在嵌入式 Linux 开发中,我们经常面对这样的场景:产品在测试时偶发卡顿,通过 top 或 htop 观察,发现 CPU 利用率瞬间飙到 99%,但平均负载(Load Average)却只有 0.8(单核设备)。此时,我们应该判定为 CPU 瓶颈,还是忽略这个瞬间波动?
要回答这个问题,必须深入内核统计机制,理解这两个指标背后的“物理含义”。
1. 两个指标的内核统计逻辑
1.1 CPU 利用率:基于时间的采样快照
CPU 利用率在内核中通过 /proc/stat 计算得出。内核维护每个 CPU 核心在不同状态(user、system、nice、idle、iowait、irq、softirq)下的累计滴答数(jiffies)。
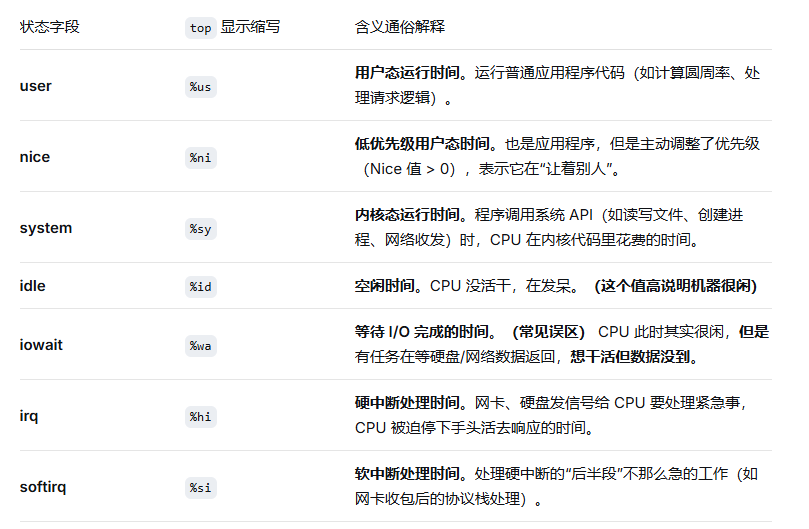
用户态工具通过两次采样间隔内的差值除以总时间,得到瞬时利用率。
- 特点:反映的是采样窗口期(通常几秒)内 CPU 执行指令与非空闲时间的比例。
- 陷阱:如果采样窗口是 2 秒,某一毫秒内任务切换极其繁忙,而其余 1.999 秒空闲,显示出来的利用率可能是 0%。
1.2 平均负载:运行队列与等待队列的压力指数
平均负载(Load Average)显示在 uptime 或 top 第一行。
$ uptime
14:30:25 up 5 days, 3:20, 2 users, load average: 0.08, 0.03, 0.01
内核通过 avenrun 数组计算过去 1、5、15 分钟的指数加权移动平均值。
其核心统计对象不仅仅是正在使用 CPU 的任务,而是包含处于以下两种状态的进程数之和:
- TASK_RUNNING:正在 CPU 上运行或正在运行队列排队等待 CPU 的任务。
- TASK_UNINTERRUPTIBLE:处于不可中断睡眠状态(D 状态)的任务,通常是在等待 I/O(磁盘、网络、外设)。
- 物理含义:如果负载为 1.0,在单核系统上意味着平均有一个任务在使用 CPU 或排队等待 CPU。
- 关键区别:它包含了 I/O 阻塞 的任务。
所以当你看到 load average: 2.5, 1.8, 1.2 时:
- 如果 CPU 使用率 100%,说明是 CPU 不够。
- 如果 CPU 使用率 20%,说明大概率是磁盘/网络 I/O 在拖慢系统。

2. 单核与双核场景下的数值
| 场景 |
CPU 利用率 |
平均负载 (1min) |
判断结论 |
| 场景 A:瞬间毛刺 |
1.2% (平均值) |
0.15 |
一切正常,瞬间中断或软中断处理属于正常调度行为。 |
| 场景 B:死循环 |
100% (单核) |
1.00 |
CPU 瓶颈,有进程占满计算资源。 |
| 场景 C:阻塞在 NAND Flash |
5% |
3.50 |
I/O 瓶颈,进程在 D 状态等待存储设备响应,CPU 空闲但系统响应极慢。 |
| 场景 D:双核满负荷 |
200% (Top显示) |
2.00 |
多核均衡负载,系统计算资源饱和。 |
3. “瞬间高利用率”别慌?
嵌入式系统(特别是无 MMU 或实时性要求高的系统)具有中断驱动的特性。以下几种情况会导致采样窗口内利用率看似很高,但平均负载极低,此时只需关注平均负载即可判定系统健康:
- 定时器中断收敛(Timer Tick Coalescing):内核高精度定时器可能在某个 tick 瞬间集中触发软中断处理函数,导致瞬时 us/sy 极高,但随后 CPU 进入
WFI(Wait For Interrupt)低功耗状态。
- DMA 完成后的清理工作:网络数据包到达引发 IRQ,内核在软中断中处理协议栈,处理时间可能只有 200us,但对
top 的采样周期影响被放大。
- 调度器负载均衡:多核系统中,调度器 tick 会检查是否需要迁移任务,此过程短暂占用 CPU。
结论:如果 Load Average < CPU 核心数,即便 top 显示偶尔 99%,系统调度延迟也不会显著增加。
4. 平均负载高,CPU 却空闲
这是嵌入式 Linux 最经典的误导陷阱。请观察以下 top 输出:
top - 14:05:32 up 2 days, 3:15, 2 users, load average: 4.50, 4.20, 3.90
Tasks: 125 total, 1 running, 124 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.0 us, 1.5 sy, 0.0 ni, 95.0 id, 1.5 wa, 0.0 hi, 0.0 si, 0.0 st
现象:CPU 95% 空闲(idle),但 1 分钟平均负载高达 4.5。
根因:某个用户态进程(例如读取损坏的 eMMC 分区的 logcat 或 dd)处于 D 状态(Disk Sleep)。
后果:虽然 CPU 闲着,但由于平均负载过高,内核调度器在判断系统繁忙时会增加调度延迟,并且 systemd 或 watchdog 可能因负载过高而误判系统 hang 住。
嵌入式调试命令:
# 查看谁在 D 状态导致负载虚高
ps aux | awk '$8=="D" {print $0}'
# 或使用更直接的负载分析工具
cat /proc/loadavg && cat /proc/stat | grep procs_running
5. 单核与双核的实战阈值建议
针对资源受限的嵌入式 Linux 设备,建议设置如下监控告警阈值(基于系统稳定运行经验值):
| 指标 |
单核设备 (如 i.MX6UL) |
双核设备 (如 Zynq-7000) |
处理动作 |
| CPU 利用率报警 |
> 85% 持续 30秒 |
> 180% (总核数*90%) |
排查死循环或计算密集型任务。 |
| 平均负载报警 |
> 0.7 (70% 水位线) |
> 1.5 |
排查 D 状态进程或高优先级 RT 线程饥饿。 |
| iowait 报警 |
> 10% |
> 10% |
优化存储驱动、减少 sync 频率、使用内存文件系统。 |
6. 结语:看谁?
对于嵌入式 Linux 开发者,平均负载是衡量系统健康度的“慢变量”,CPU 利用率是衡量计算密度的“快变量”。
- 日常巡检看平均负载:它反映了用户感知的整体响应延迟。
- 性能调优看 CPU 利用率:它反映了代码执行热点。
特别提醒:在单核设备上,如果 Load Average 超过 1.0 且持续增加,说明存在任务积压;而在双核设备上,Load Average 超过 2.0 才意味着计算资源真正饱和。记住:Load Average 高于 CPU 核心数,才意味着有人在排队。
希望这篇对嵌入式 Linux内核 性能监控核心指标的解析能对你有所帮助。如果你想深入学习更多系统底层知识,欢迎到 云栈社区 的网络/系统板块,与更多开发者交流讨论。
 发表于 2026-4-18 01:10:07
|
查看: 181|
回复: 0
发表于 2026-4-18 01:10:07
|
查看: 181|
回复: 0
