分库分表是构建高 QPS 系统的必经之路,但“分成多少张表”这个看似简单的数字背后,却藏着不少工程上的权衡与陷阱。分少了性能撑不住,分多了运维变噩梦。本文将从工程实践出发,聊聊如何在“够用”与“可扩展”之间找到那个最优解。
一张表“撑不住”的那个晚上
你可能听过这样的故事:一个电商团队的订单系统上线三年,数据量从百万级悄然涨到了 8 亿行。平时看似风平浪静,直到一个大促的预热夜晚,DBA 值班群弹出告警:主库 CPU 飙到 95%,慢查询堆积上千条,平均响应时间从 3ms 暴涨至 800ms。运维紧急扩了两台从库分流读请求,才勉强撑过那个夜晚。
第二天复盘,DBA 打开慢查询日志,发现大部分慢查询并不复杂,就是普通的按用户 ID 查订单。但单表 8 亿行,即使走了索引,B+ 树的层级也从 3 层涨到了 4 层,每次查询额外多了一次磁盘 IO。更要命的是,表太大导致索引本身也占了好几个 GB,Buffer Pool 无法容纳全部索引页,命中率从 99% 骤降至 85%。
结论很清晰:单表数据量已超过合理阈值,这不是简单加硬件能解决的问题,必须进行分表。
那么问题来了:分成多少张?16张、64张、256张,还是1024张、4096张?这个数字的选择,直接决定了未来几年数据库的运维难度和整个系统的扩展能力。
为什么分表数量如此关键?
很多团队第一次做分表时,往往会凭感觉拍一个“看起来差不多”的数字。16张够吗?先分64张留点余量?或者一步到位分1024张?
这绝不是一个可以随意决定的数字。分表数量一旦确定,后续想要调整的代价极高,因为它涉及全量数据迁移、路由规则重写、上下游系统的联动改造。分表数量本质上是一个容量规划决策,选少了几年后要面临痛苦的二次拆分,选多了则会让日常运维和跨表查询的复杂度大幅上升。
分表数量的影响面大致可以从三个维度来看:
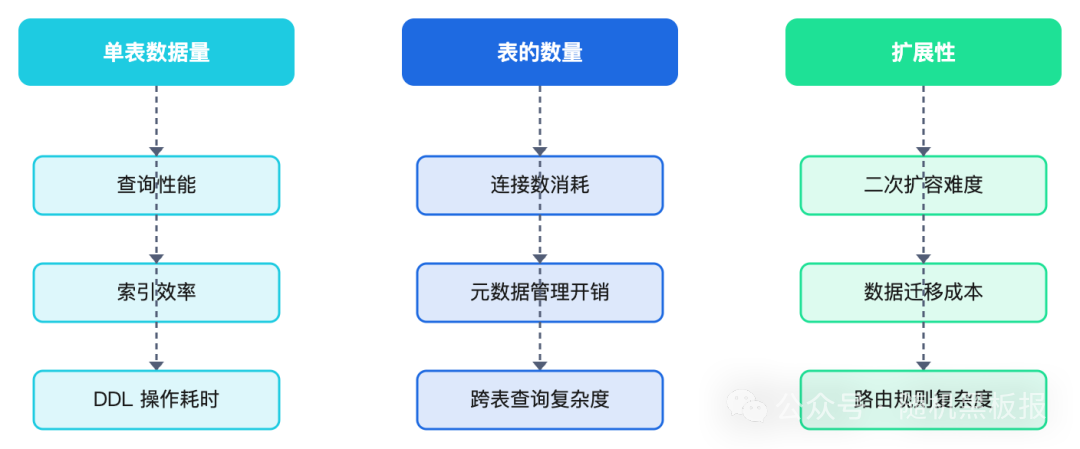
分少了,单表数据量依然庞大,性能问题未能根治;分多了,表数量爆炸,连接池管理、元数据缓存、DDL变更都会变成运维噩梦。这是一个需要在“当前够用”和“未来可扩展”之间精准平衡的工程决策。
单表数据量的“甜蜜区间”
在讨论分多少张表之前,我们先明确一个更基本的问题:单表多大算“合理”?
不同数据库引擎特性不同,但对于最常用的 MySQL InnoDB 存储引擎,业界积累了丰富的经验数据:

这些数字并非绝对,它与行的宽度(每行字节数)、索引数量、查询模式都密切相关。一张只有3个字段的窄表,5000万行可能毫无压力;而一张有50个字段、平均行长2KB的宽表,1000万行就可能开始吃力。
但有一个经验值被广泛认可:对于典型的在线业务表,将单表数据量控制在500万到2000万行之间,是性能与运维成本的最佳平衡点。
这个区间的优势在于:
- B+ 树高度稳定在3层,主键查询仅需3次磁盘IO(实际上根节点和部分中间节点常驻内存,通常只有1~2次)。
- 索引大小可以大部分甚至全部放进 Buffer Pool,命中率能维持在99%以上。
ALTER TABLE 加列、加索引等DDL操作耗时在可接受范围内。- 备份和恢复的粒度适中,出问题时影响面可控。
分表数量的计算方法
知道了单表的合理大小,分表数量的计算就变成了一道除法题:
分表数量 = 预估总数据量 / 单表目标数据量
但这道题里有几个变量需要仔细斟酌。
1. 预估总数据量
这里看的不是当前数据量,而是要预估未来3-5年的增长。业务增长本身难以精确预测,因此通常会在预估值上乘以一个2-3倍的安全系数。
举个例子:一个订单系统,当前日均新增50万笔订单,业务规划显示3年后日均会涨到200万笔。那么3年累计订单量大约是:
- 保守估计:200万 x 365天 x 3年 = 21.9亿
- 乘以安全系数2倍:约44亿
2. 单表目标数据量
结合前文分析,选择1000万行作为单表目标是一个比较稳妥的选择。如果表结构较窄(行长小于200字节),可以放宽到2000万;如果表较宽或索引较多,则应收紧到500万。
3. 对齐到2的幂次
计算出的原始数字几乎不会是2的幂次,但分表数量强烈建议对齐到2的幂次(如16, 32, 64, 128, 256, 512, 1024, 2048, 4096)。原因有二:
- 哈希取模性能:最常用的分表路由方式是
hash(sharding_key) % table_count。当 table_count 是2的幂次时,取模运算可优化为位运算 & (table_count - 1),在高QPS场景下性能收益明显。
- 扩容友好性:从256张表扩到512张,每张旧表的数据恰好拆成两份,迁移逻辑简单明了。若从300张扩到600张,数据拆分映射关系则复杂得多。
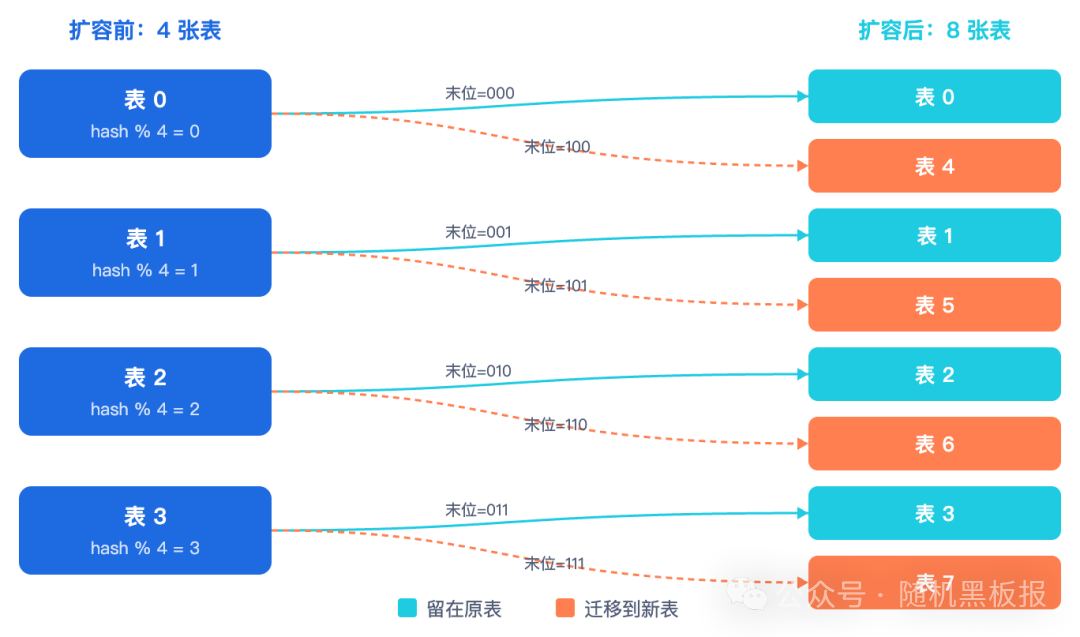
回到刚才的例子:44亿总量 ÷ 1000万单表 = 440张表。向上对齐到2的幂次,应选择 512张。
4. 考虑分库因素
分表往往与分库协同进行。如果计划分到4个数据库实例上,那么每个实例承载128张表,总计512张,这在运维上是一个比较均衡的配置。
常见的分库分表组合参考:

分库数决定了写入的并行度上限,每库表数决定了单库的管理复杂度。两者的乘积就是总表数,它直接决定了系统的数据容量上限。
分表太少:性能的天花板
理解了计算方法,我们来看看如果分少了会怎样。
设想一个社交平台的消息表,起初预估日活500万,于是分了64张表。两年后日活暴增至3000万,消息量激增,单表数据量从800万行涨到了6000万行。此时,一系列问题开始浮现:
1. 查询变慢
B+ 树从3层变为4层,每次主键查询多一次IO。看似只多了一次磁盘读取,但在高并发场景下,这额外的IO会显著消耗磁盘IOPS。当IOPS接近磁盘物理上限时,所有查询都会排队等待,延迟呈指数级上升。
2. DDL变更困难
给一张6000万行的表添加字段或索引,即使使用 pt-online-schema-change 这类在线工具,也可能需要数小时。期间会产生额外的写入负载,若碰上业务高峰,可能不得不中断操作,等待凌晨低峰期。
3. 热点数据问题加剧
64张表意味着热点用户的数据更容易集中在少数几张表上。如果某个大V用户的互动量是普通用户的千百倍,那么与他分在同一张表的其他用户都会受到牵连,体验“池鱼之殃”。
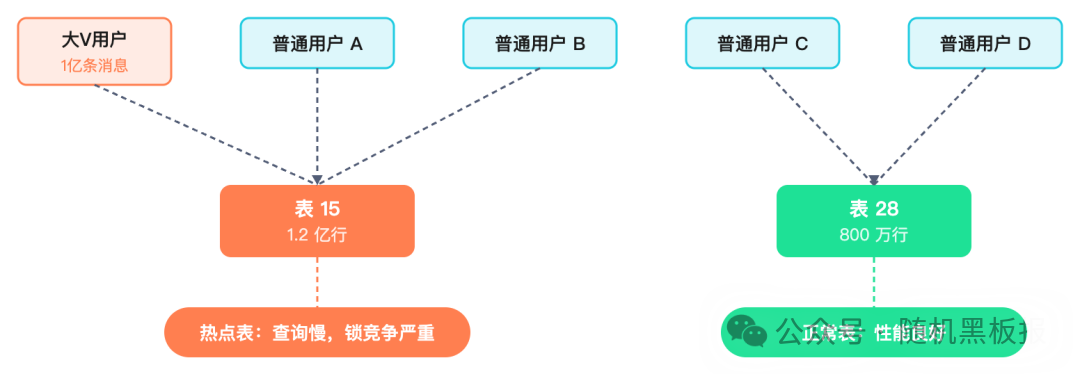
分表太少最令人头疼的是:二次拆分的成本远高于一开始就分够。因为数据已按旧路由规则分布,重新分布意味着全量数据迁移,且业务还不能停。
分表太多:运维的噩梦
既然分少了问题这么多,那一步到位分它4096张不就一劳永逸了?事情没这么简单。分表数量过多会带来另一个方向的痛苦。
1. 连接数爆炸
虽然单个连接不绑定特定表,但在分库场景中,每个分库实例需要独立的连接池。如果分了16个库,每个应用节点对每个库维持最少10个连接,光连接数就要160个。若应用集群有50个节点,数据库侧要承受8000个连接,这对数据库的内存和线程调度都是巨大压力。
2. 元数据膨胀
MySQL 的 information_schema 需要维护每张表的元数据。4096张表意味着4096份表结构、索引信息和统计信息。每次执行 SHOW TABLES、SHOW TABLE STATUS 或ORM框架启动时的元数据加载,都会变得异常缓慢。
3. 跨表查询成本激增
业务上很多查询并非按分表键进行。例如订单表按用户ID分表,但运营需要按时间范围查询最近7天的订单统计。这种查询需要扫描所有分表再进行聚合。表越多,这类查询越慢,消耗的资源也越大。
4. DDL变更的总耗时惊人
虽然单表DDL变快了(因为每张表小了),但DDL的总次数变成了4096次。给4096张表都加一个字段,即使每张表只要10秒,串行执行也需要超过11个小时。并行执行虽能加速,但会对数据库造成巨大的负载冲击。
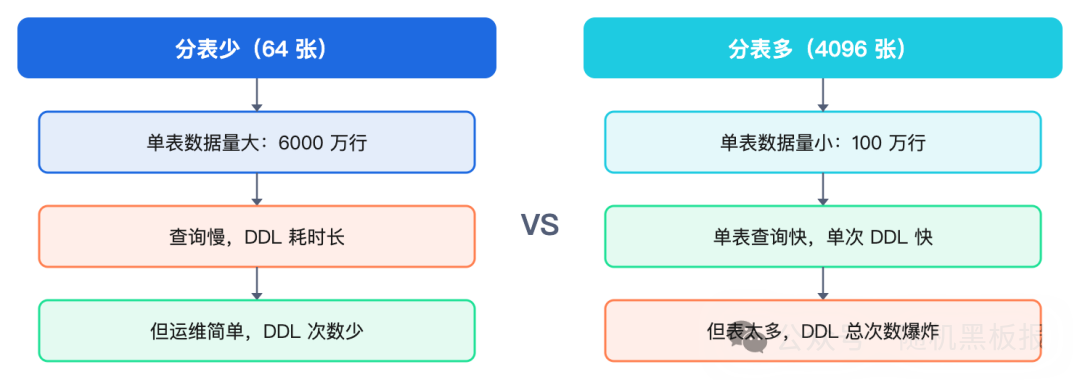
分表数量的选择绝非越多越好,核心是要找到查询性能与运维成本之间的那个最优解。
不同业务规模下的分表策略
聊完了两个极端,我们来看看在不同的业务规模下,分表数量的选择有何不同考量。
十万 QPS 级别:开始考虑分表
此阶段数据量通常在几亿到十几亿。系统可能已做了读写分离,但写入压力开始让单表不堪重负。
- 典型配置:2-4个库,每库8-16张表,总计16~64张表。
- 阶段重点:不在于分多少张,而在于选对分表键。分表键选错,后续调整事倍功半。常见选择:
- 订单表:用户ID(保证同一用户订单在同一表,查询效率高)。
- 交易流水:交易ID或时间戳(保证写入均匀分布)。
- 用户表:用户ID(天然均匀分布)。
百万 QPS 级别:分表成为标配
数据量达几十亿到百亿级别,多个核心表都需要分表。
- 典型配置:4-8个库,每库32-128张表,总计128~1024张表。
- 进阶需求:
- 全局唯一ID:自增ID在分表后不再全局唯一,需引入分布式ID生成器(如Snowflake、Leaf)。
- 分布式事务:跨表更新需保证事务性,要么使用两阶段提交等方案,要么通过业务设计规避跨表事务。
- 数据聚合:需建设离线或准实时宽表/索引表,以支持非分表键维度的查询。
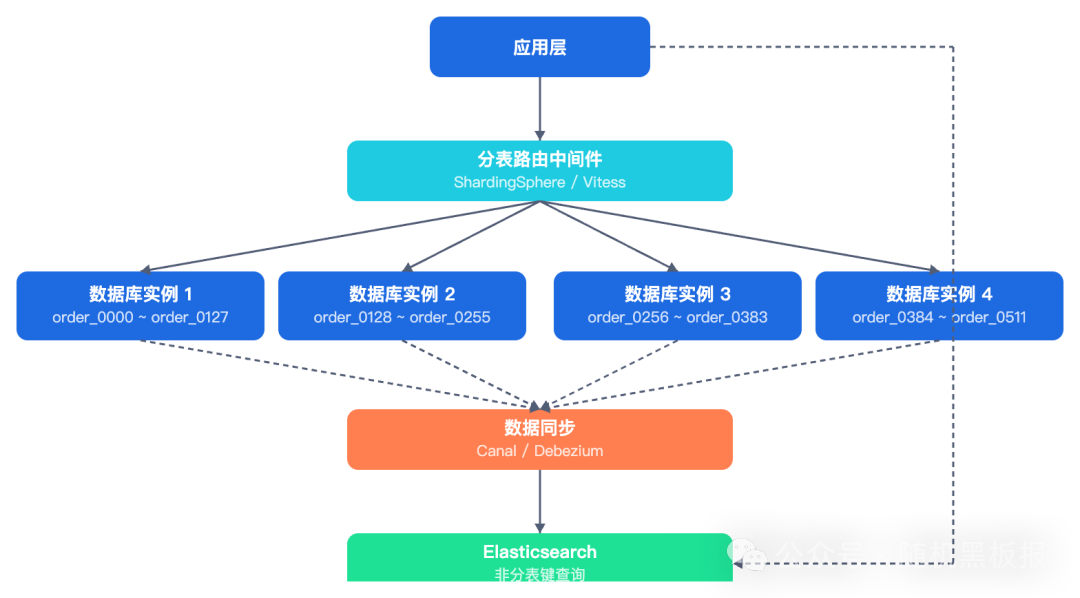
千万 QPS 级别:分表数量进入千级
数据量达百亿到千亿级别,分表数量动辄上千。
- 典型配置:8-32个库,每库128-512张表,总计1024~4096张表。
- 核心挑战:此时分表本身已非最大挑战,围绕分表衍生的一系列工程问题才是真正考验。

千万 QPS 级别的分表,核心不在于“分多少”,而在于围绕分表构建的自动化运维体系与数据治理能力。
二次扩容:最怕的事还是会发生
无论初期规划多么周密,业务增长总有可能超出预期。二次扩容,即增加分表数量,是分库分表架构中最复杂、风险最高的操作之一。
1. 翻倍扩容:最简单的方案
如果分表数量是2的幂次,翻倍扩容的数据迁移逻辑最简单:每张旧表的数据按照新的取模规则,恰好一半留在原表,一半迁移到新表。

2. 一致性哈希:更优雅但复杂的方式
传统的取模方案在扩容时需要迁移大量数据。一致性哈希可以将影响范围缩小到只有新增节点附近的数据。但它在数据库分表场景中不如在缓存中普及,因为数据库更强调确定性路由,且分表扩容频率较低,翻倍扩容的简单性更具实操价值。
3. 预分表:用空间换时间
还有一种策略是“预分表”:一开始就建好足够多的表(如4096张),但只使用其中一部分数据库实例。扩容时无需改变分表数量,只需将部分表从旧实例迁移到新实例。
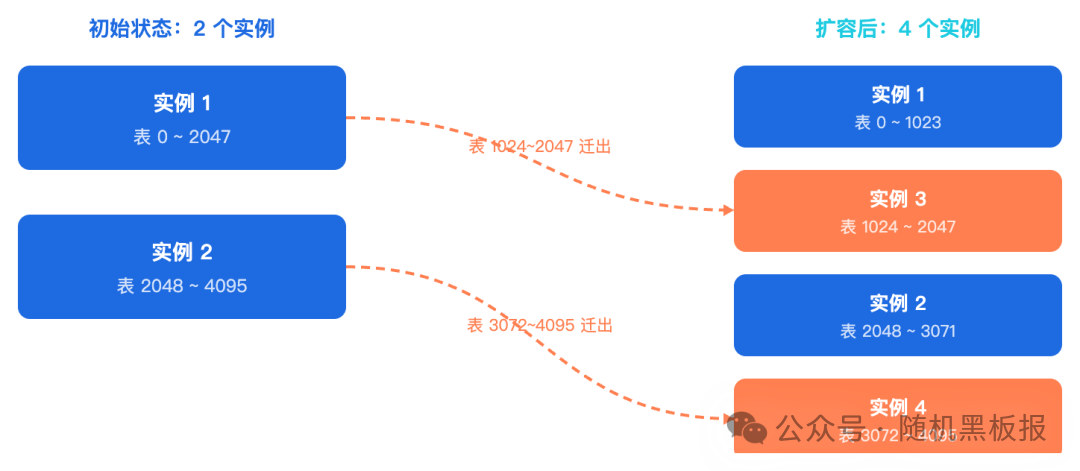
这种方案的优势在于:分表规则始终不变,扩容只是“搬表”而非“拆表”,数据迁移逻辑简单,风险更小。代价是一开始就要维护大量空表,元数据管理和日常运维有额外开销。但相较于二次拆分的巨大风险,这个代价通常是值得的。
分表之外:何时该考虑换赛道
聊了这么多分表策略,最后需要明确:分表不是万能药。当分表数量已达数千张仍觉不够时,可能需要重新审视,是否该换一种思路。
1. 冷热分离
大量数据是低频查询的历史数据。与其占用宝贵的 MySQL 资源,不如将超过一定时间(如6个月)的数据迁移至HBase、TiDB或对象存储。让分表只管热数据,压力自然减小。
2. NewSQL 数据库
TiDB、CockroachDB、OceanBase 这类 NewSQL 数据库,从底层就支持自动分片和在线扩容,无需应用层做分表路由。如果团队有能力驾驭,在特定场景下可彻底告别手工分表的繁琐。
3. CQRS 架构
将写入与查询彻底分离。写入走MySQL分表保证事务性,查询则交给 Elasticsearch、ClickHouse 等专门的查询引擎。分表只需解决写入性能,查询复杂度交由更擅长的系统处理。
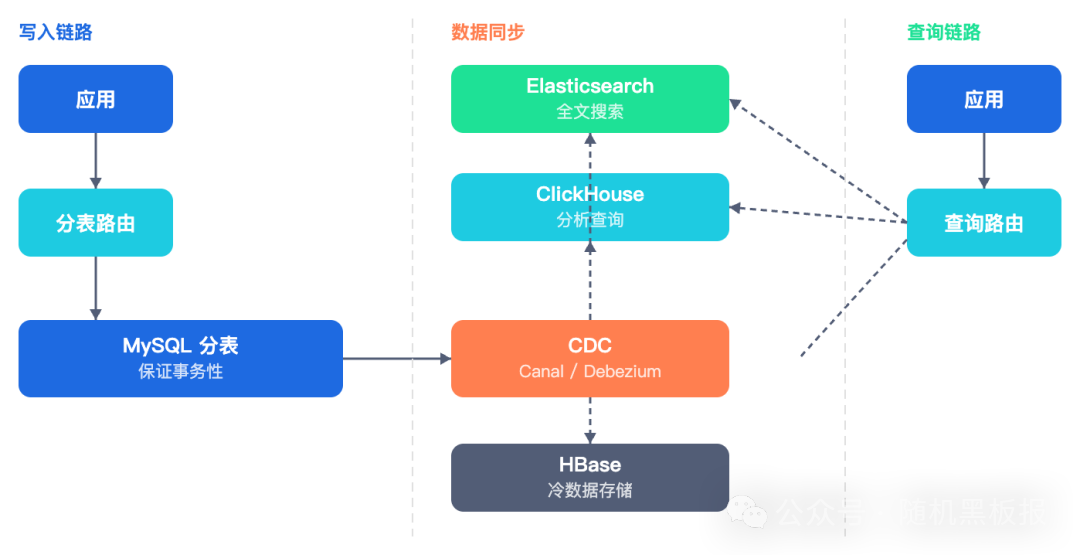
分表解决的是单一存储引擎的容量瓶颈,但当数据量和查询复杂度同时爆炸式增长时,异构存储结合CQRS架构,才是支撑千万QPS系统的终局形态之一。
容量规划不是算术题
回顾全文,分表数量的选择看似是一道简单的除法,实则是综合了业务增长预判、数据库引擎特性、运维能力、扩容策略等多个维度的系统工程决策。
几条核心原则值得牢记:
- 单表数据量控制在500万到2000万行,这是MySQL InnoDB的性能甜蜜区间。
- 分表数量对齐到2的幂次,为未来扩容铺平道路。
- 预估数据量要看3~5年,并乘以2~3倍的安全系数。
- 宁可多分一档,不要少分,因为二次拆分的成本远高于多维护一些空表。
- 分表只是手段,不是目的,当分表数量过多时,要及时考虑冷热分离、NewSQL、CQRS等替代方案。
从十万QPS到百万QPS,分表是从可选到必选的演进;从百万QPS到千万QPS,分表数量从几十增长到几千,而围绕分表构建的、坚实的自动化运维体系与架构视野,才是真正的护城河。分表这件事,技术上不复杂,但决策上必须慎之又慎。你当初选定的那个数字,很可能要陪伴系统走过接下来的许多年。
如果你对这类高并发架构的实战经验感兴趣,欢迎在技术社区进行更深入的交流与探讨,例如在 云栈社区 与同行们分享你的见解与困惑。
 发表于 2026-4-18 00:34:36
|
查看: 168|
回复: 0
发表于 2026-4-18 00:34:36
|
查看: 168|
回复: 0
