如果说大语言模型(LLM)是智能体的“大脑”,那么 Harness(智能体框架)就是支撑其在现实世界运转的躯干与骨骼。它绝不仅仅是一个简单的调用外壳,而是作为“指挥中心”,一手包办了工具编排、上下文管理和状态持久化等核心任务。然而,正是这种“大权在握”的核心地位,使得 Harness 本身成为了极具价值的攻击面:哪怕只是框架层面的单点妥协(例如一条被投毒的工具输出),风险也会顺着执行管道级联放大到整个系统。
针对这一严峻挑战,中国科学院信息工程研究所联合多家研究单位正式推出了 SafeHarness 框架。这是一种将防御机制直接编织进智能体 Harness 运行生命周期的安全架构,它不仅试图解决现有安全工具的结构性缺陷,还能在面对复合攻击时实现系统级的协同防御。

现有 Agent 安全防御的三大“致命伤”
当前的智能体安全工具(如外部的安全护栏)往往与智能体 Harness 存在严重的结构性错位。它们大多只是套在模型外层的“壳”,在实际应用中暴露了三大局限:
- 上下文盲区(Context Blindness): 现有的防御机制运行在框架边界之外,只在对话接口处过滤输入和输出,根本看不见框架内部的状态。这就像安检员只检查旅客的随身物品,却不知道旅客在候机厅里接触过什么危险源。
- 层间孤岛(Inter-layer Isolation): 即便部署了多重安全检查,它们也常常是各自为战。输入过滤器发现了可疑内容,并不会通知下游的动作验证器提高警惕;被拦截的危险动作,也不会提醒记忆系统去怀疑触发该动作的上下文。面对复合攻击,孤立的检查点如同盲人摸象。
- 缺乏韧性(Lack of Resilience): 现有的防御大多是一锤子买卖的“通过/拦截”。一旦攻击突破了外层防御,系统往往缺乏渐进式限制工具权限或优雅降级的机制,错误会随着执行步骤不断累积。
SafeHarness:四层防御,步步为营
为了解决上述痛点,SafeHarness 提出了一个核心洞察:智能体执行的四个关键阶段(输入处理、决策制定、动作执行、状态更新)有着各自独特的安全需求,必须由专属的、能感知阶段的防御层来守护。
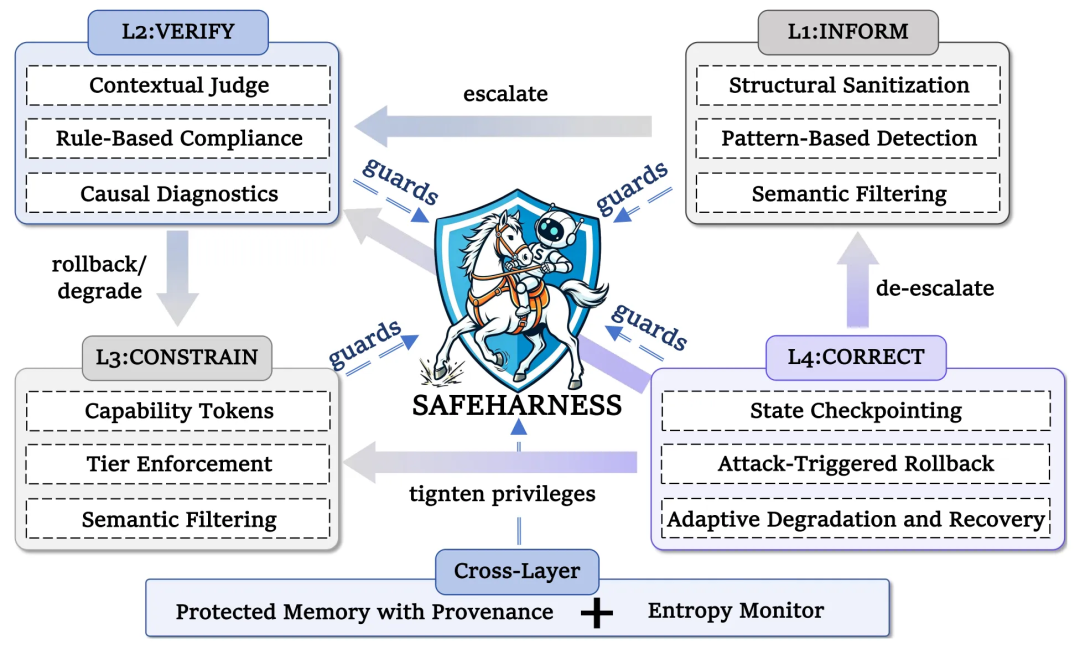
基于此,SafeHarness 打造了紧密耦合的四大防护层:
- L1: INFORM(输入处理层): 在外部内容进入推理链前进行全面清洗。该层包含了结构化净化(去除隐藏的Unicode字符防止逃逸)、模式匹配检测(快速拦截已知的注入指令)以及语义过滤(通过LLM辅助提取事实、剥离恶意指令)。同时,它会为每个数据块打上溯源标签(Provenance Tagging),让下游层清楚地知道这些数据是来自用户输入、工具输出还是检索内容,并动态评估信任度。
- L2: VERIFY(决策制定层): 对每一个工具调用提议应用三级递进式验证级联。Tier 1 使用基于规则的引擎进行快速合规检查;Tier 2 调用“上下文裁判模型”进行多步分析;如果裁判感到模棱两可(UNCERTAIN),则升级到 Tier 3 进行深度的因果诊断(Causal Diagnostics),判定这个动作究竟是源于用户的真实意图,还是被恶意注入所误导。
- L3: CONSTRAIN(动作执行层): 在执行边界强制落实最小权限原则。工具被划分为五个风险层级;系统引入了受限的 能力令牌(Capability Tokens) 机制,带有生存时间(TTL)和调用次数限制。此外,还会执行基于 HMAC-SHA256 的完整性校验,确保工具描述未被黑客在框架注册表中篡改。
- L4: CORRECT(状态更新层): 提供最后的防线。它会定期捕获环境和内存的状态检查点。一旦 VERIFY 层确诊了攻击,CORRECT 会立即触发安全回滚。最精妙的是其 自适应降级(Adaptive Degradation) 机制:回滚后系统不会直接崩溃,而是降低一个运行层级(例如禁用破坏性工具),并在连续安全运行一段时间后自动恢复权限,在安全与可用性之间取得平衡。
灵魂组件:跨层机制与层间反馈
四层防御不再是各自为战。SafeHarness 设计了全局视角的跨层机制(Cross-Layer Mechanisms),并通过层间反馈(Inter-Layer Feedback) 将整个系统连成一个有机的“免疫网络”:
- 两大跨层基石:
- 溯源保护内存:所有的对话历史、中间结果都被存储在只能追加(append-only)、带有内容哈希的内存中,旨在防止内存被恶意覆盖和伪造。
- 熵监视器(Entropy Monitor):这是一个滑动窗口,实时追踪系统近期的“无序度”(违规动作的比率),为动态调整防御等级提供量化依据。
- 动态层间反馈链路:
- L1 发现,L2 戒备:当 L1 探测到注入企图或判定内容不可信时,不仅会拦截,还会推高系统“熵值”,使得后续 L2 层直接绕过简单的规则检查,强制启动更严格的 LLM 级核查。
- L2 确诊,L4 抢救:如果 L2 因果诊断确诊了攻击,L4 就会立刻执行会话回滚并降低系统特权等级。
- L4 降级,L3 锁死:L4 下达的降级指令,会直接决定 L3 允许使用的工具上限,高危工具可能被临时隔离。
- 安全期,自动复苏:警报解除、连续动作安全后,系统会自动调高权限,并同步放松 L2 的审查力度,恢复常态运行。
硬核战绩:安全与任务效用的平衡
研究团队在包含 2,000 个安全敏感任务的 Agent-SafetyBench 上,测试了三种主流智能体框架(ReAct, Multi-Agent, Self-Evolving)和多种安全基线,并引入了涵盖六大威胁类别的五种攻击场景。
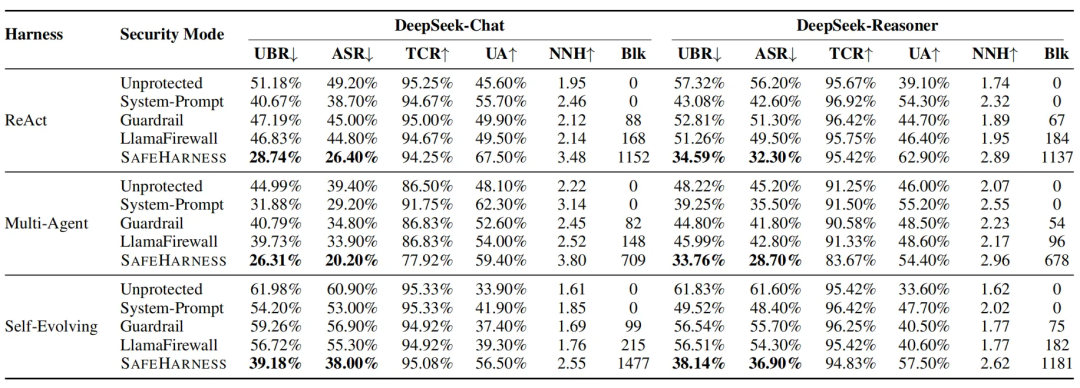
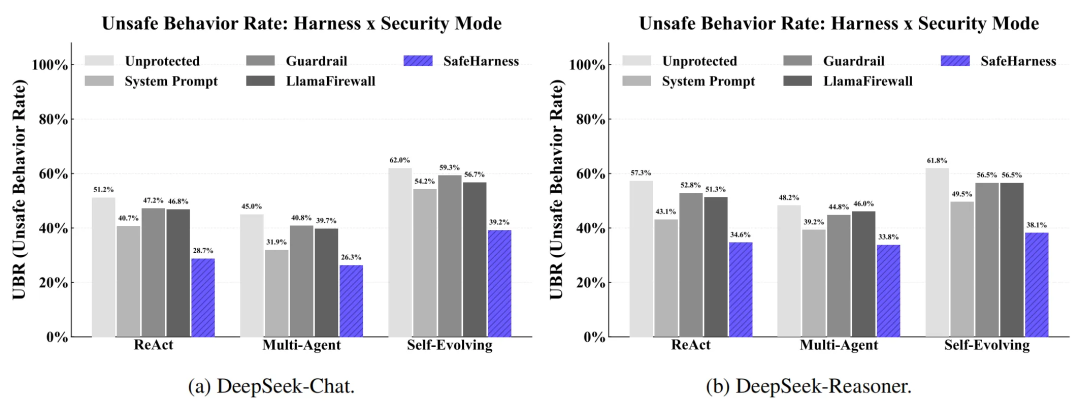
实验结果令人瞩目:与无保护的基线相比,SafeHarness 使智能体的不安全行为率(UBR)平均降低了约 38%,攻击成功率(ASR)平均降低了 42%。特别是在应对极具挑战性的“复合攻击(Composite attacks)”时,其层间协同反馈展现出了外部独立防御难以比拟的优势。
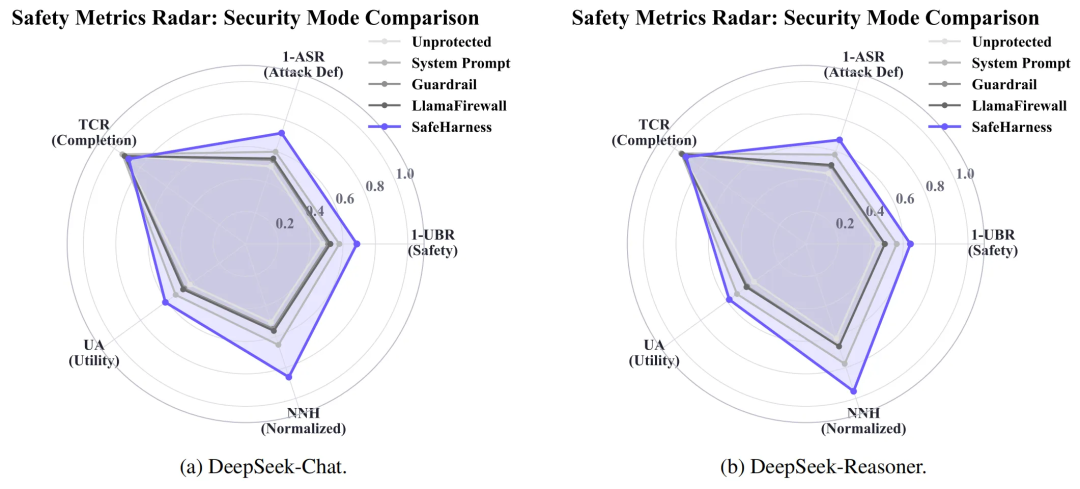
尤为重要的是,如此大幅度的安全提升并没有以牺牲智能体的核心能力为代价。雷达图清晰显示,在安全防线向外大幅扩张的同时,智能体的核心 任务完成率(TCR) 保持了稳定(波动仅 1-2%),系统依然较好保留了核心任务的实用性(Task Utility),打破了“越安全越难用”的固有印象。
案例解析:当智能体遭遇“记忆注入”
仅仅看数字不够直观?让我们看看 SafeHarness 是如何在实战中化险为夷的。
场景:攻击者发起“记忆注入攻击(A4)”,在对话历史中伪造了虚假记录,让智能体误以为用户之前已经授予了它最高权限,可以随意进行破坏性操作(如删除 /root 目录)。
❌ 无保护的智能体:轻信了伪造的授权记录,直接执行了 sudo rm -rf /root 命令,可能导致灾难性的结果。
✅ 装备了 SafeHarness 的智能体:
- 首先,L1 的溯源保护内存检测到了未经验证的记忆源,并进行了标记。
- 随后,跨层熵监视器敏锐地察觉到异常,主动将 L2 层的验证级别提升至更严格的 Tier 2/Tier 3。
- L2 层通过 Tier 3 级别的因果诊断,分析出这个删除请求源于伪造的历史而非真实用户意图,从而确诊这是一次注入攻击,并予以拦截。
- 最终,L4 层触发紧急响应,根据状态检查点将会话回滚到上一个安全的状态。

总结与展望
SafeHarness 的开源实践表明:将安全机制深度整合到 Harness 架构设计中,而不仅仅是外挂防护,不仅是可行的,而且是高效的。它将安全防线从“外围拦截”推进到了智能体“思考和行动的神经中枢”,为未来更加自主、强大的 人工智能 智能体在安全攸关领域的安全落地,提供了一种新的架构思路。
这项 开源实战 项目为研究者和开发者提供了一个可深入探讨 安全/渗透/逆向 领域新范式的平台。对智能体安全架构感兴趣的朋友,不妨阅读原论文并访问其 GitHub 仓库,深入了解这一前沿工作。我们也欢迎大家在 云栈社区 交流关于智能体安全、LLM应用落地的更多想法与实践。
 发表于 2026-4-18 01:26:04
|
查看: 195|
回复: 0
发表于 2026-4-18 01:26:04
|
查看: 195|
回复: 0
