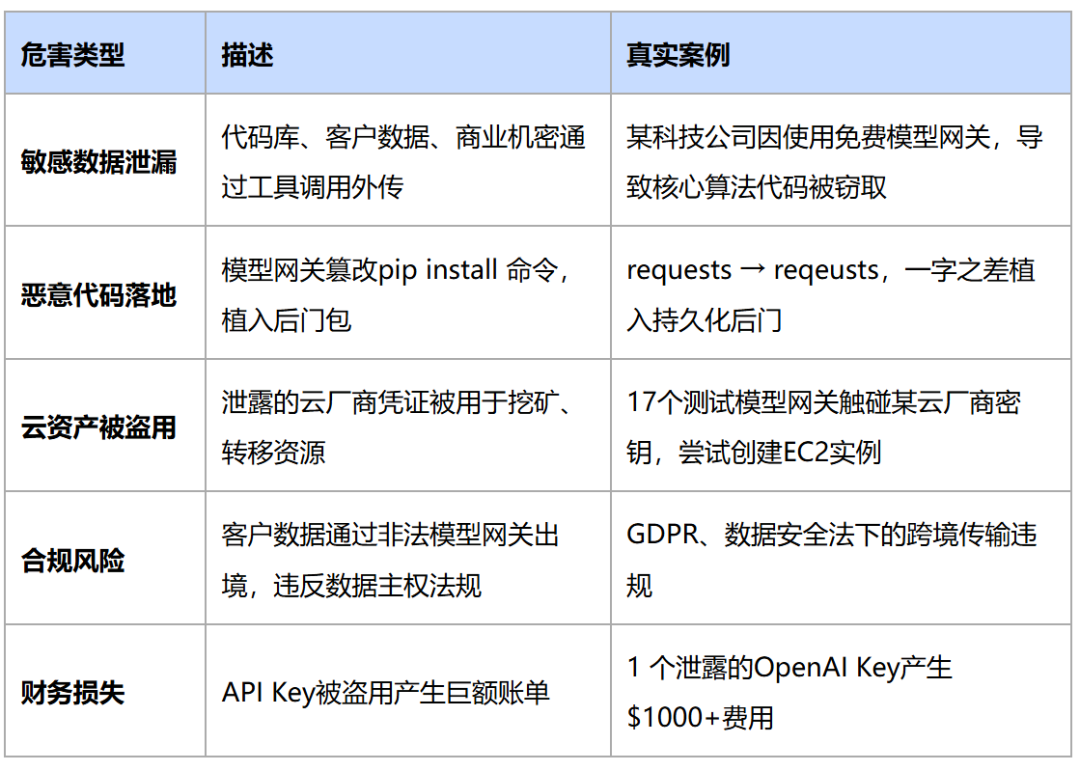
4. 如何构建“失陷可控”的AI安全防护体系
在这一挑战下,企业需要的是建立在合规与基础设施之上的长期可信保障。大量缺乏审计与监管的第三方模型网关构成了巨大的供应链安全风险。
一个有效的防护体系应从系统架构层面出发,构建一套以“限制风险影响范围”为核心的安全边界,确保即便攻击发生,也无法突破既定边界。
- 在凭证安全层面,通过最小权限原则对API Key进行精细化控制,并结合预算上限与自动熔断机制,对每一个凭证的调用能力进行严格约束,避免因密钥泄露带来的无限制资源消耗问题。
- 在访问控制层面,通过将API Key绑定至指定网络来源,有效阻断了凭证在外部环境中的非法复用路径,使其从“通用凭证”转变为“受控资源”。
- 在执行安全层面,提供基于Agent Sandbox的隔离运行环境,将所有模型生成代码与工具调用行为限制在独立沙箱之中,通过对文件系统、网络访问及运行时生命周期的全面控制,确保即便恶意载荷进入执行阶段,也无法接触真实业务系统或实现持久化扩散。
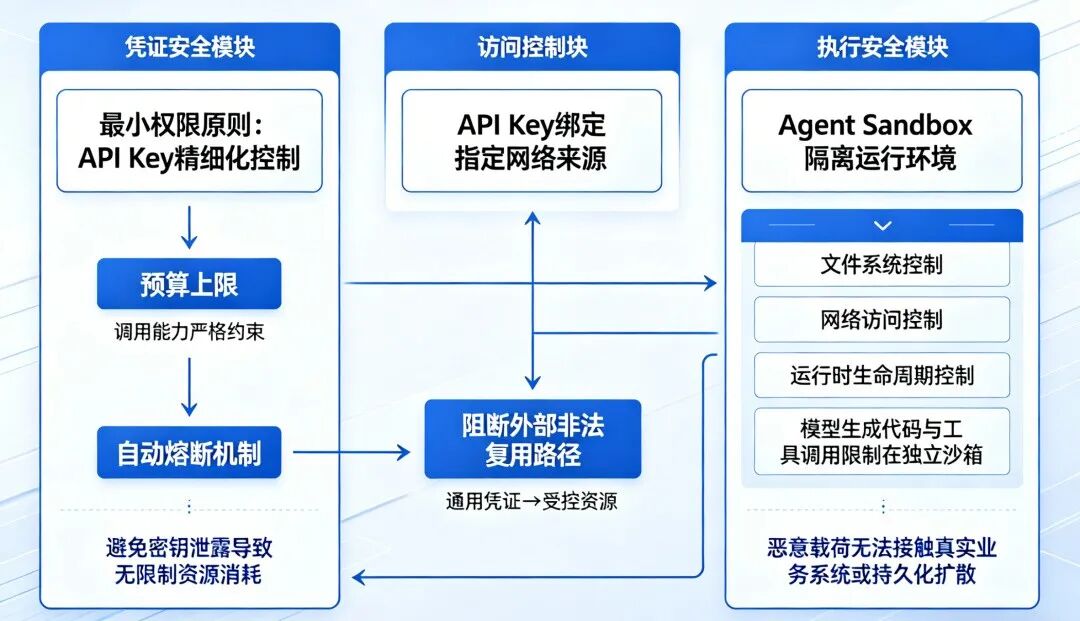
通过在凭证、访问与执行三个关键环节建立安全边界,可以将原本难以感知、难以防御的模型网关供应链风险,转化为可约束、可隔离、可管理的系统性风险,从而帮助企业在复杂多变的AI应用环境中,依然能够保持对安全的掌控能力。
在大模型与智能体加速融入核心业务的今天,供应链安全已经不再是边缘问题,而是直接关系到企业数据资产与业务稳定性的基础能力。面向未来的答案在于:在不可完全信任的AI世界中,构建一个可控的AI安全边界。
对AI安全、大模型应用落地有更多想法的朋友,欢迎来云栈社区的技术论坛板块一起交流探讨。 |  发表于 2026-4-16 22:43:30
|
查看: 136|
回复: 0
发表于 2026-4-16 22:43:30
|
查看: 136|
回复: 0
